







2020.4.5添加:
哈哈,迟来的源码,我把它放到GitHub上了:包含详细注释的树模型源码;包括决策树和随机森林,欢迎取用,欢迎讨论,欢迎star;
我才发现CSDN的资源下载自动要求这么多积分,我之前上传的时候是限定0积分的。。
###################正文分割线######################
决策树其实就是按节点分类数据集的一种方法。在本文中,我将讨论数学上如何使用信息论划分数据集,并编写代码构建决策树(本文使用ID3算法构建决策树,ID3算法可以用来划分标称型数据集)。
创建决策树进行分类的流程如下:
(1) 创建数据集
(2) 计算数据集的信息熵
(3) 遍历所有特征,选择信息熵最小的特征,即为最好的分类特征
(4) 根据上一步得到的分类特征分割数据集,并将该特征从列表中移除
(5) 执行递归函数,返回第三步,不断分割数据集,直到分类结束
(6) 使用决策树执行分类,返回分类结果
首先,给出一个简单数据集:
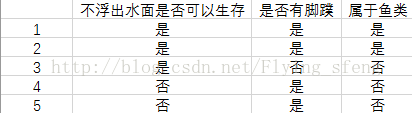
数据解读:
在该数据集中包含五个海洋动物,有两个特征:(1)不浮出水面是否可以生存;(2)是否有脚蹼;这些动物被分成两类:鱼类和非鱼类。在我们构建决策树的过程中,对某个动物,只有两个特征都为“是”时,才将其判定为鱼类。
在构建决策树时,我们需要解决的第一个问题是:当前数据集哪个特征在划分数据分类时起决定性作用,即我们要如何找出最优的分类特征。为了找到决定性的特征,划分出最好的结果,我们必须评估每个特征。完成数据划分后,原始数据集就被划分为几个数据子集,这些数据子集会分布在第一个决策点的所有分支上。如果某个分支下的数据属于同一类型,即数据已正确分类,无需进一步分割。如果数据子集内的数据不属于同个类型,则需要重复划分数据子集的过程。划分数据子集的算法和划分原始数据集的方法相同(因此可用递归函数继续划分子集),直到所有具有相同类型的数据都在一个数据子集内。
构建决策树的伪代码函数createTree()如下所示:
检测数据集中的每个子集是否属于同一分类:
If so return 类标签
Else:
寻找划分数据集的最好特征
划分数据集
创建分支节点
For 每个划分的子集:
调用函数createTree()并增加返回结果到分支节点中
Return 分支节点
1)划分数据集的大原则是:将无序的数据变得更加有序。这里引入信息熵的概念。如果待分类的事务可能划分在多个分类之中,则符号xi的信息定义为:
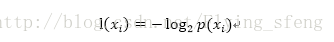
其中p(xi)是选择该分类的概率。
为了计算熵,我们需要计算所有类别所有可能值包含的信息期望值,通过下面的公式得到:
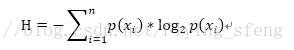
直观的理解:如果x属于某个分类的值越大(即数据越有序),H的值越小;极端情况下,p(xi)=1时,H=0,此时分类最准确。所以我们要使H的值尽可能小。
计算给定数据集的信息熵的代码如下:
'''计算数据集的信息熵 (信息熵即指类别标签的混乱程度,值越小越好)'''
def calcshan(dataSet):
lenDataSet=len(dataSet)
p={}
H=0.0
for data in dataSet:
currentLabel=data[-1] #获取类别标签
if currentLabel not in p.keys(): #若字典中不存在该类别标签,即创建
p[currentLabel]=0
p[currentLabel]+=1 #递增类别标签的值
for key in p:
px=float(p[key])/float(lenDataSet) #计算某个标签的概率
H-=px*log(px,2) #计算信息熵
return H结果如下:
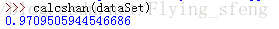
(2)计算完信息熵后,我们便可以得到数据集的无序程度。我们将对每个特征划分数据集的结果计算一次信息熵,然后判断哪个特征划分数据集是最好的划分方式(根据信息熵判断,信息熵越小,说明划分效果越好)。
按照给定特征划分数据集的代码如下:
'''根据某一特征分类数据集'''
def spiltData(dataSet,axis,value): #dataSet为要划分的数据集,axis为给定的特征,value为给定特征的具体值
subDataSet=[]
for data in dataSet:
subData=[]
if data[axis]==value:
subData=data[:axis] #取出data中第0到axis-1个数进subData;
subData.extend(data[axis+1:]) #取出data中第axis+1到最后一个数进subData;这两行代码相当于把第axis个数从数据集中剔除掉
subDataSet.append(subData) #此处要注意expend和append的区别
return subDataSet
结果如下:
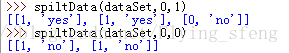
(3)选择最好的数据集划分方式,代码如下:
'''遍历所有特征,选择信息熵最小的特征,即为最好的分类特征'''
def chooseBestFeature(dataSet):
lenFeature=len(dataSet[0])-1 #计算特征维度时要把类别标签那一列去掉
shanInit=calcshan(dataSet) #计算原始数据集的信息熵
feature=[]
inValue=0.0
bestFeature=0
for i in range(lenFeature):
shanCarry=0.0
feature=[example[i] for example in dataSet] #提取第i个特征的所有数据
feature=set(feature) #得到第i个特征所有的分类值,如'0'和'1'
for feat in feature:
subData=spiltData(dataSet,i,feat) #先对数据集按照分类值分类
prob=float(len(subData))/float(len(dataSet))
