








测评团队|SuperCLUE
近期,SuperCLUE发布了《中文大模型基准测评2024年10月报告》,重点评估了国内外43个大模型,在中文环境下的理科、文科和高难度Hard任务上的综合能力。本文将进一步分析国外模型在不同维度下的详细表现。
在线完整报告地址(可下载):
www.cluebenchmarks.com/superclue_2410
SuperCLUE排行榜地址:
www.superclueai.com
#国外大模型总体表现
分析1:OpenAI和Anthropic的系列模型在中文环境下是全球最好的两个系列模型。
10月SuperCLUE基准测评涵盖了16个代表性国外大模型。国内大模型金牌平均线为10月测评中取得金牌的4个国内大模型的平均值。
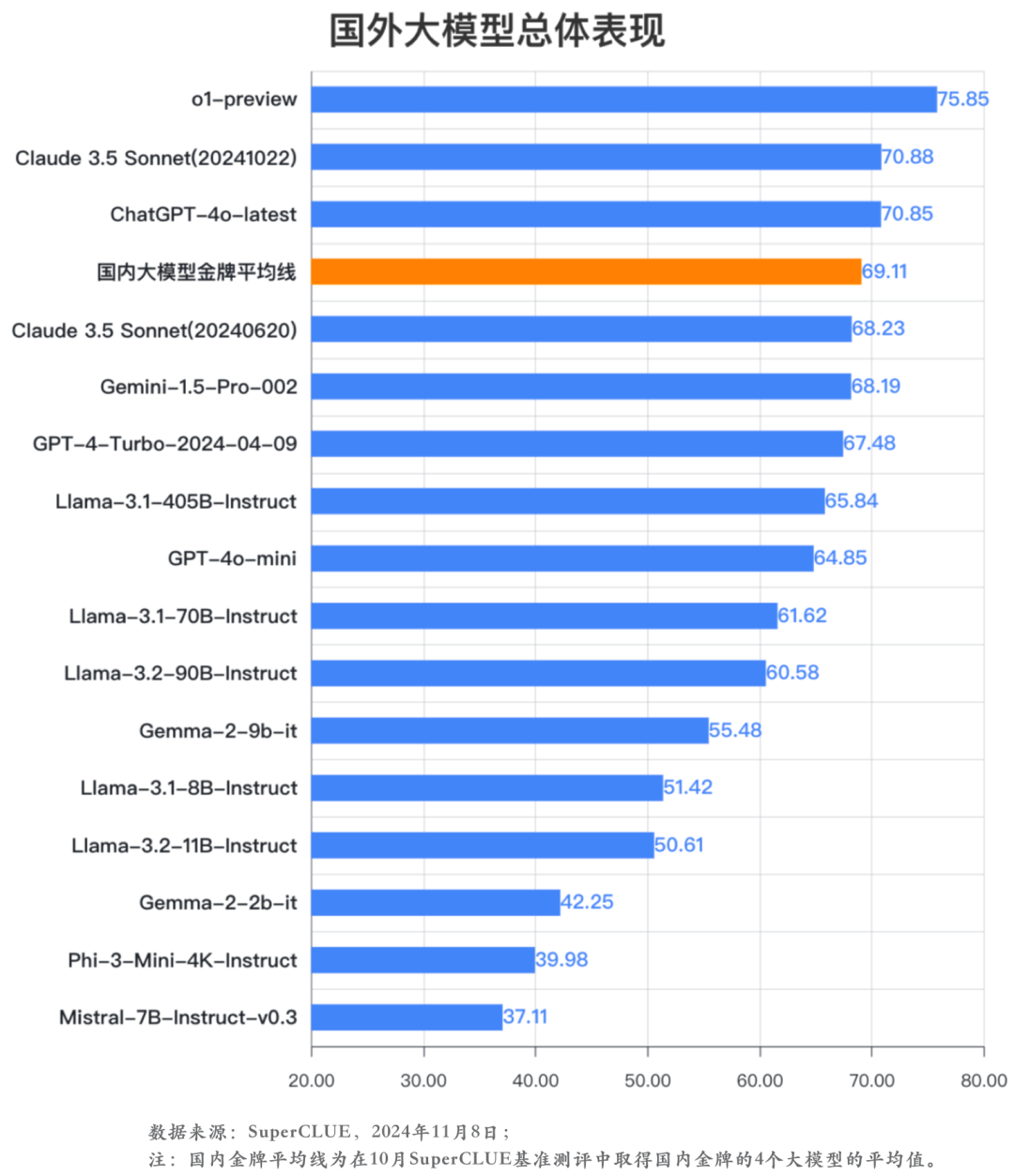
通过测评结果可以发现,OpenAI和Anthropic的模型在中文环境仍然是全球最好的大模型。其中,o1-preview取得总分75.85分,有较大领先优势。Claude 3.5 Sonnet(20241022)和ChatGPT-4o-latest表现相当,均有超过70分的表现。国内大模型金牌平均线稍落后于ChatGPT-4o-latest。与此相比,Gemini系列和Llama系列模型则在中文场景下表现相对较弱。
我们将国内外头部大模型的12项基础能力表现绘制了雷达分布图。
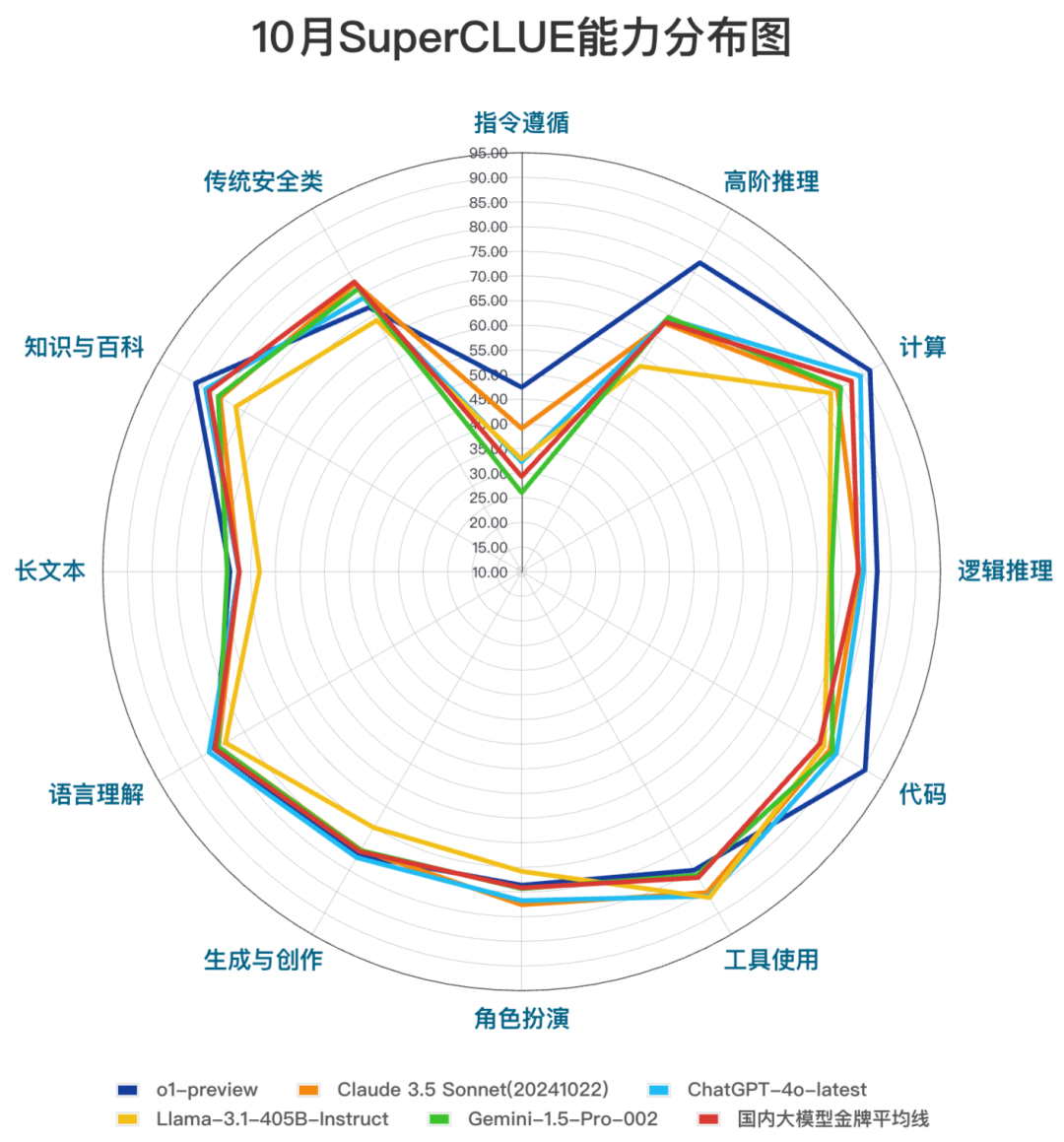
