







本实验源自该开源项目需求
https://github.com/yds086/HereticOS
实验环境
OS : Centos 7.1
Kernel: 4.6.0
CPU : Intel(R) Xeon(R) CPU E5-2620 v2 @ 2.10GHz (开启超线程)
MEM : 48G DDR3
修改如下系统参数以创建尽量多的线程
/proc/sys/kernel/pid_max #操作系统线程数限制
/proc/sys/kernel/threads-max #操作系统线程数
max_user_process(ulimit -u) #系统限制某用户下最多可以运行多少进程或线程
ulimit -s 512 #修改线程栈大小
/proc/sys/vm/max_map_count #单进程mmap的限制会影响当个进程可创建的线程数
/proc/sys/kernel/threads-max 这个值需要注意下:
4.6.0的内核中,该值:
threads = div64_u64((u64) totalram_pages * (u64) PAGE_SIZE,
(u64) THREAD_SIZE * 8UL);即48GB的内存,可以创建的threads-max为:
totalram_pages = 49432356KB/4KB = 12358089
threads = 12358089*4kB / (8kB * 8) = 772380
理论上可已得到应该是772380的线程数目,但不知为何,实际threads-max参数最多可以设置到772380/2 = 386190
伪代码
//任务模式
long long g_SleepIoCount=0;
long long g_SleepIoLastCount=0;
void IOTask()
{
for(;;)
{
Sleep(100);// 100 ms 1000ms 10000ms
g_SleepIoCount++;
}
}
void TestIo()
{
//创建一组并发任务
CreatTask(IOTask,1000000);
//监测IO计数
for(;;)
{
Sleep(3000)//3s统计一次
printf("Sleep Iops %d",(g_SleepIoCount-g_SleepIoLastCount)/3);
}
}测试代码
#define _GNU_SOURCE
#include <stdio.h>
#include <string.h>
#include <pthread.h>
#include <stdint.h>
#include <time.h>
#include <unistd.h>
#include <sys/syscall.h>
uint32_t g_sleep_ms = 0;
uint32_t g_threadcnt = 0;
uint32_t g_running_threadcnt = 0;
uint64_t g_SleepIoCount = 0;
int32_t g_main_bind = -1;
int32_t g_task_bind = -1;
#define USE_CORE_BIND 1
#define MSLEEP(x) usleep(1000 * (x))
#define ATOMIC_FETCH_AND_ADD(ptr,value) __sync_fetch_and_add((ptr), (value))
void *sleep_task(void* para)
{
if (g_task_bind >= 0)
{
cpu_set_t mask;
CPU_ZERO(&mask);
CPU_SET(g_task_bind, &mask);
if (pthread_setaffinity_np(pthread_self(), sizeof(mask), &mask) < 0)
{
printf("Bind to Core Error !\n");
return NULL;
}
}
ATOMIC_FETCH_AND_ADD(&g_running_threadcnt, 1);
while(1)
{
MSLEEP(g_sleep_ms);
ATOMIC_FETCH_AND_ADD(&g_SleepIoCount, 1);
}
}
static inline pid_t gettid(void){
return syscall(SYS_gettid);
}
void execute_cmd(const char *cmd, char *result)
{
char buf_ps[1024];
char ps[1024]={0};
FILE *ptr;
strcpy(ps, cmd);
if((ptr=popen(ps, "r"))!=NULL)
{
while(fgets(buf_ps, 1024, ptr)!=NULL)
{
strcat(result, buf_ps);
if(strlen(result)>1024)
break;
}
pclose(ptr);
ptr = NULL;
}
else
{
printf("popen %s error\n", ps);
}
}
void print_process_info(void)
{
char cmd_string[128] = {0};
char cmd_result[128] = {0};
pid_t my_pid = gettid();
memset(cmd_string, 0, sizeof(cmd_string));
memset(cmd_result, 0, sizeof(cmd_result));
sprintf(cmd_string, "cat /proc/%u/status | grep VmRSS | cut -d : -f 2 | tr -cd \"[0-9]\"", (uint32_t)my_pid);
execute_cmd(cmd_string, cmd_result);
printf("Current Process Used %s physical memory !!!!\n", cmd_result);
memset(cmd_string, 0, sizeof(cmd_string));
memset(cmd_result, 0, sizeof(cmd_result));
sprintf(cmd_string, "cat /proc/%u/status | grep VmSize | cut -d : -f 2 | tr -cd \"[0-9]\"", (uint32_t)my_pid);
execute_cmd(cmd_string, cmd_result);
printf("Current Process Used %s virtual memory !!!!\n", cmd_result);
memset(cmd_string, 0, sizeof(cmd_string));
memset(cmd_result, 0, sizeof(cmd_result));
sprintf(cmd_string, "cat /proc/%u/status | grep Threads | cut -d : -f 2 | tr -cd \"[0-9]\"", (uint32_t)my_pid);
execute_cmd(cmd_string, cmd_result);
printf("Current Process Used %s threads !!!!\n", cmd_result);
sleep(3);
return ;
}
void main(int argc, void* argv[])
{
if (argc != 5)
{
printf("Usage:$s thread_cnt sleep_ms main_bind task_bind \n", argv[0]);
return;
}
g_threadcnt = atoi(argv[1]);
g_sleep_ms = atoi(argv[2]);
g_main_bind = atoi(argv[3]);
g_task_bind = atoi(argv[4]);
if (g_main_bind >= 0)
{
cpu_set_t mask;
CPU_ZERO(&mask);
CPU_SET(1, &mask);
if (pthread_setaffinity_np(pthread_self(), sizeof(mask), &mask) < 0)
{
printf("Main Bind to Core Error !\n");
return;
}
}
int ret = 0;
uint32_t i;
pthread_t thread;
for (i = 0; i < g_threadcnt; i++)
{
if (i % 5000 == 0)
{
printf("Already create %d threads ....\n", i);
}
ret = pthread_create(&thread, NULL, &sleep_task, NULL);
if (0 != ret)
{
printf("[ERROR]Create thread error, index:%d, ret:%d!!!\n", i, ret);
return;
}
}
//waiting for thread all running
while (g_running_threadcnt != g_threadcnt)
{
printf("Running:%d - Total:%d \n", g_running_threadcnt, g_threadcnt);
sleep(1);
}
printf("All the %d threads is running ....\n", g_running_threadcnt);
print_process_info();
//excute the test
uint64_t last_cnt = 0;
int test_cnt = 0;
for (; test_cnt < 50; test_cnt++)
{
sleep(3);
if (test_cnt != 0)
printf("Sleep Iops %d \n",(g_SleepIoCount-last_cnt)/3);
last_cnt = g_SleepIoCount; // maybe not accurate ...
}
print_process_info();
return;
}
test:pthreadtest.c
gcc -g -O3 -o test ./pthreadtest.c -lpthread
clean:
rm -rf ./test
测试场景
单一核心上可以同时运行的最大线程数目
运行 ./test 325000 1000 1 2 , 即创建325000个线程,每个任务线程sleep 1s,同时主进程绑定在核心1上,任务线程均绑定在核心2上。

