







2-Volcano架构和设计原理解读
随着容器技术的发展,越来越多的批量计算应用正在迁移到Kubernetes平台上,从早期的AI应用到大数据应用,再到近期的基因,转码,科学计算等HPC应用。在迁移过程中,高性能应用对Kubernetes平台提出了新的要求,例如 调度,网络和存储等。
Volcano针对高性能应用场景,对 Kubernetes 进行了大量的加强,成功在AI,大数据和基因等多个高性能应用领域落地;同时,也将这些经验以开源项目的形式公开,回馈社区。
架构解读
Volcano全景
Volcano是基于Kubernetes的高性能批量计算平台,目前支持几乎所有的主流计算框架,包括MindSpore、TensorFlow、Kubeflow、MPI、PyTorch、飞浆、Spark、HOROVOD 等。
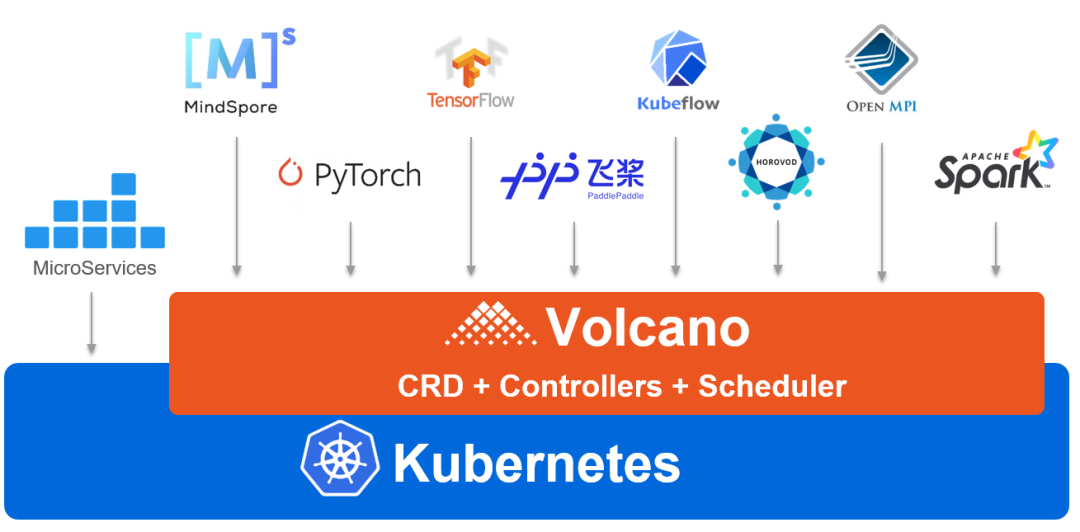
Volcano支持的部分计算框架
计算框架遇到的问题:
- 1:1的operator部署运维复杂
- 不同框架对作业管理、并行计算等要求不同
- 计算密集高,资源需求波动大,需要高级调度能力
Volcano面向主流计算框架提供:
- 统一容器基础设施,提高资源利用率
- 通用作业管理、队列Fair-share, Gang, bin-pack等高级调度算法
- 简化运维管理
Volcano整体架构
Volcano利用声明式的CRD定义我们的API,主要有3个核心的API,Volcano Job、PodGroup、Queue。
Volcano Job 是对高性能任务的通用定义,PodGroup提供了Job中Task的管理能力,Queue 为任务的分类提供了基础。
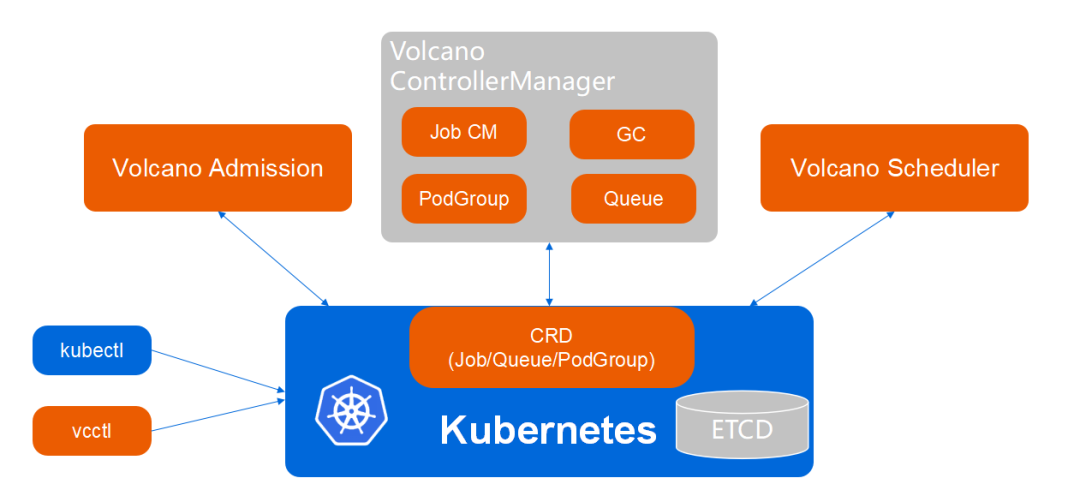
Volcano的架构
