






 本文介绍了如何通过配置Oracle GoldenGate (OGG) 和 Datapump 实现数据复制。主要步骤包括设置源端和目标端的Manager进程、Extract进程组、Datapump Extract进程组以及目标端的Replicat进程组等。
本文介绍了如何通过配置Oracle GoldenGate (OGG) 和 Datapump 实现数据复制。主要步骤包括设置源端和目标端的Manager进程、Extract进程组、Datapump Extract进程组以及目标端的Replicat进程组等。
友情提示:笔者英语很渣,阅读时建议保持极强的耐心,同时欢迎提出各种意见~~
本篇是摘取自Oracle GoldenGate官方文档(administrator’s guide)的第四章节Using Oracle GoldenGate for live reporting。
粗糙的译文:
创建配置一个在源端有data pump的Oracle GoldenGate(OGG)
注释:这个配置是一般通常用的形式,还有其他的各种配置形式,具体可以查看官方文档Oracle Goldengate的《administrator’s Guide》其中的第四章节。
你可以在源端添加一个data pump使Extract与TCP/IP隔离开,去灵活的存储,可以不用考虑Extract的过滤和转换处理。
在这个配置当中,Extract进程写入到源端的Trail文件中,本地的data pump进程读取了这个Trail文件然后传送给了目标端系统,让目标端的Replicat进程来读取这个Trail文件。
data pump不是必须配置的功能,但它可以让OGG提高性能和具有容错性。
下图就是一个具有data pump功能的单向复制配置示意图。
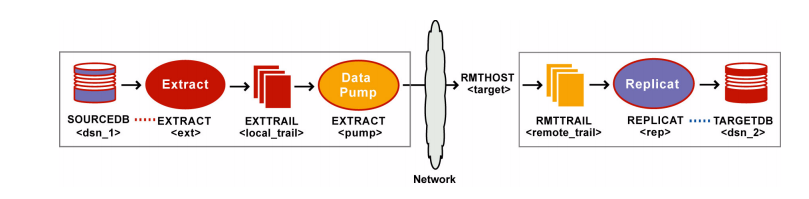
源端系统
配置Manager(mgr)进程
1.在源端,配置mgr进程可以参考上一篇blog《OGG_Manager 进程》
2.在这个mgr参数文件中,可以使用PURGEOLDEXTRACTS参数控制本地Trail文件的清空工作。
配置Extract进程组
3.在源端,使用ADD EXTRACT命令去创建一个Extract进程组,在这文档中这个组的名称用ext代替。
ADD EXTRACT <ext>, TRANLOG, BEGIN <time> [, THREADS <n>]
❍使用TRANLOG关键字,表示数据的来源是源端的redo数据。
4.在源端,使用ADD EXTTRAIL命令创建一个本地的Trail文件。Extract进程写入这个Trail文件中,然后data-pump进程读取这个Trail文件。
ADD EXTTRAIL <local_trail>, EXTRACT <ext>
❍用Extract去联系Trail文件和Extract进程组,Extract进程写入到Trail文件中,data-pump Extract进程读取Trail文件。
5.在源端,使用EDIT PARAMS命令可以创建一个Extract组的参数文件,包括应用到你数据库环境的参数。
– 定义Extract组:
EXTRACT <ext>
– 数据库登录的信息:
[SOURCEDB <dsn_1>,][USERID <user>[, PASSWORD <pw>]]
– 指定写入到本地的哪个Trail文件中:
EXTTRAIL <local_trail>
– 指定要捕获的表:
TABLE <owner>.<table>;
配置data pump Extract进程组
6.在源端,使用ADD EXTRACT命令去创建一个data pump组,在这文档中这个组的名称用pump代替。
ADD EXTRACT <pump>, EXTTRAILSOURCE <local_trail>, BEGIN <time>
❍使用EXTTRAILSOURCE参数来指定一个本地的Trail文件。
7. 在源端,使用ADD RMTTRAIL命令去指定一个传送到目标端系统的Trail文件。
ADD RMTTRAIL <remote_trail>, EXTRACT <pump>
❍使用EXTRACT来连接data pump组,数据写到这个Trail文件中。
8. 在源端,使用EDIT PARAMS可以创建一个data pump的参数文件,包括应用到你数据库环境的参数。
– 定义data pump组:
EXTRACT <pump>
–数据库登录的信息:
[SOURCEDB <dsn_1>,][USERID <user>[, PASSWORD <pw>]]
– 指定目标端系统的IP地址:
RMTHOST <target>, MGRPORT <portnumber>
– 指定目标端系统的Trail文件:
RMTTRAIL <remote_trail>
– 是否原样的映射,过滤,转换或者传输数据(注释:PASSTHRU选项适用于data pump传输配置)