shanCarry+=prob*calcshan(subData) #计算第i个特征的信息熵
outValue=shanInit-shanCarry #原始数据信息熵与循环中的信息熵的差
if (outValue>inValue):
inValue=outValue #将信息熵与原始熵相减后的值赋给inValue,方便下一个循环的信息熵差值与其比较
bestFeature=i
return bestFeature
结果如下:
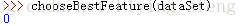
(4)选择好最好的划分特征后,接下来,可以开始创建决策树了。其工作原理如下:得到原始数据集,然后基于最好的属性值划分数据集,由于特征值可能多于两个,因此可能存在大于两个分支的数据集划分。第一次划分后,数据将被向下传递到树分支的下一个节点,在这个节点上,我们可以再次划分数据。因此我们可以使用递归的原则处理数据集。递归结束的条件是:程序遍历完所有划分数据集的属性,或者每个分支下的所有实例都具有相同的分类。
具体实现代码如下:
'''创建我们所要分类的决策树'''
def createTree(dataSet,label):
classList=[example[-1] for example in dataSet] #classList是指当前数据集的类别标签
if classList.count(classList[0])==len(classList): #计算classList中某个类别标签的数量,若只有一类,则数量与它的数据长度相等
return classList[0]
if len(dataSet[0])==1: #当处理完所有特征而类别标签还不唯一时起作用
return majorityCnt(classList)
featBest=chooseBestFeature(dataSet) #选择最好的分类特征
feature=[example[featBest] for example in dataSet] #接下来使用该分类特征进行分类
featValue=set(feature) #得到该特征所有的分类值,如'0'和'1'
newLabel=label[featBest]
del(label[featBest])
Tree={newLabel:{}} #创建一个多重字典,存储决策树分类结果
for value in featValue:
subLabel=label[:]
Tree[newLabel][value]=createTree(spiltData(dataSet,featBest,value),subLabel) #递归函数使得Tree不断创建分支,直到分类结束
return Tree
结果如下:
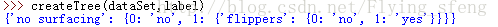
(5)依靠训练数据构造了决策树之后,我们可以将它用于实际数据的分类。在执行数据分类时,需要使用决策树以及用于构造树的标签向量。然后,程序比较测试数据与决策树上的数值,递归执行该过程直到进入叶子节点;最后将测试数据定义为叶子节点所属的类型。
具体实现代码如下:
'''使用决策树执行分类,返回分类结果'''
def classify(tree,label,testVec): #tree为createTree()函数返回的决策树;label为特征的标签值;testVec为测试数据,即所有特征的具体值构成的向量
firstFeat=tree.keys()[0] #取出tree的第一个键
secondDict=tree[firstFeat] #取出tree第一个键的值,即tree的第二个字典(包含关系)
labelIndex=label.index(firstFeat) #得到第一个特征firstFeat在标签label中的索引
for key in secondDict.keys(): #遍历第二个字典的键
if testVec[labelIndex]==key: #如果第一个特征的测试值与第二个字典的键相等时
if type(secondDict[key]).__name__=='dict': #如果第二个字典的值还是一个字典,说明分类还没结束,递归执行classify函数
classLabel=classify(secondDict[key],label,testVec) #递归函数中只有输入的第一个参数不同,不断向字典内层渗入
else:
classLabel=secondDict[key] #最后将得到的分类值赋给classLabel输出
return classLabel
结果如下:

我们可以看到,只有测试数据的两个特征都为1时,才会输出‘yes’,判定为鱼类,结果符合我们的实际要求。
现在我们已经创建了使用决策树的分类器,但是每次使用分类器时,必须重新构造决策树,而且构造决策树是很耗时的任务。因此,为了节省计算时间,最好能够在每次执行分类时调用已经构造好的决策树。这里我们使用Python的pickle模块序列化对象。序列化对象可以在磁盘上保存对象,并在需要的时候读取出来。
使用pickle模块存储决策树代码如下:
'''使用pickle模块存储决策树'''
def storeTree(tree,filename):
import pickle
fw=open(filename,'w')
pickle.dump(tree,fw)
fw.close()
'''打开文件取出决策树'''
def loadTree(filename):
import pickle
fr=open(filename,'r')
return pickle.load(fr)
结果如下:

执行完storeTree()函数,我们的代码路径里就会多出一个dataTree.txt的文件,保存决策树内容,以后要使用决策树进行分类时,使用loadTree()函数直接调用即可。
参考书籍:
《机器学习实战》 Peter Harrington著 李锐,李鹏,曲亚东,王斌译














 876
876











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