Volcano 核心组件主要包含三个:Admission、ControllerManager、Scheduler 。Admission对Volcano CRD API提供校验能力;ControllerManager负责对Volcano CRD进行资源管理;Scheduler对任务提供丰富的调度能力。
Volcano工作流程
从零开始运行Volcano作业:
1)用户创建一个 Volcano 作业
2)Volcano Admission 拦截作业的创建请求,并进行合法性校验
3)Kubernetes 持久化存储 Volcano Job 到 ETCD
4)ControllerManager 通过 List-Watch 机制观察到Job 资源的创建,创建任务(Pod)
5)Scheduler 负责任务的调度,绑定 Node
6)Kubelet Watch 到 Pod的创建,接管 Pod 的运行
7)ControllerManager 监控所有任务的运行状态,保证所有的任务在期望的状态下运行
Volcano核心概念及功能
Volcano核心概念
Queue
- Queue的概念源于 Yarn,它是Cluster 级别的资源对象,可为其声明资源配额,也可由多namespace 共享,并且提供 soft isolation
PodGroup
- PodGroup是任务的分组,它与 queue 绑定,占用队列的资源。它与 Volcano Job 是一对一的关系;也可为其声明 Scheduling 条件
Volcano Job
- 它是批量计算作业的定义,支持定义作业所属队列、生命周期策略、所包含的任务模板以及持久卷等信息
作业管理插件
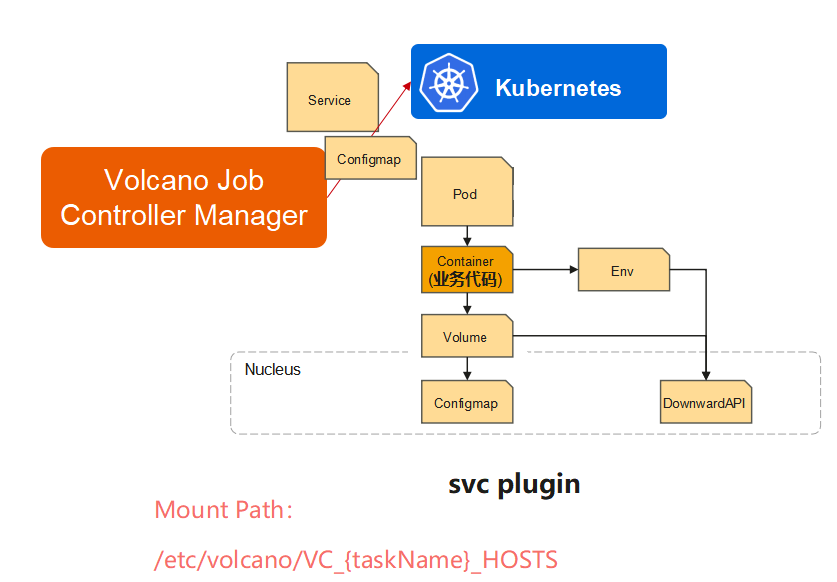
**svc:**提供不同类型任务之间互访能力
**env:**任务索引,例如 Tensorflow Worker index
**ssh:**ssh 秘钥对创建及挂载,主要供 MPI 作业使用
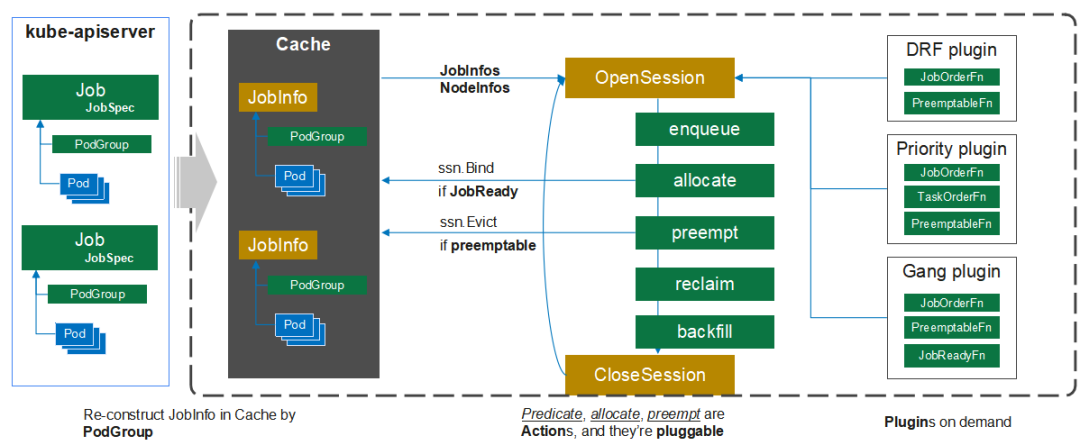