[PASSTHRU | NOPASSTHRU]
–指定要捕获的表:
TABLE <owner>.<table>;
注释:其实源端的Extract进程和 data pump进程都是属于Extract进程的,不过Extract进程是捕获redo数据然后写入到Trail文件中,data pump Extract进程是读取这个Trail文件然后传送到目标端系统中的。
目标端系统
配置mgr进程
9.在源端,配置mgr进程可以参考上一篇blog《OGG_Manager 进程》
10.在这个mgr参数文件中,可以使用PURGEOLDEXTRACTS参数控制本地Trail文件的清空工作。
配置Replicat进程组
11.在目标端,创建一个Replicat checkpoint table(用来存放在目标端checkpoints的记录的)。
12.在目标端,使用ADD REPLICAT命令可以创建一个Replicat组,在这文档中这个组的名称用rep代替。
ADD REPLICAT <rep>, EXTTRAIL <remote_trail>, BEGIN <time>
❍用EXTTRAIL去连接Replicat组的Trail文件。
13.在目标端,使用EDIT PARAMS去创建一个Replicat组的参数文件,包括应用到你数据库环境的参数。
– 定义Replicat组:
REPLICAT <rep>
– 源端和目标端的结构是否一致(注释:ASSUMETARGETDEFS适用于一致的时候):
SOURCEDEFS <full_pathname> | ASSUMETARGETDEFS
–数据库登录的信息:
[TARGETDB <dsn_2>,] [USERID <user id>[, PASSWORD <pw>]]
– 指定错误规则:
REPERROR (<error>, <response>)
– 指定传送来的表:
MAP <owner>.<table>, TARGET <owner>.<table>[, DEF <template name>];
精美的原文:
Creating a reporting configuration with a data pump on the source system
You can add a data pump on the source system to isolate the primary Extract from TCP/IP functions, to add storage flexibility, and to offload the overhead of filtering and conversion processing from the primary Extract.
In this configuration, the primary Extract writes to a local trail on the source system. A local data pump reads that trail and moves the data to a remote trail on the target system, which is read by Replicat.
You can, but are not required to, use a data pump to improve the performance and fault tolerance of Oracle GoldenGate.
Refer to Figure 9 for a visual representation of the objects you will be creating.
Figure 9 Configuration elements for replicating to one target with a data pump
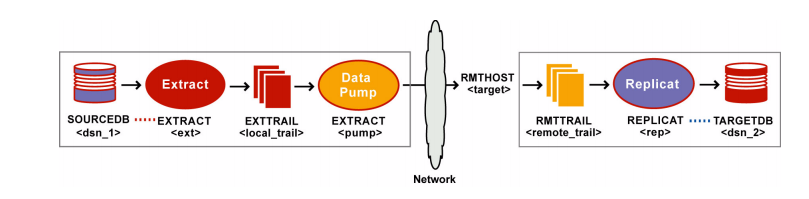
Source system
To configure the Manager process
- On the source, configure the Manager process according to the instructions in Chapter 2.
- In the Manager parameter file, use the PURGEOLDEXTRACTS parameter to control the purging of files from the local trail.
To configure the primary Extract group
3. On the source, use the ADD EXTRACT command to create a primary Extract group. For documentation purposes, this group is called ext.