可以发现,在指令遵循、高阶推理、计算、逻辑推理、代码能力上,海外模型有较大领先性。在文科属性较强的任务上,国内外模型表现相当。
#国外大模型Hard任务表现
分析2:中文高难度Hard任务上,o1-preview大幅领先。
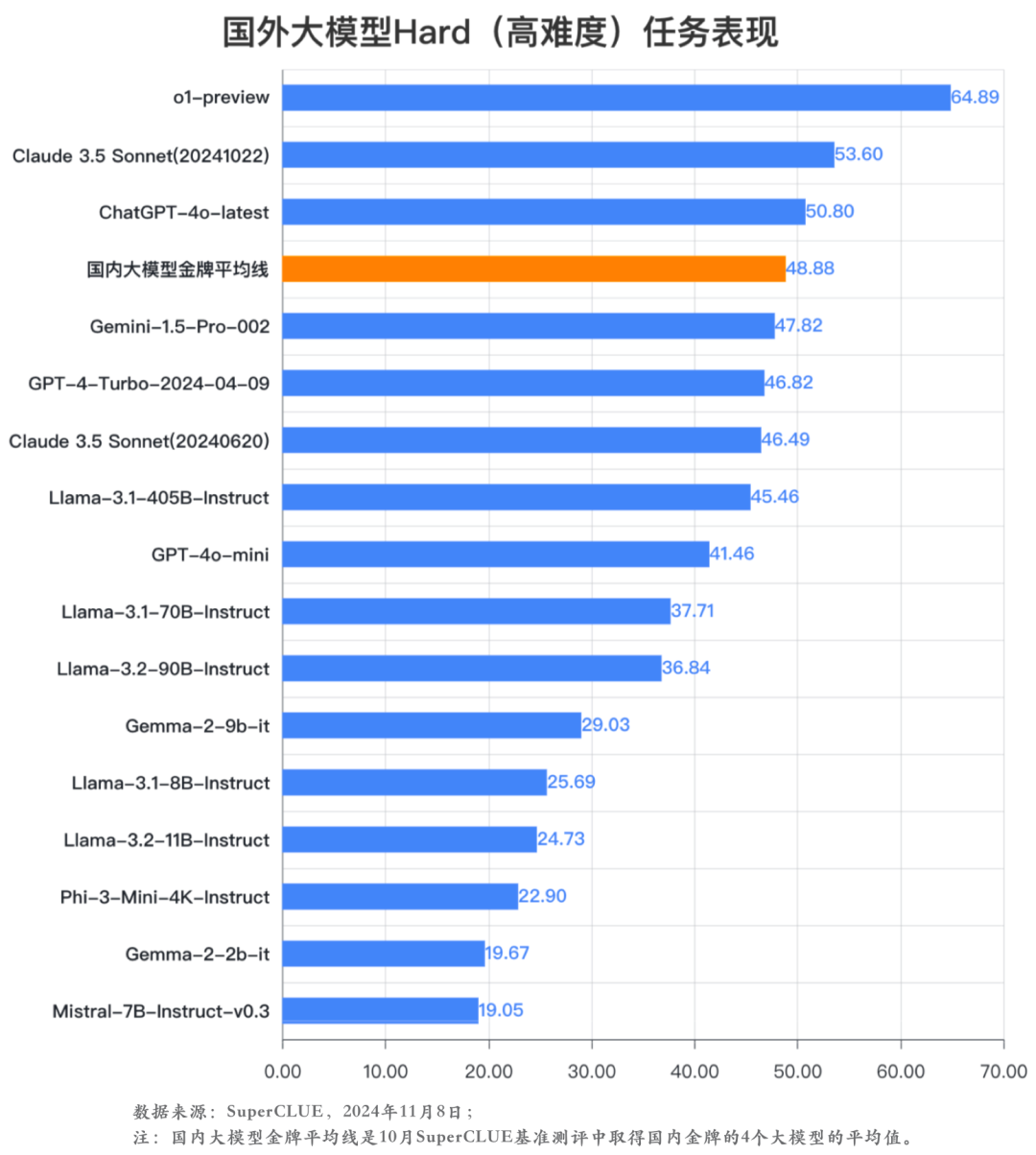
在中文高难度Hard任务(高阶推理和精确指令遵循)上,o1-preview大幅领先。排名第二档的Claude 3.5 Sonnet(20241022)和ChatGPT-4o-latest有超过50分的表现,其余国内外模型均低于50分。
分析3:中文理科任务上,国外头部大模型相对领先,但区分度不大。