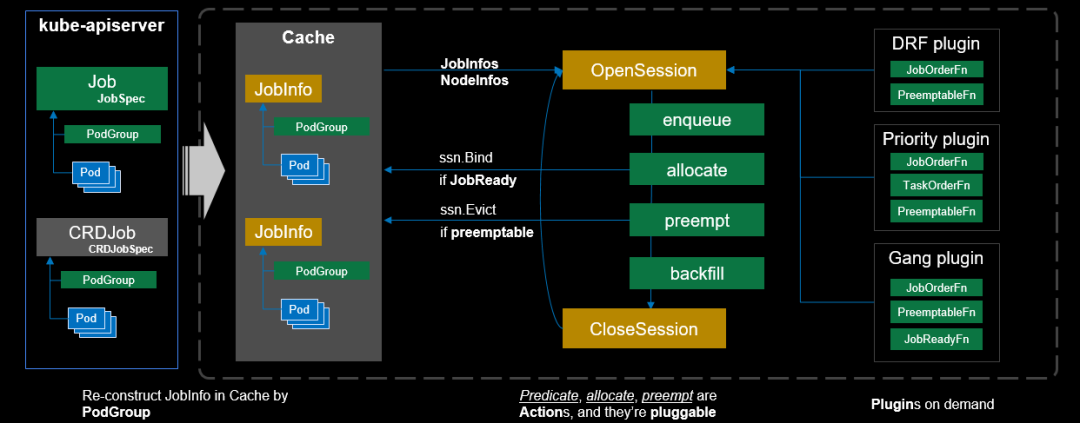
Scheduler架构
Scheduler支持动态配置和加载。
核心调度算法
- Gang Scheduling
- Fair Share
- Preempt & Reclaim
- Reserve & Backfill
- Topology Aware Scheduling
- GPU Sharing
Volcano Code Tour
cmd目录是Volcano所有组件启动的入口;config 是Volcano的配置;defs 是安装时的配置;docs 是Volcano的设计文档;example 提供了简单的例子,hack 提供安装时的脚本;installer 提供安装的模板。
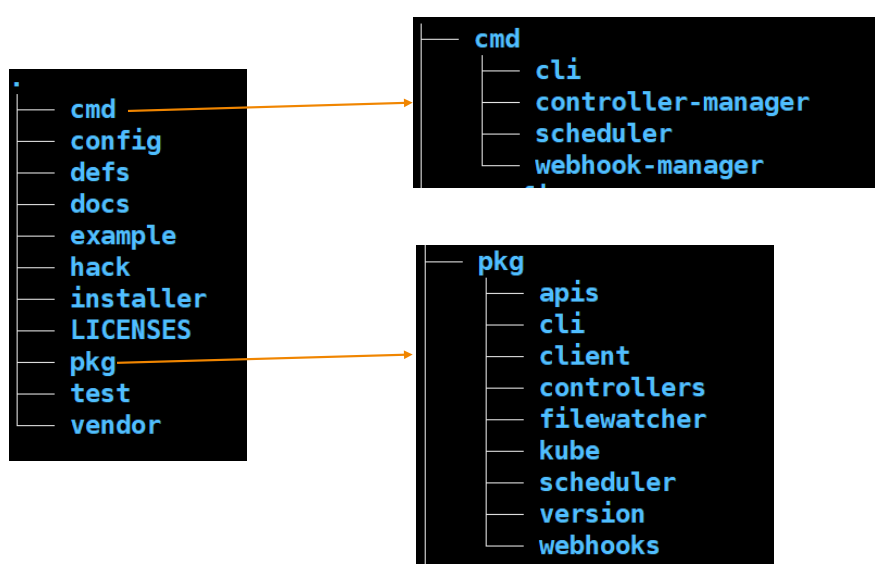
pkg 是最重要的目录,里面包含了 api、controller、scheduler 、webhook 等代码。test 提供了e2e测试用例, vendor是依赖库。
Volcano 安装部署
Volcano Install
Volcano安装部署有多种方式:若已存在K8S集群,建议通过 Helm方式安装部署,该方式支持自定义安装配置;开发者建议通过Development Yaml方式部署。
对于开发者,Volcano已内置一键式安装部署脚本,路径为 volcano. sh/volcano/hack/local-up-volcano. sh。运行该脚本时,默认会使用kind创建 Docker in Docker的模拟集群,并安装部署Volcano。
Volcano 组件
正确安装部署后,将生成4个组件,分别为:Volcano-admission、Volcano-admission-init、Volcano-controllers、 Volcano-scheduler ,其中admission-init以作业的方式生成证书。

设计原理解读
基本的概念

