






Apache YARN(Yet Another Resource Negotiator)是一个HADOOP集群资源管理系统。YARN在HADOOP2
中引入,但是它足够通用,也支持其它的分布式计算程序。
YARN提供了用于请求和使用集群资源的API,但是这些API不是直接由用户代码使用的。用户写更高级的由
分布式计算框架提供的API,这些框架是建立在YARN之上的,对用户隐藏了资源管理的细节。这个情况如图4-1
所示,它显示了一些作为YARN应用的分布式计算框架(MapReduce,Spark等等),运行在集群计算层(YARN)
和集群存储层(HDFS及HBase)之上。

同时也有一个应用建立在图4-1所示的框架之上,Pig、Hive、Crunch都是运行在MapReduce、Spark或Tez(或
包括所有这三个)上,并且不直接与YARN交互。
本章看一下YARN的特性并提供理解接下来的第四部分的基础,包括HADOOP分布式处理框架。
YARN应用运行分析
YARN通过一直运行的后台来提供它的核心服务----resource manager(每个集群一个)用来管理集群资源的
使用,及node manager,运行在集群的所有节点上,用来运行及监视container。container使用一组限定的资源
(内存、CPU等等)来执行面向应用的程序。container可能是一个UNIX process或是一个LINUX cgroup,这取决
于YARN是如何配置的(见300页“YARN“)。图4-2显示了YARN如何运行一个应用。
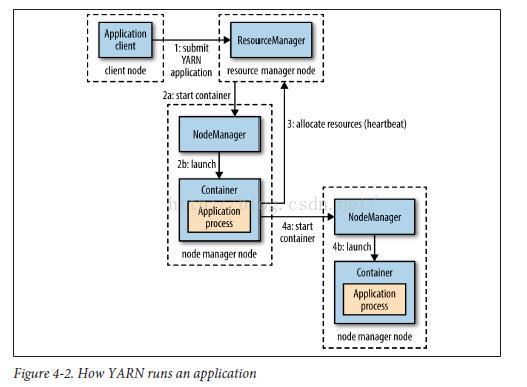
为了在YARN上运行应用,客户端联系resource manager让它运行应用主程序(图4-2第一步)。resource manager
找到一个可以启动一个container来运行这个应用主程序的node manager(第2a和2b步)。应用主程序运行后要干什么取
决于具体应用。它可能只是简单的在它运行的container中运行一个计算然后返回结果给客户端。或者它会从resource manager
请求更多的container(第三步),并使用它们运行一个分布式计算(第4a和4b)。剩下的就是MapReduce YARN应用所要
做的了,我们将在第185页“MapReduce Job运行解析“中详细讨论。
注意在图4-2中,YARN自己并不提供应用各部分(客户端、服务器、进程)交互的途径。大部分YARN应用使用一些
形式的远程交互(如HADOOP RPC)来传递状态更新和结果返回,但是这些都是特定于具体应用的。
请求资源
YARN请求资源方式很灵活。请求一组container可以表示每一个container需要的计算机资源(内存、CPU),
也可以在请求中约束哪些位置container可用。
位置是保证高效使用集群带宽来处理分布式数据的临界点(请参考前文“扩大规模”及“网络拓扑与HADOOP),所以YARN
允许应用对它请求的container添加位置约束。位置约束可以用来请求特定的node或rack,或集群的任意位置(off-rack)。
有些时候位置约束不能满足,在这种情况下,要么没有分配,要 么放松约束。例如,如果请求一个节点,但是它无法启动
它的container(因为其它的container在它上面运行),这个时候YARN尽量找到同一个rack的node来启动一个container,如果
这也做不到,就在集群中随意找一个node。
通常情况下,启动一个container来处理HDFS block(即运行一个MapReduce map task)时,应用会请求一个container,
这个container对应的node保存了这个block副本的三个node中的一个,或是保存了这个副本的node对应的rack上的一个node,
如果都没有的话,就取集群中任意一个node。
YARN应用在运行时可以在任意时间请求资源。例如,应用可以预先请求所有需要的资源,或者,它可以使用更动态的方式,
通过动态请求更多资源来满足应用不断改变的需求。
SPARK使用第一种方式,启动一定数量的executor(见571页“YARN上的SPARK”)。另一方面,MapReduce有两个阶段:
map task container预先请求,但reduce task container不会启动直到map task运行后。同时,如果任何一个task失败,会请
求额外的container来重新运行这个失败的task。
应用程序生命周期
YARN应用的生命可能是非常不同的:从只有几秒的短命应用,也有运行几天甚至几个月的长期运行的应用。我们不关注应用
运行了多久。根据应用如何来映射user job来把应用分组是有用的。最简单的情况是每一个user job一个应用,这就是MapReduce
task采用的方式。
第二种模式是每一个工作流或用户会话(也许不相关)一个应用。这种方式比第一种更高效,因为不同job复用container,并且
可以在job之间缓存中间数据。SPARK使用这种模式。
第三种模式是长期运行应用,由不同用户共享。这种应用通常扮演协调人的角色。例如,APACHE Slider有一个长时运行的应用
主程序用来启动集群中的其它应用。Impala也使用这种方式来提供一个代理应用,Impala后台程序与它交互来请求集群资源。始终
运行的应用主程序意味着对用户查询的反馈低延迟,因为它避免了开启一个新应用主程序的开销。
建立一个YARN应用
从头写一个YARN应用涉及到很多方面,但是在很多情况下这是不需要这样做的,因为经常可以使用一个已经存在的应用。例如,
如果你想运行一个有向非循环(DAG)的job,那么Spark或Tez是适合的;或是流处理,那么可以使用Spark,Samza或Storm。
有几个项目来简化建立YARN应用。前面讲到的Apache Slider,可以把已经存在的分布式应用运行在YARN上。用户可以在集群上
运行它们自己的应用实例(例如HBase),与其它用户独立,它意味着不同的用户可以运行同一个应用的不同版本。Slider可以控制
应用运行的node的数量,并且可以暂停然后继续运行一个运行中的应用。
Apache Twill与Slider类似,但是它提供了一个简单的应用程序模型来在YARN上开发分布式应用。Twill允许你定义一个集群进程
把它解释为一个JAVA Runnable的扩展,然后在集群的YARN container中运行它们。Twill也提供了实时日志及命令消息。
当所有这些选项都不满足的时候----例如应用有复杂的调度需求----这时YARN项目自己提供的distributed shell做为一个如何写YARN
应用的例子。它展示了如何使用YARN客户端API来处理客户端或应用 主程序与YARN后台之间的交互。
YARN与MapReduce 1比较
HADOOP早期版本(1及之前)的MapReduce的分布式实现被称为“MapReduce 1“以与MapReduce 2(使用YARN)区分。
在MapReduce 1中,有两种后台进程来控制job执行程序:一个jobtracker及一个或多个tasktracker。jobtracker通过tasktracker
上的任务调度来协调所有系统的job。tasktracker运行task并发送进程报告给jobtracker,这个报告保存了每一个job所有的处理记录。
如果一个task失败,jobtracker可以把它生排到另一个tasktracker上。
在MapReduce 1中,jobtracker既调度job(匹配task与tasktracker),又监视task进程(持续跟踪task,重启失败的或慢的task,
记录task)。相对来说,在YARN中,这些职责由不同的实体来处理:resource manager和一个application master(每个mapreduce
job一个)。jobtracker也负责存储已完成job的历史,也可以单独运行 job history server来减轻jobtracker的负担。在YARN中,对应角色
是timeline server,它存储application history(HADOOP2.5.1中,timeline server不存储mapreduce job history,所以还是需要
mapreduce job history server)。
YARN中与tasktracker对应的是node manager。对应关系如表4-1所示。