可以看出,主进程很快就创建完了325000个线程,但由于这些线程均绑定至核心2上,并且已经运行的线程只sleep 1s,导致需要运行的线程得不到时间片。
(用岛主的话说:“那就是被io上限约束了吧, 再创建的都饿死,而不是都给点饭吃吗”)
结论: 经过测试,本实验环境下,在sleep 1s情况下,创建24w左右的线程可为极限。
单一进程进行核心绑定,得出单核的qps极限值
运行./test 26000 100 1 2

调整创建的线程数目,发现大于26000的线程后,创建线程将变的困难,和测试场景1属于同样的问题。
结论: 经过测试,本实验环境下,在sleep 100ms情况下,单核qps极限值为25w左右,此时任务核心cpu跑满100%
同样的,时间扩大1倍至1s,线程数目扩大至250000,结果如下:(线性扩大至260000时,程序响应慢)

结论: 经过测试,本实验环境下,在sleep 1000ms情况下,单核qps极限值为24w左右,此时任务核心cpu跑满100%
我的环境下/proc/sys/kernel/threads-max最多30w左右(内存限制),导致无法测试10s的情况
同时运行多个进程,并进行核心绑定
同时执行./test 26000 100 1 2 和 ./test 26000 100 3 4


测试结果:多核心的cpu,在此种测试结果下,qps基本成线性增加,(同时在物理核和超线程核心,会有一定影响)
将运行线程和sleep时间同时扩大10倍,即同时运行./test 240000 1000 1 2 和 ./test 240000 1000 3 4: 测试结果如下

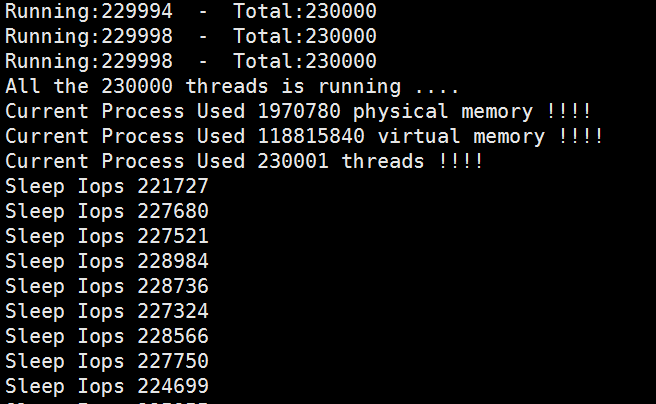
测试结果:多核心的cpu,在此种测试结果下,qps基本成线性增加,(同时在物理核和超线程核心,会有一定影响)
单一进程,不进行核心绑定
不进行核心绑定,由linux默认进行调度,理论上应该是25w * 12 的qps,在我的12核心cpu实验环境下得到如下结果:
运行 ./test 190000 100 -1 -1
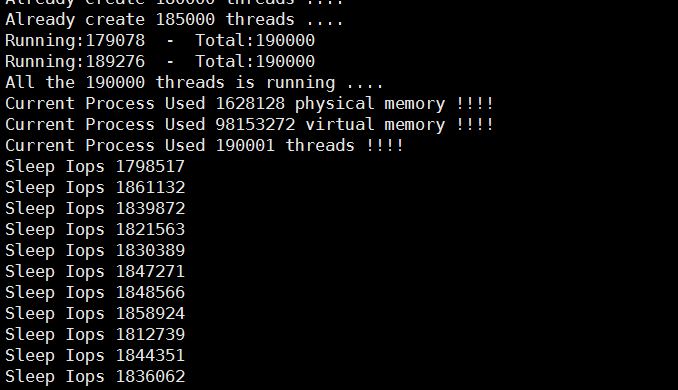
此时的cpu基本跑满

如前述所说,和超线程也有一定的关系,所以并不一定是完全线性的。
测试结果:19w的线程,sleep 100ms,基本可以达到190w的qps,再进一步创建线程比较困难。
测试结果:19w的线程,sleep 100ms,基本可以达到190w的qps,再进一步创建线程比较困难。
测试汇总
| 任务数 | sleep 100ms | sleep 1000ms |
| 26000 | 25w qps | |
| 250000 | 24w qps | |
| 180000 | 180w qps |
相关结论:
1)单个cpu核心的qps,可达25w qps;
2)多核心cpu,qps可扩展,基本符合线性,但超线程需关闭















 645
645

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