我们从基本的概念开始,这块列了4个。
首先是队列,队列其实大家都有一些概念,跟我们其实以前学的队列的差不多,它可以使用多个队列去对一个集群的资源进行动态的去划分,主要目的是为了用资源的一个复用以及共享,我们可以给队列去配权重、资源配额等等。对于K8s来讲,不同的newspace的用户可以把作业提交到不同的队列。
第二个是Volcano Job,也就是我们所说的作业,它定义了我们之前提到很多次的生命周期,所包含的任务以及跟任务相关的数据input、output信息。
设计目标
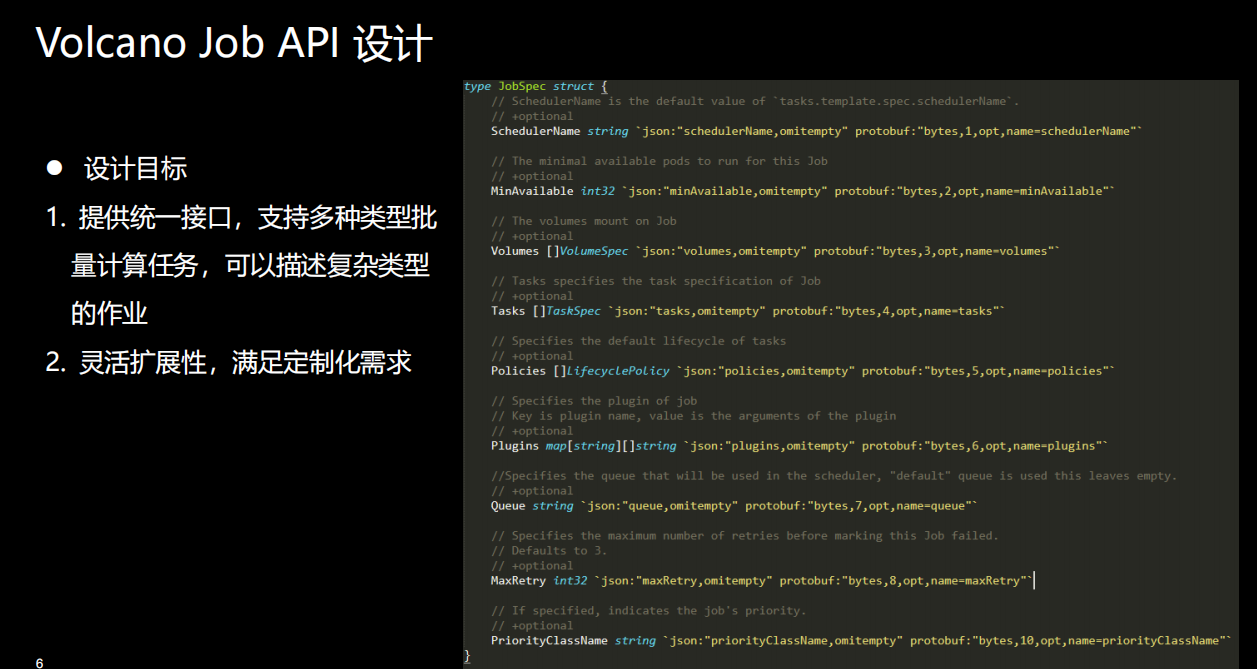
设计目标:
1)提供统一接口,支持多种类型批 量计算任务,可以描述复杂类型 的作业
Job API的定位是一个bach-system,支持多种类型的作业,好比说大数据、AI、HPC,包含了多种作业类型。所以我们希望提供一个统一的接口去简化用户的使用,无论哪种类型、哪个场景的作业,都可以通过统一的接口运行起来,这是我们设计的时候一个很重要的考虑点。
2)灵活扩展性,满足定制化需求
其次就是灵活性,虽然说不同类型的作业,通过一个作业能够跑起来,但其实不同的场景,有不同定制化化需求,所以我们在设计这个Job API的时候,能提供定制化的需求,可以支持大部分的场景。
Volcano多任务模板
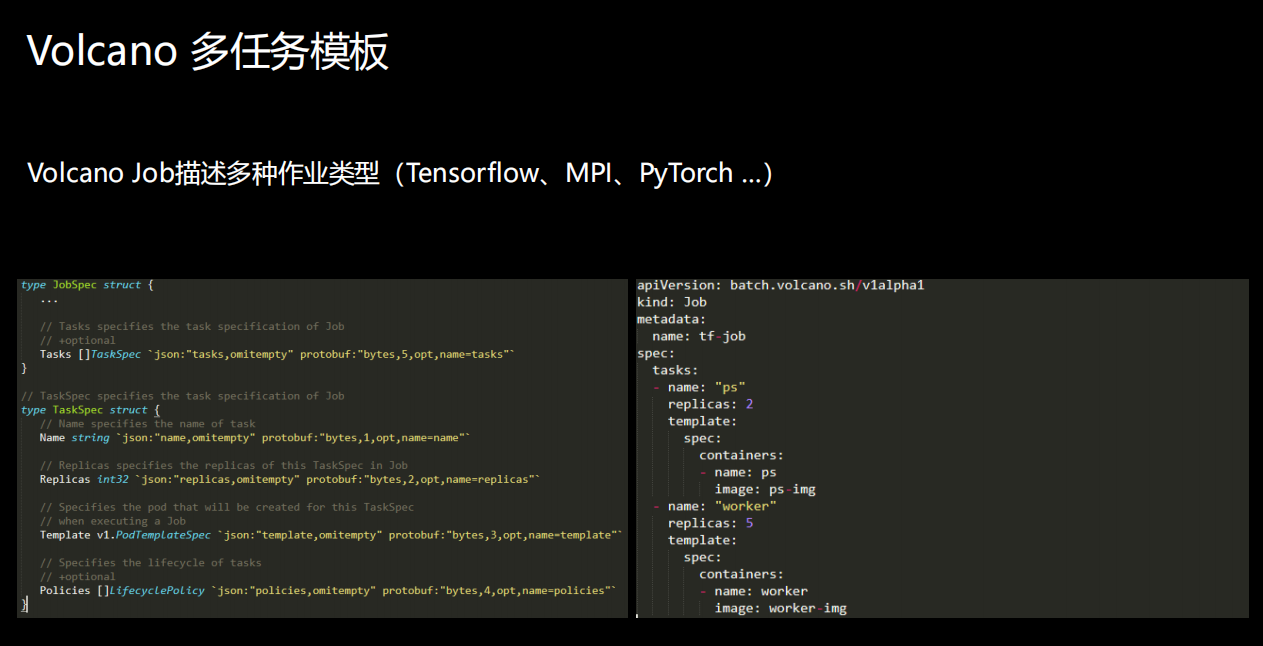
TaskSpec结构体里除包含最基本的信息外,还有一个policies, policy就定义了Task的生命周期。因为一个Job里会有多个 Task,就像下图描述的如何用Vocano运行一个Tensorflow的Job,Task里面就有多个角色,不同的角色可以定义它自己的 port template,这样的话我们就可以通过一个统一的Volcano Job支持不同的作业类型。

Volcano作业插件机制
-
作业内任务互相访问的需求
-
作业内任务索引
-
ssh免密登录
