







示例:
找出监听80端口的nginx配置文件:
cd /etc/nginx
grep -e 'listen[^1-9]\+80\s*;' -r ./
------------------------------------------
Regular Expressions in grep
Regular Expressions is nothing but a pattern to match for each input line. A pattern is a sequence of characters. Following all are examples of pattern:^w1
w1|w2
[^ ] foo
bar
[0-9]
Three types of regex
The grep understands three different types of regular expression syntax as follows:
- basic (BRE)
- extended (ERE)
- perl (PCRE)
grep Regular Expressions Examples
Search for ‘vivek’ in /etc/passswdgrep 'vivek' /etc/passwd
Sample outputs:
vivek:x:1000:1000:Vivek Gite,,,:/home/vivek:/bin/bash vivekgite:x:1001:1001::/home/vivekgite:/bin/sh gitevivek:x:1002:1002::/home/gitevivek:/bin/sh
Search vivek in any case (i.e. case insensitive search)grep -i -w 'vivek' /etc/passwd
Search vivek or raj in any casegrep -E -i -w 'vivek|raj' /etc/passwd
The PATTERN in last example, used as an extended regular expression. The following will match word Linux or UNIX in any case:egrep -i '^(linux|unix)' filename
How to match single characters
The . character (period, or dot) matches any one character. Consider the following demo.txt file:$ cat demo.txt
Sample outputs:
foo.txt bar.txt foo1.txt bar1.doc foobar.txt foo.doc bar.doc dataset.txt purchase.db purchase1.db purchase2.db purchase3.db purchase.idx foo2.txt bar.txt
Let us find all filenames starting with purchase:grep 'purchase' demo.txt
Next I need to find all filenames starting with purchase and followed by another character:grep 'purchase.db' demo.txt
Our final example find all filenames starting with purchase but ending with db:grep 'purchase..db' demo.txt 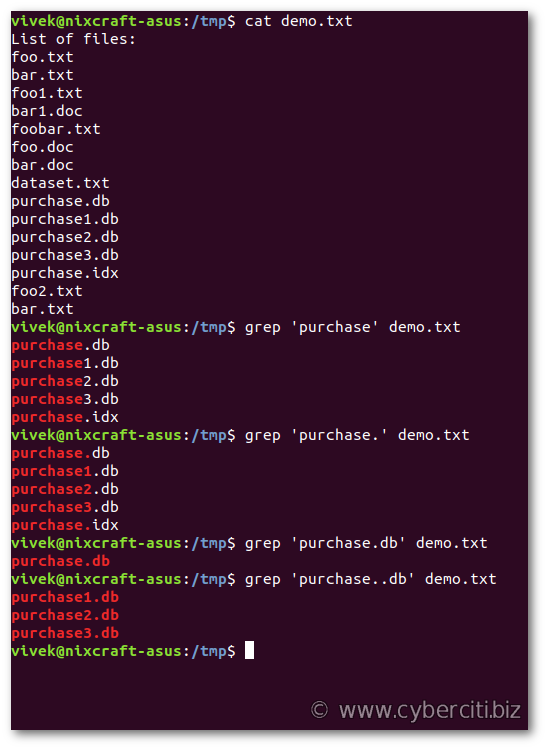
How to match only dot (.)