YARN的设计针对MapReduce 1的局限性。使用YARN的好处包含以下几点:
可扩展性
YARN可以运行在比MapReduce 1更大的集群上。MapReduce 1的可扩展瓶颈是大约4000个node和4000个task,源于这样一个
事实,jobtracker必须同时管理job和task 。YARN通过它的resource manager/application master架构克服了这些局限,它可以扩展
至10000个node和100000个task。
和jobtracker比较起来,每一个应用的实例----这里是一个mapreduce job----有一个对应的application master,它在应用的整个
生命周期运行。这个模式很接近原始的GOOGLE MapReduce paper,它描述了一个master进程如何协调运行在一组worker上的map和
reduce task。
可用性
High availability (HA)通常是在一个service daemon失败时,通过复制需要的状态给另一个daemon以让它可以接管这个工作。
然而,大量的快速的改变复杂的状态(例如几秒更新一次task status)使把HA更新到jobtracker service很困难。
在YARN中通过把jobtracker的职责拆分成resource manager和application master,使HA service变成一个分而治之的问题:
提供resource manager的HA,再提供application的。事实上,HADOOP 2对resource manager和application master HA全部支持。
193页“Failures“将详细讨论YARN中的错误恢复。
利用率
在mapreduce 1中,每一个tasktracker都配置了一个静态的固定大小的slot,在配置时它又被分成map slot和reduce slot。map slot
只能用来运行map task,reduce slot只能用来运行reduce task。
在YARN中,一个node manager管理一些资源,而不是一个固定数量的指定的slot。在map reduce 1中,可能发生一个reduce task
必须等待因为在集群上只有map slot可用,而运行在YARN上的map reduce不会发生这种情况。如果运行这个任务的资源可用,那么这个
应用就适用于它。
此外,YARN的资源是细粒度的,所以应用可以请求任何它需要的资源,而不是一个不可拆分的slot,它对于特定的task来说可能太大
(这样会浪费资源)或是太小(这样会导致错误)。
某种程度上说,YARN的最大好处是把HADOOP开放给其它类型的分布式应用。mapreduce只是YARN诸多应用中的一个。
用户甚至可以在同一个YARN集群上运行不同版本的mapreduce,它使mapreduce的升级过程更可控(注意,尽管如此,mapreduce
的一些部分,例如job history server和shuffle handler及YARN,还是需要升级)。
因为HADOOP 2已经广泛使用并且是最新的稳定版本,在本书的其它地方,mapreduce就是指mapreduce 2,除非另作说明。第七
章详细查看如何在YARN上运行MapReduce。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