MPI作业一般需要ssh免密登录
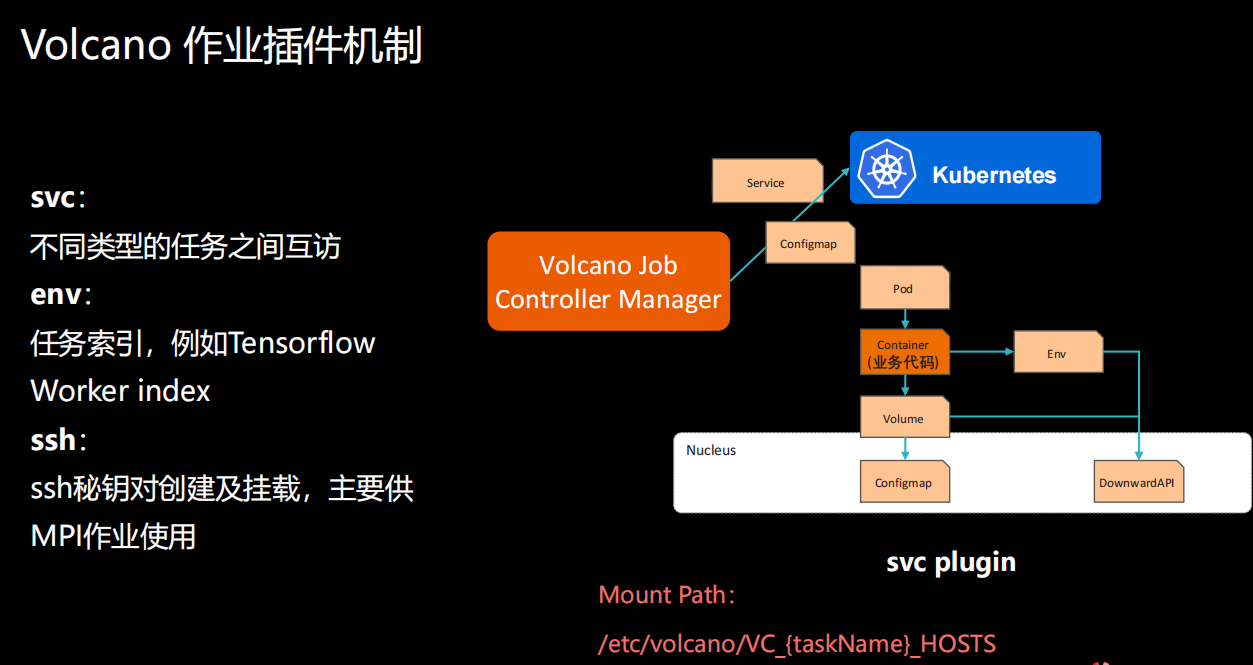
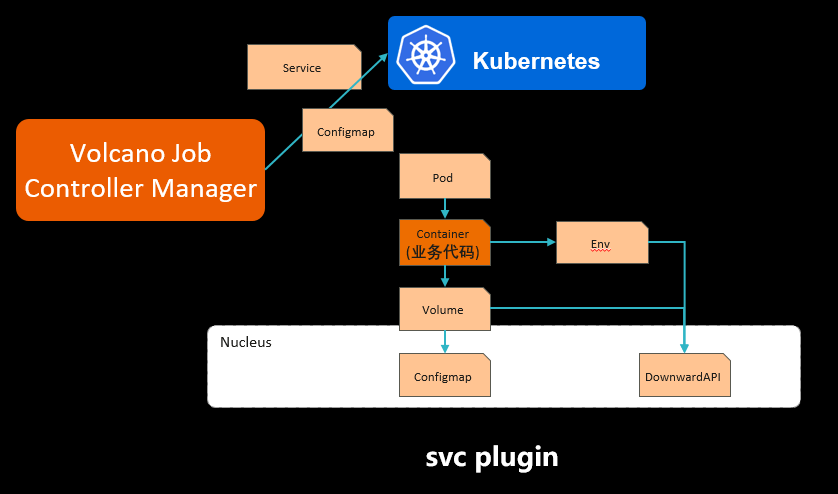
它其实有一些定制化的需求。好比说分布式训练这种作业,它在多个pod跑起来之后,它的pod和pod之间需要有网络互访,做数据同步。 对于像这种类型的需求,我们通过插件化的机制做成job plugin,让用户去通过这种方式去支撑它的场景。
在这里面我们看到我们定义的接口叫PluginInterface。PluginInterface的定义当一个作业在增删改查,或者Job在创建的时候,用户可以去实现这个函数,去做定制化的需求。以下三个作业的插件是我们默认已经支持的,简单配置就可以使用:
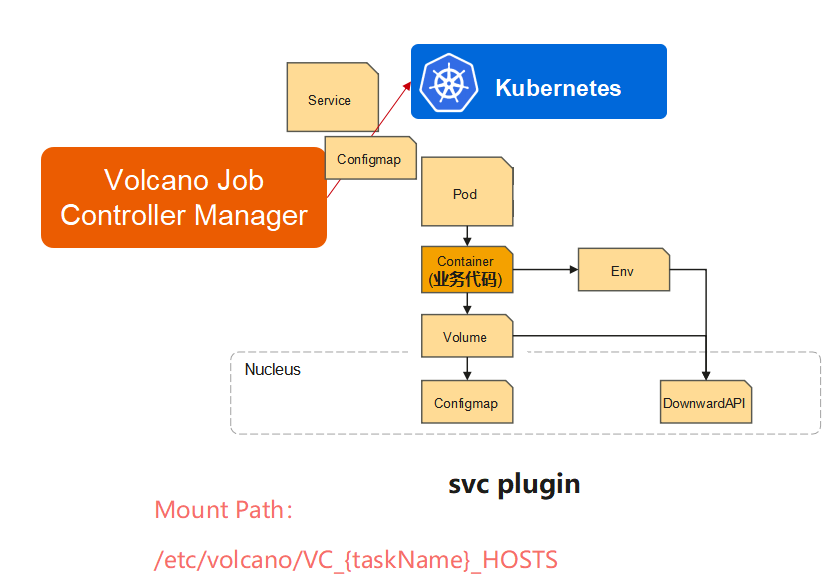
**svc:**不同类型的任务之间互访
**env:**任务索引,例如Tensorflow Worker index
ssh: ssh秘钥对创建及挂载,主要供MPI作业使用
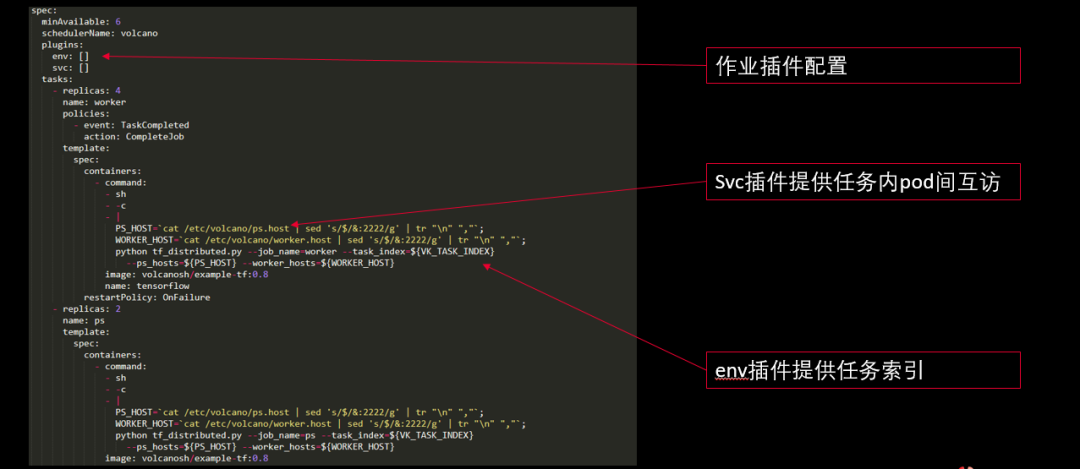
接下来我们看一下作业插件是怎么使用的。它使用起来其实非常简单,刚才说的那三个插件,只要在job spec里面的plugins字段,再加上插件的名字(如有需要还可以添加参数,本课示例未添加)就可以运行起来了。
下图是一个Volcano跑Tensorflow的Job。
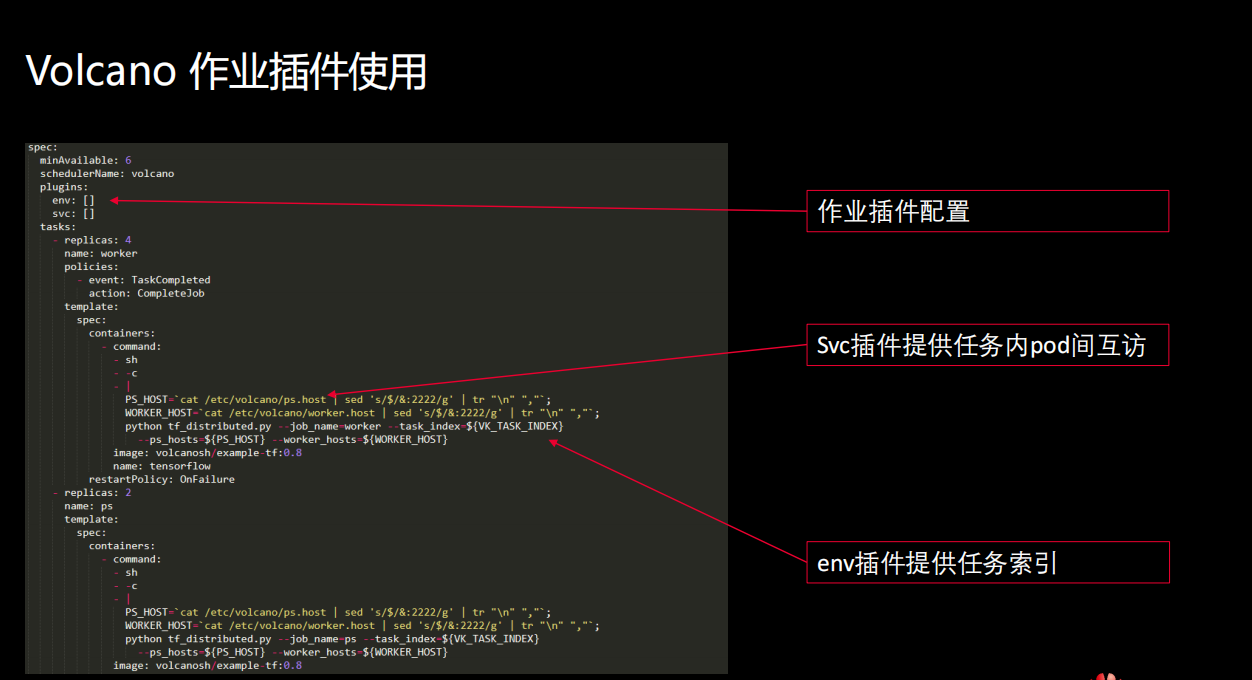
除了刚才提到的统一job、定制化的需求,还有一个很重要的方面就是作业生命周期的管理。作业的状态以及pod状态是非常多的,上节课我们也提到大概有七八种pod的状态,这些pod在发生不同事件时,对于作业的状态都会有影响。由于不同的场景需求是不一样的,这就要求我们在支持生命周期管理时,提供丰富的用户可配置机制的生命周期管理。