A dot (.) has a special meaning in regex, i.e. match any character. But, what if you need to match dot (.) only? I want to tell my grep command that I want actual dot (.) character and not the regex special meaning of the . (dot) character. You can escape the dot (.) by preceding it with a \ (backslash):grep 'purchase..' demo.txt
grep 'purchase.\.' demo.txt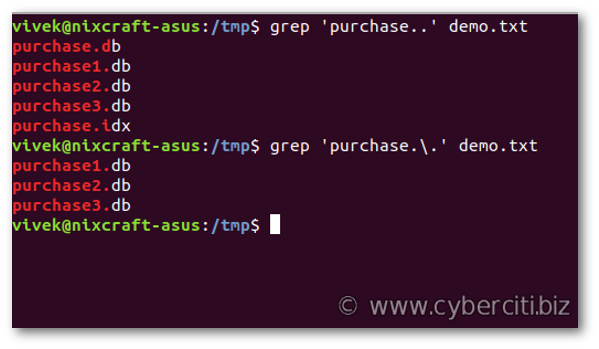
Anchors
You can use ^ and $ to force a regex to match only at the start or end of a line, respectively. The following example displays lines starting with the vivek only:grep ^vivek /etc/passwd
Sample outputs:
vivek:x:1000:1000:Vivek Gite,,,:/home/vivek:/bin/bash vivekgite:x:1001:1001::/home/vivekgite:/bin/sh
You can display only lines starting with the word vivek only i.e. do not display vivekgite, vivekg etc:grep -w ^vivek /etc/passwd
Find lines ending with word foo:grep 'foo$' filename
Match line only containing foo:grep '^foo$' filename
You can search for blank lines with the following examples:grep '^$' filename
Matching Sets of Characters
How to match sets of character using grep
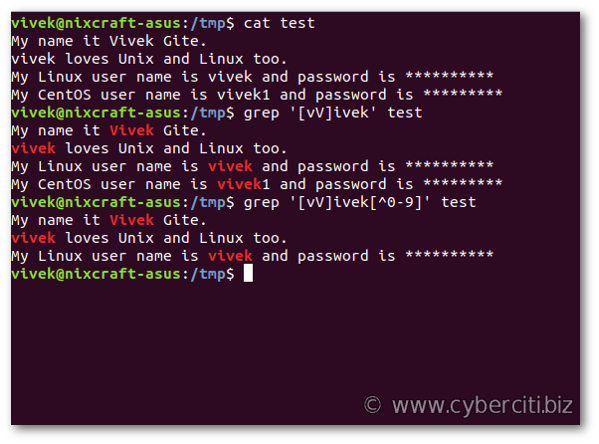
The dot (.) matches any single character. You can match specific characters and character ranges using [..] syntax. Say you want to Match both ‘Vivek’ or ‘vivek’:grep '[vV]ivek' filename
ORgrep '[vV][iI][Vv][Ee][kK]' filename
Let us match digits and upper and lower case characters. For example, try to math words such as vivek1, Vivek2 and so on:grep -w '[vV]ivek[0-9]' filename
In this example match two numeric digits. In other words match foo11, foo12, foo22 and so on, enter:grep 'foo[0-9][0-9]' filename
You are not limited to digits, you can match at least one letter:grep '[A-Za-z]' filename
Display all the lines containing either a “w” or “n” character:grep [wn] filename
Within a bracket expression, the name of a character class enclosed in “[:” and “:]” stands for the list of all characters belonging to that class. Standard character class names are:
- [[:alnum:]] – Alphanumeric characters.
- [[:alpha:]] – Alphabetic characters
- [[:blank:]] – Blank characters: space and tab.
- [[:digit:]] – Digits: ‘0 1 2 3 4 5 6 7 8 9’.
- [[:lower:]] – Lower-case letters: ‘a b c d e f g h i j k l m n o p q r s t u v w x y z’.
- [[:space:]] – Space characters: tab, newline, vertical tab, form feed, carriage return, and space.
- [[:upper:]] – Upper-case letters: ‘A B C D E F G H I J K L M N O P Q R S T U V W X Y Z’.
In this example match all upper case letters:grep '[:upper:]' filename
How negates matching in sets
The ^ negates all ranges in a set:grep '[vV]ivek[^0-9]' test
Using grep regular expressions to search for text patterns
Wildcards
You can use the “.” for a single character match. In this example match all 3 character word starting with “b” and ending in “t”:
grep '\<b.t\>' filename
Where,
- \< Match the empty string at the beginning of word
- \> Match the empty string at the end of word.
Print all lines with exactly two characters:grep '^..$' filename
Display any lines starting with a dot and digit:grep '^\.[0-9]' filename
Escaping the dot
Say you just want to match an IP address 192.168.2.254 and nothing else. The following regex to find an IP address 192.168.1.254 will not work (remember the dot matches any single character?):grep '192.168.1.254' hosts
Sample outputs:
192.168.2.18 centos7 192x168y2z18 centos7
All three dots need to be escaped:
192.168.2.18 centos7
grep '192\.168\.1\.254' hosts
The following example will only match an IP address:egrep '[[:digit:]]{1,3}\.[[:digit:]]{1,3}\.[[:digit:]]{1,3}\.[[:digit:]]{1,3}' file
How Do I Search a Pattern Which Has a Leading – Symbol?