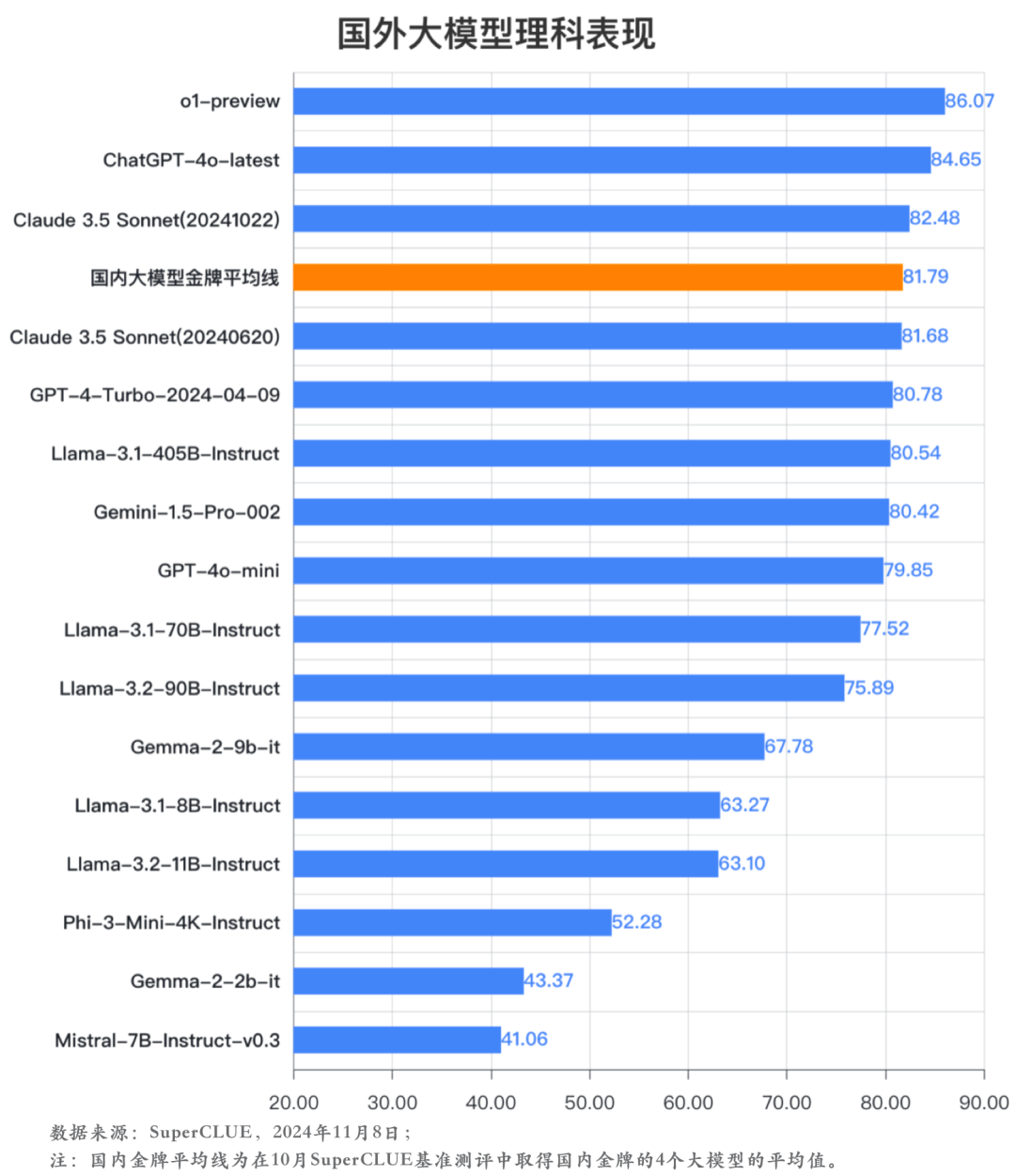
在中文理科任务上,o1-preview小幅领先。ChatGPT-4o-latest、Claude 3.5 Sonnet(1022)和国内大模型金牌平均线表现紧随其后。目前全球头部大模型在基础理科能力上,如计算、代码等能力上区分不明显。
分析4:文科任务上,国内外头部大模型总体无明显差异。
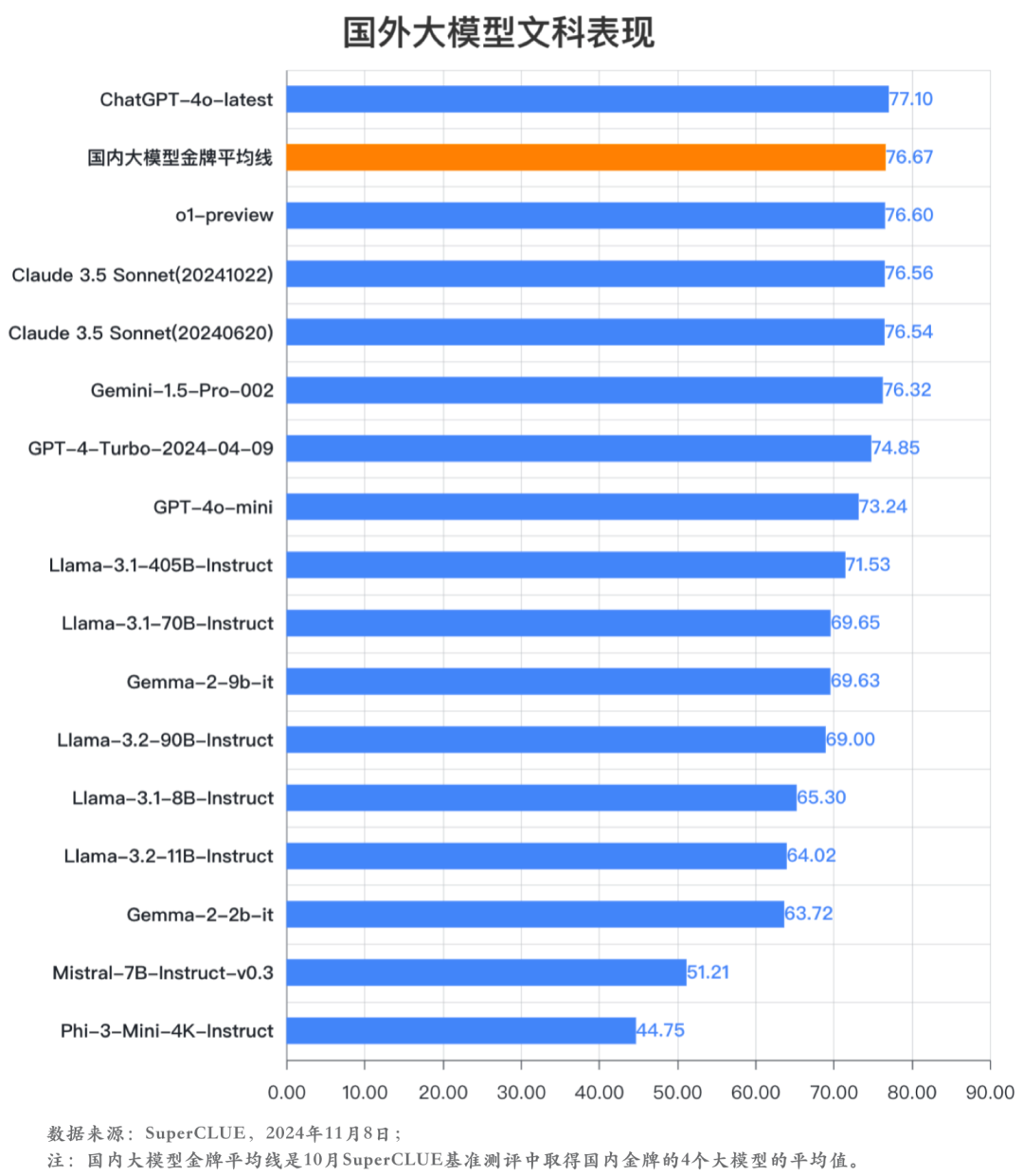
在文科任务上,国内外头部大模型均处于70-80分之间,总体上无明显差异。

报告完整详细内容,可点击文章底部【阅读原文】查看高清完整PDF版。
在线完整报告地址(可下载):
www.cluebenchmarks.com/superclue_2410
更多10月SuperCLUE基准报告详情,可加入交流群。


扩展阅读
[1] CLUE官网:www.CLUEBenchmarks.com
[2] SuperCLUE排行榜网站:www.superclueai.com
[3] Github地址:https://github.com/CLUEbenchmark/SuperCLUE
[4] 报告地址:www.cluebenchmarks.com/superclue_2410
![]() 点击阅读原文,查看完整报告
点击阅读原文,查看完整报告


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