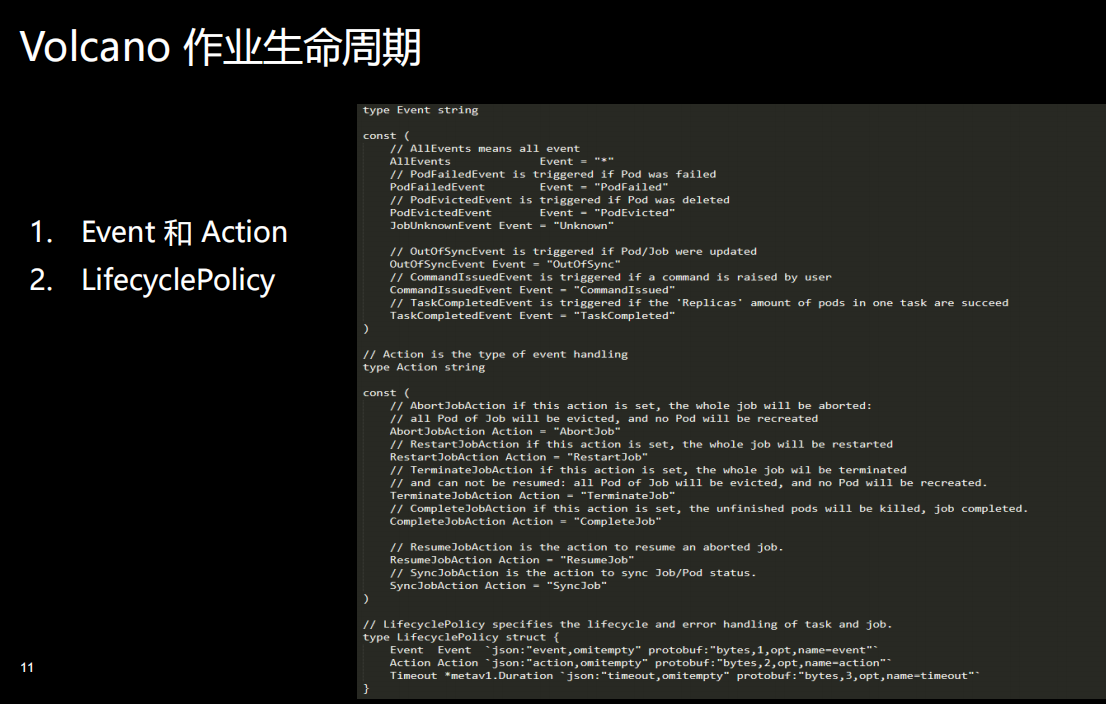
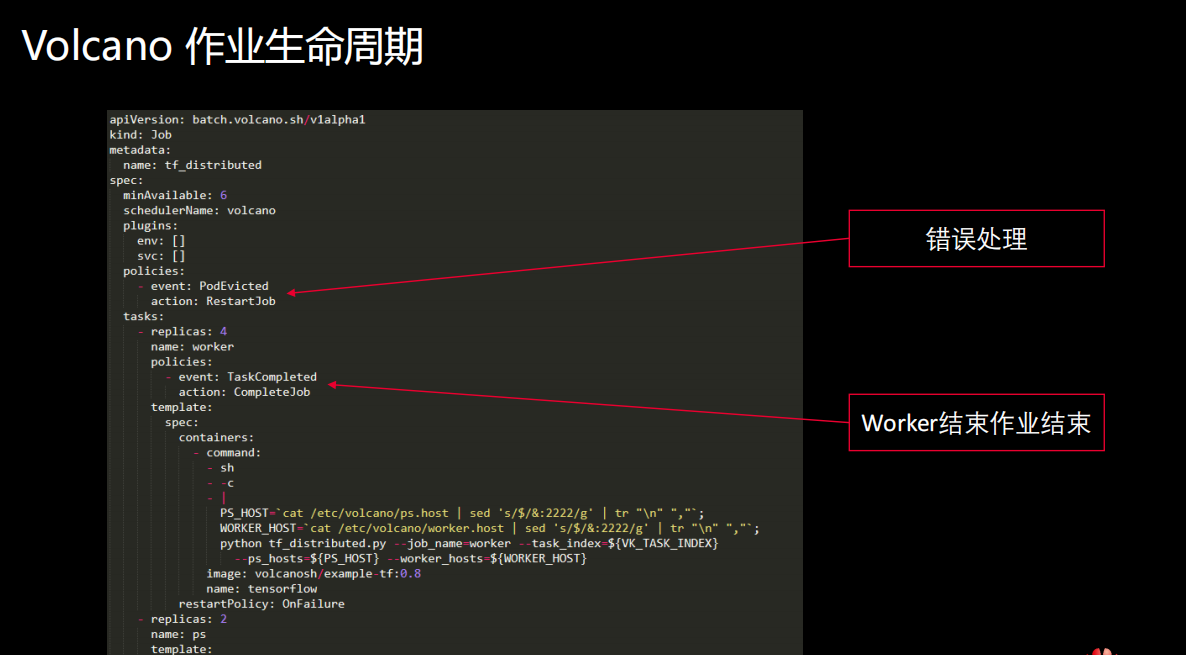
除了作业生命周期管理之外,还有一个就是作业状态的设计。上一节课里面我们提到我们在Volcano里增加了很多Pod的状态。现在这里面提到的是作业的状态,作业的状态有8种,Controller 维护 State 子类的实例,State定义接口,封装与Controller 特定状态相关的行为,每个子类实现一个与Controller 特定状态相关的行为。
第三个概念就是 PodGroup,这是我们新加的一个概念,PodGroup相当于是一个任务组,它和作业是一对一的关系,主要是供 schedule调度时使用的。
第四个的话就是Command,主要与作业的操作相关。
Volcano设计原则
有了这些基本的概念之后,再来看看设计的原则。
Job API的定位是一个bach-system,支持多种类型的作业,好比说大数据、AI、HPC,包含了多种作业类型。所以我们希望提供一个统一的接口去简化用户的使用,无论哪种类型、哪个场景的作业,都可以通过统一的接口运行起来,这是我们设计的时候一个很重要的考虑点。其次就是灵活性,虽然说不同类型的作业,通过一个作业能够跑起来,但其实不同的场景,有不同的定制化需求,所以我们在设计这个Job API的时候,能提供定制化的需求,可以支持大部分的场景。
接下来我们来看一下多任务模板,TaskSpec结构体里除包含最基本的信息外,还有一个policies, policy就定义了Task的生命周期。因为一个Job里会有多个 Task,就像下图描述的如何用Vocano运行一个Tensorflow的Job,Task里面就有多个角色,不同的角色可以定义它自己的 port template,这样的话我们就可以通过一个统一的Volcano Job支持不同的作业类型。
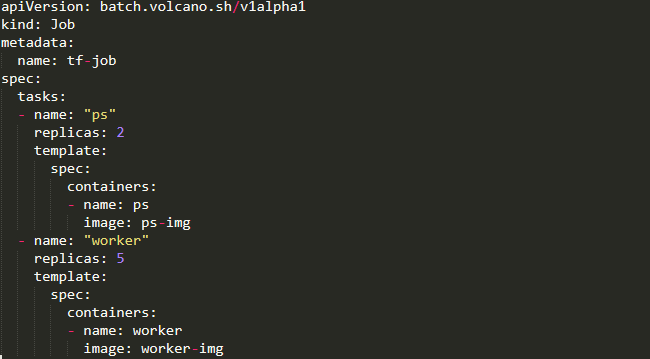