Searches for all lines matching ‘–test–‘ using -e option Without -e, grep would attempt to parse ‘–test–‘ as a list of options:grep -e '--test--' filename
How Do I do OR with grep?
Use the following syntax:grep -E 'word1|word2' filename
### OR ###
egrep 'word1|word2' filename
ORgrep 'word1\|word2' filename
How do I AND with grep?
Use the following syntax to display all lines that contain both ‘word1’ and ‘word2’grep 'word1' filename | grep 'word2'
ORgrep 'foo.*bar\|word3.*word4' filename
How Do I Test Sequence?
You can test how often a character must be repeated in sequence using the following syntax:
{N}
{N,}
{min,max}
Match a character “v” two times:egrep "v{2}" filename
The following will match both “col” and “cool” words:egrep 'co{1,2}l' filename
Our next example will match any row of at least three letters ‘c’.egrep 'c{3,}' filename
In this example, I will match mobile number which is in the following format 91-1234567890 (i.e TwoDigit-TenDigit)grep "[[:digit:]]\{2\}[ -]\?[[:digit:]]\{10\}" filename
How Do I Highlight with grep?
Pass the --color as follows:grep --color regex filename
How Do I Show Only The Matches, Not The Lines?
Use the following syntax:grep -o regex filename
grep Regular Expression Operator
I hope following table will help you quickly understand regular expressions in grep when using under Linux or Unix-like systems:
| grep regex operator | Meaning | Example |
|---|---|---|
| . | Matches any single character. | grep '.' file grep 'foo.' input |
| ? | The preceding item is optional and will be matched, at most, once. | grep 'vivek?' /etc/passwd |
| * | The preceding item will be matched zero or more times. | grep 'vivek*' /etc/passwd |
| + | The preceding item will be matched one or more times. | ls /var/log/ | grep -E "^[a-z]+\.log." |
| {N} | The preceding item is matched exactly N times. | egrep '[0-9]{2} input |
| {N,} | The preceding item is matched N or more times. | egrep '[0-9]{2,} input |
| {N,M} | The preceding item is matched at least N times, but not more than M times. | egrep '[0-9]{2,4} input |
| - | Represents the range if it’s not first or last in a list or the ending point of a range in a list. | grep ':/bin/[a-z]*' /etc/passwd |
| ^ | Matches the empty string at the beginning of a line; also represents the characters not in the range of a list. | grep '^vivek' /etc/passwd grep '[^0-9]*' /etc/passwd |
| $ | Matches the empty string at the end of a line. | grep '^$' /etc/passwd |
| \b | Matches the empty string at the edge of a word. | vivek '\bvivek' /etc/passwd |
| \B | Matches the empty string provided it’s not at the edge of a word. | grep '\B/bin/bash /etc/passwd |
| \< | Match the empty string at the beginning of word. | grep '\ |
| \> | Match the empty string at the end of word. | grep 'bash\>' /etc/passwd grep '\' /etc/passwd |
Linux grep vs egrep command
The egrep is the same as grep -E command. It interpret PATTERN as an extended regular expression. From the grep man page:
In basic regular expressions the meta-characters ?, +, {, |, (, and ) lose their special meaning; instead use the backslashed versions \?, \+, \{,
\|, \(, and \).
Traditional egrep did not support the { meta-character, and some egrep implementations support \{ instead, so portable scripts should avoid { in
grep -E patterns and should use [{] to match a literal {.
GNU grep -E attempts to support traditional usage by assuming that { is not special if it would be the start of an invalid interval specification.
For example, the command grep -E '{1' searches for the two-character string {1 instead of reporting a syntax error in the regular expression.
POSIX.2 allows this behavior as an extension, but portable scripts should avoid it.
Conclusion
You learned how to regular expressions (regex) in grep running on Linux or Unix with various examples. See GNU/grep man page online here or see the following resources:
- man page grep and regex(7)
- info page grep
This entry is 2 of 7 in the Linux / UNIX grep Command Tutorial series. Keep reading the rest of the series:

















 564
564

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