ADD EXTRACT <ext>, TRANLOG, BEGIN <time> [, THREADS <n>]
❍ Use TRANLOG as the data source option. For DB2 on Z/OS, specify the bootstrap data set (BSDS) name following TRANLOG.
4. On the source, use the ADD EXTTRAIL command to create a local trail. The primary Extract writes to this trail, and the data-pump Extract reads it.
ADD EXTTRAIL <local_trail>, EXTRACT <ext>
❍ Use the EXTRACT argument to link this trail to the primary Extract group. The primary Extract group writes to this trail, and the data pump group reads it.
5. On the source, use the EDIT PARAMS command to create a parameter file for the primary
Extract group. Include the following parameters plus any others that apply to your database environment.
– Identify the Extract group:
EXTRACT <ext>
– Specify database login information as needed for the database:
[SOURCEDB <dsn_1>,][USERID <user>[, PASSWORD <pw>]]
– Specify the local trail that this Extract writes to:
EXTTRAIL <local_trail>
– Specify tables to be captured:
TABLE <owner>.<table>;
To configure the data pump Extract group
6. On the source, use the ADD EXTRACT command to create a data pump group. For documentation purposes, this group is called pump.
ADD EXTRACT <pump>, EXTTRAILSOURCE <local_trail>, BEGIN <time>
❍ Use EXTTRAILSOURCE as the data source option, and specify the name of the local trail.
7. On the source, use the ADD RMTTRAIL command to specify a remote trail that will be created on the target system.
ADD RMTTRAIL <remote_trail>, EXTRACT <pump>
❍ Use the EXTRACT argument to link the remote trail to the data pump group. The linked data pump writes to this trail.
8. On the source, use the EDIT PARAMS command to create a parameter file for the data pump. Include the following parameters plus any others that apply to your database environment.
– Identify the data pump group:
EXTRACT <pump>
– Specify database login information as needed for the database:
[SOURCEDB <dsn_1>,][USERID <user>[, PASSWORD <pw>]]
– Specify the name or IP address of the target system:
RMTHOST <target>, MGRPORT <portnumber>
– Specify the remote trail on the target system:
RMTTRAIL <remote_trail>
– Allow mapping, filtering, conversion or pass data through as-is:
[PASSTHRU | NOPASSTHRU]
– Specify tables to be captured:
TABLE <owner>.<table>;
NOTE To use PASSTHRU mode, the names of the source and target objects must be identical. No column mapping, filtering, SQLEXEC functions, transformation, or other functions that require data manipulation can be specified in the parameter file. You can combine normal processing with pass-through processing by pairing PASSTHRU and NOPASSTHRUwith different TABLE statements.
Target system
To configure the Manager process
9. On the target, configure the Manager process according to the instructions in Chapter 2.
10.In the Manager parameter file, use the PURGEOLDEXTRACTS parameter to control the purging of files from the local trail.
To configure the Replicat group
11.On the target, create a Replicat checkpoint table. For instructions, see “Creating a checkpoint table” on page 121.
12.On the target, use the ADD REPLICAT command to create a Replicat group. For documentation purposes, this group is called rep.
ADD REPLICAT <rep>, EXTTRAIL <remote_trail>, BEGIN <time>
❍ Use the EXTTRAIL argument to link the Replicat group to the remote trail.
13.On the target, use the EDIT PARAMS command to create a parameter file for the Replicat group. Include the following parameters plus any others that apply to your database environment.
– Identify the Replicat group:
REPLICAT <rep>
– State whether or not source and target definitions are identical:
SOURCEDEFS <full_pathname> | ASSUMETARGETDEFS
– Specify database login information as needed for the database:
[TARGETDB <dsn_2>,] [USERID <user id>[, PASSWORD <pw>]]
– Specify error handling rules:
REPERROR (<error>, <response>)
– Specify tables for delivery:
MAP <owner>.<table>, TARGET <owner>.<table>[, DEF <template name>];

















 1089
1089

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