下一部分说一说不同作业的类型,它其实有一些定制化的需求。好比说分布式训练这种作业,它在多个pod跑起来之后,它的pod和pod之间需要有网络互访,做数据同步。 对于像这种类型的需求,我们通过插件化的机制做成job plugin,让用户去通过这种方式去支撑它的场景。
在这里面我们看到我们定义的接口叫PluginInterface。PluginInterface的定义当一个作业在增删改查,或者Job在创建的时候,用户可以去实现这个函数,去做定制化的需求。以下三个作业的插件是我们默认已经支持的,简单配置就可以使用:
- **svc:**不同类型的任务之间互访
- **env:**任务索引,例如Tensorflow Worker index
- **ssh:**ssh秘钥对创建及挂载,主要供MPI作业使用
接下来我们看一下作业插件是怎么使用的。它使用起来其实非常简单,刚才说的那三个插件,只要在job spec里面的plugins字段,再加上插件的名字(如有需要还可以添加参数,本课示例未添加)就可以运行起来了。
下图是一个Volcano跑Tensorflow的Job。
除了刚才提到的统一job、定制化的需求,还有一个很重要的方面就是作业生命周期的管理。作业的状态以及pod状态是非常多的,上节课我们也提到大概有七八种pod的状态,这些pod在发生不同事件时,对于作业的状态都会有影响。由于不同的场景需求是不一样的,这就要求我们在支持生命周期管理时,提供丰富的用户可配置机制的生命周期管理。
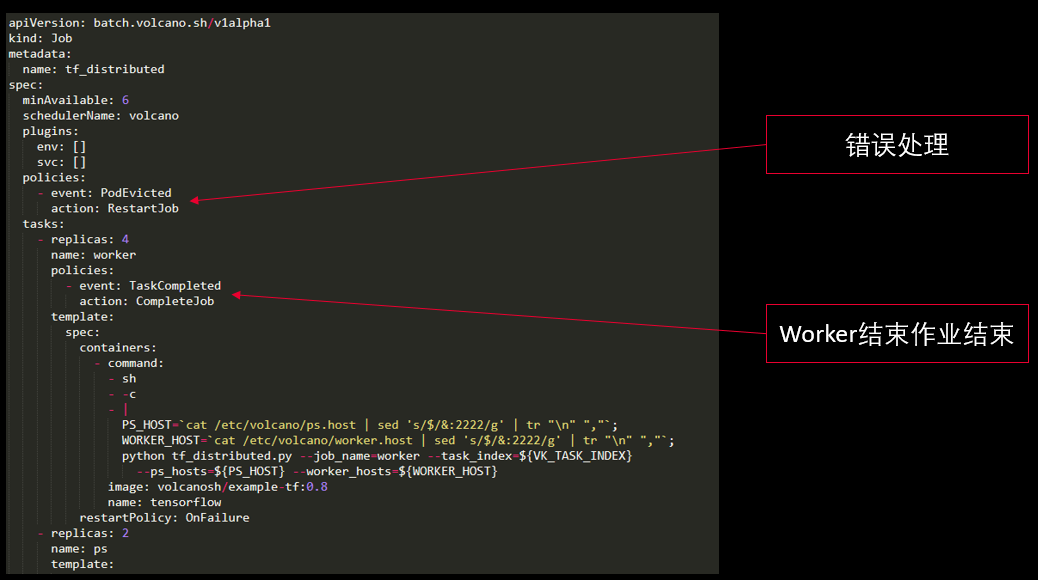
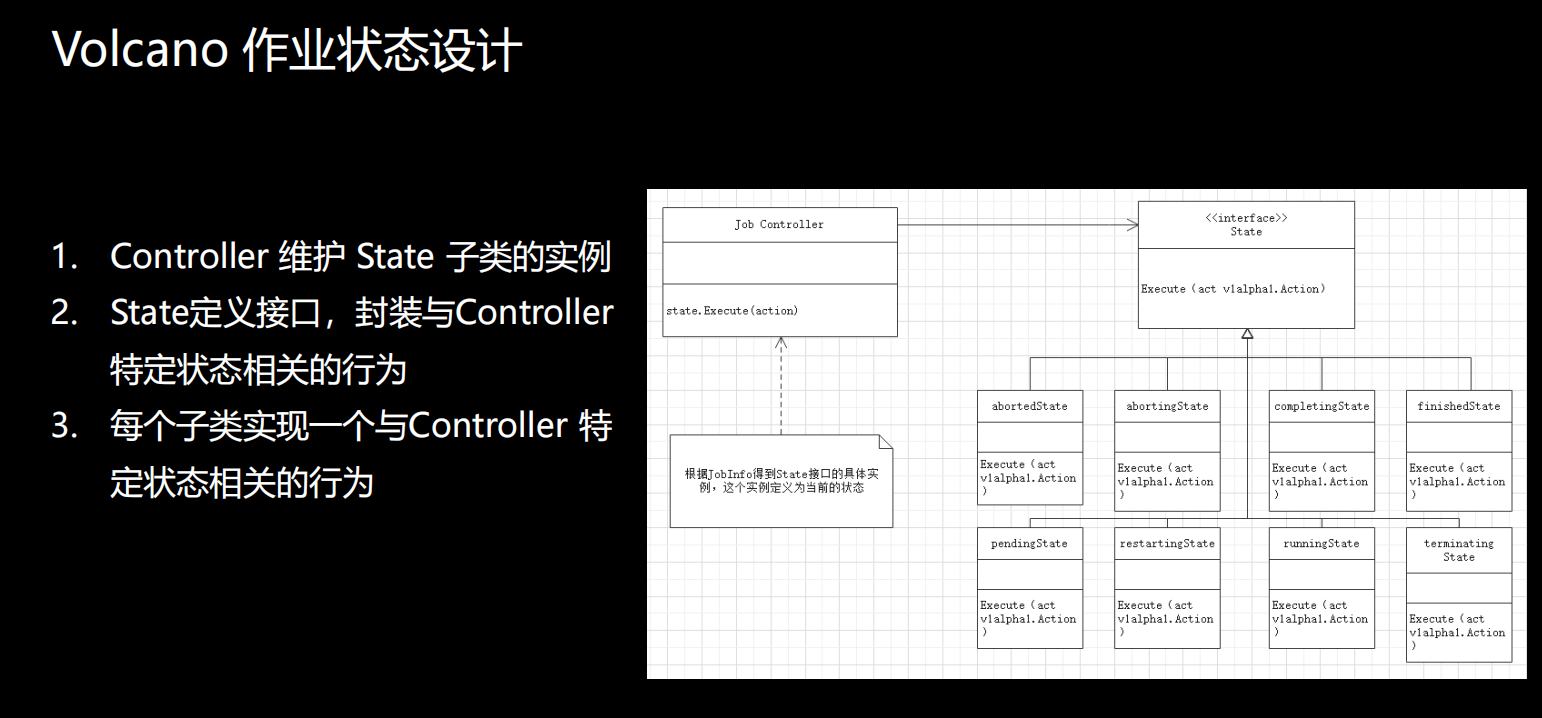
除了作业生命周期管理之外,还有一个就是作业状态的设计。上一节课里面我们提到我们在Volcano里增加了很多Pod的状态。现在这里面提到的是作业的状态,作业的状态有8种,Controller 维护 State 子类的实例,State定义接口,封装与Controller 特定状态相关的行为,每个子类实现一个与Controller 特定状态相关的行为。
下边大概介绍一下Scheduler。
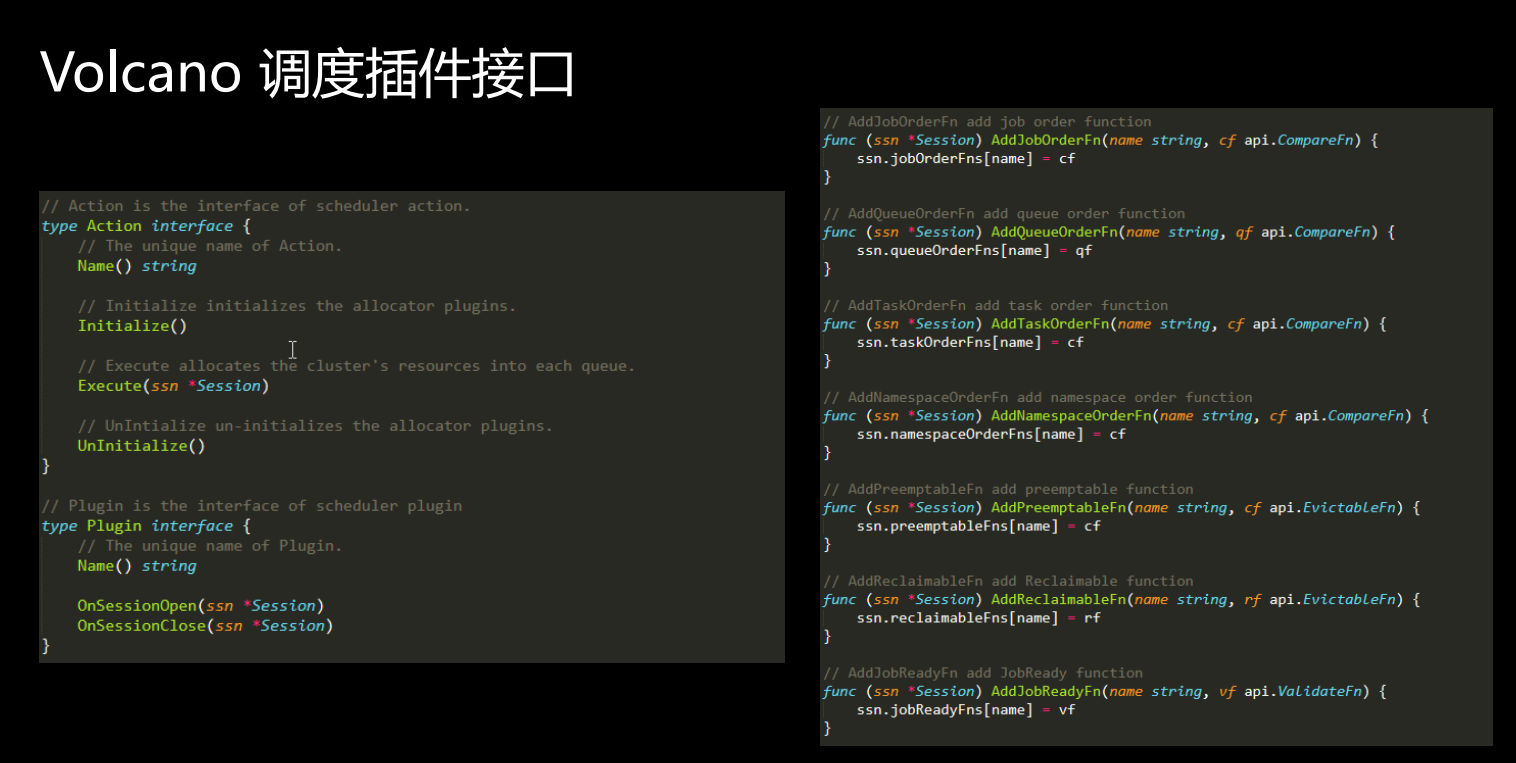
我们来看接口,下图这块定义的是action和plugin的接口,非常简单,你看在action里面它主要的一个函数就是把资源分配到队列,这一个函数,在这个action里面就可以定义资源分配的整个的逻辑。而plugin里面主要两个主要的函数就是on session open和on session close。
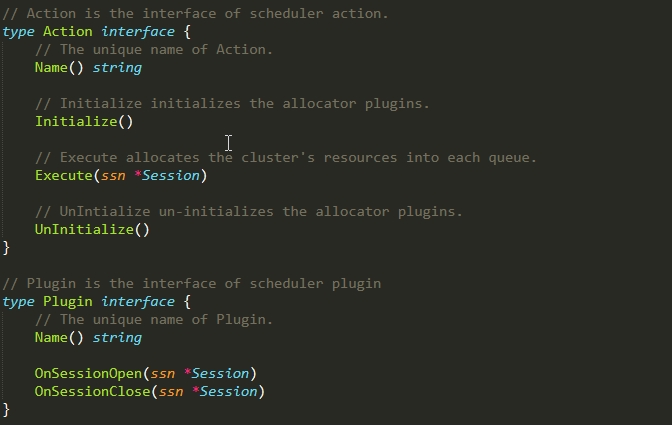
那我们要用起来的时候,我们应该怎么去配置?这里面讲的统一的配置策略,有几个重要的元素:Actions、Plugins、Option、Tiers。
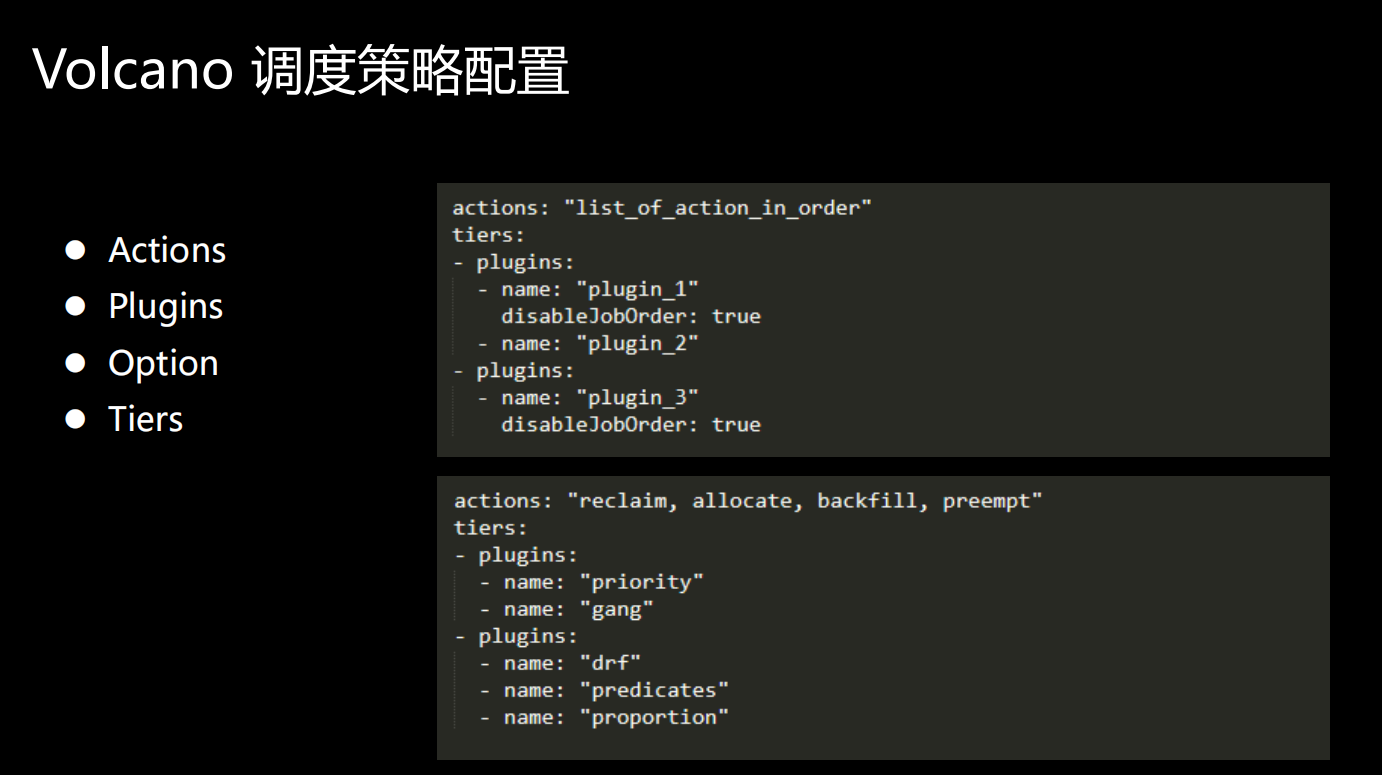
几个重要的元素:Actions、Plugins、Option、Tiers。

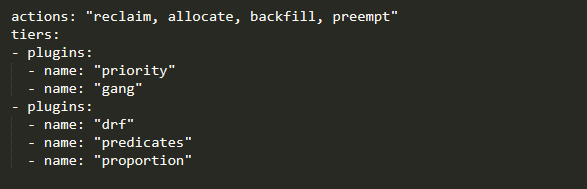
代码演练:
-
Volcano 调度插件代码举例解析
github\volcano\pkg\scheduler\plugins\gang\gang.go
-
运行一个简单的Volcano作业
-
配置Gang-scheduling,体验效果
-
Volcano 调度插件代码举例解析
github\volcano\pkg\scheduler\plugins\gang\gang.go
-
运行一个简单的Volcano作业
-
配置Gang-scheduling,体验效果
-
提交多作业,体验公平调度效果














 1501
1501











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









