






1.项目背景和算法简介
点我达是一家致力于提供城市即时物流配送服务公司。在餐饮外卖行业,商家从接受外卖订单到做出餐品做并打包完毕所需要的时间,称为出餐时间。实现准确预测该时间,可以让派单系统确定合理的派单时间,对于出餐慢的订单,可以延迟派单,从而减少配送员在商家的等餐时间,提升配送员的体验,提高配送效率。
本项目的内容是提供在线预测出餐服务,为调度系统提供订单的出餐时间。项目上主要围绕两个问题进行设计和开发:1、模型如何训练。在训练数据集很大的情况下,是否可以训练出模型,训练的过程是否高效。2、模型如何部署上线。应用服务开发主要用JAVA语言的情况下,是否能够对训练好的模型进行封装,便捷的提供在线预测服务。
机器学习的算法中,决策树算法和集成算法是两个比较重要的大类。在决策树算法中,采用不同的分枝方式,会衍生出不同的决策树。回归决策树算法是其中一种用于回归预测的算法。集成算法是用一些相对较弱的学习算法独立的就同一份数据训练出多个模型,然后把模型结果整合起来的算法,它同样包含了多个算法。XGBoost算法是GBDT算法的一种高效C++实现,是上述的回归决策树和集成算法的组合。
不同于传统的GBDT方式,只利用了一阶的导数信息,XGBoost对损失函数做了二阶的泰勒展开,并在目标函数之外加入了正则项整体求最优解,用以权衡目标函数的下降和模型的复杂程度,避免过拟合。除此以外,XGBoost还有一些优点:速度快,可移植,容错好等特点。这些优良的特性,使得XGBoost成为kaggel比赛的利器,同时在数据挖掘中有广泛的应用。最让人高兴的是,XGBoost项目有着非常完善的兼容性,在C++版本的基础上,不但做了JVM版本的实现,同时还和Spark、Flink做了整合。这为前文提及的关于本项目的两个主要问题提供了设计和开发的基础。
本篇会围绕项目工程实现这一主题,对项目中使用XGBoost实现模型训练和在线预测进行介绍。机器学习项目的其中的特征提取和数据处理工作,如数据清洗、特征提取,同事已经在另一篇机器学习在出餐时间预测上的探索中详细论述了,本文会在流程方面稍稍提及,不再详细介绍。
2.项目整体架构设计
整体的项目设计架构如下:
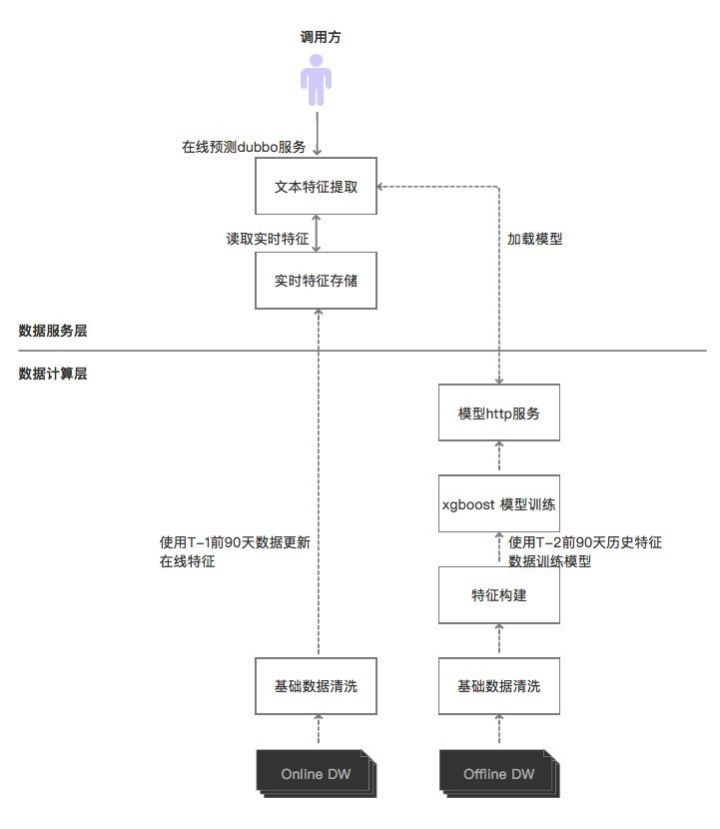
如上图示,整体架构若按大数据架构进行分层,可分为数据计算层和数据服务层。数据计算层主要是一些数据计算任务,这些计算任务包括离线数据仓库的离线计算,以及实时数据仓库的实时计算。数据服务层,是指用接口服务的形式提供加工完成的数据或模型。鉴于本项目属于机器学习项目,我们把项目的整体架构划分为离线训练模型和在线预测服务两部分,以便于介绍。在上图中,离线训练模型从Offline DW开始,至提供模型http服务结束。其余部分属于在线预测部分。
2.1离线训练模型
离线数据仓库(offline DW)是公司所有离线数据产品的基础,也是进行离线模型训练数据的来源。离线训练模型过程,首先从离线数据仓库数据提取,经过系列数据处理流程(数据清洗和特征提取),到完成训练模型并更新模型Http服务结束。离线数据仓库中的数据首先会进行汇总,生成一张宽表,在宽表的基础上按模型制定的清洗规则对数据进行清洗,并提取出各类指标。经过试验选取对模型有影响的指标用于模型的训练,这类指标称为特征。构建出特征数据后,使用Spark版本的XGboost进行训练,训练过程我们遇到了一些问题,走了弯路,这点后面会讲到。模型训练完成后,会生成XGBoost自有的二进制模型文件。我们把该文件存放于Http服务上供在线服务系统加载。
2.2在线预测服务
在线预测,就是指把训练好的模型部署在线上应用系统中,提供预测接口和服务供其他应用系统调用。在线预测最关键的是特征的构建。出餐预测服务的输入特征使用点我达实时处理系统进行实时构建,其处理流程和架构如下图:
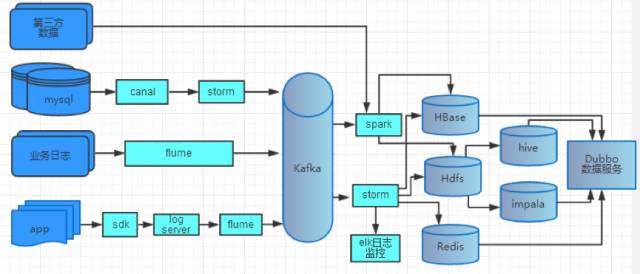
点我达实时处理系统会从通过各类实时采集组件采集到kafka中,然后使用spark/storm构建实时数据仓库(online DW)。再以实时数据仓库为基础,为各类实时需求提供数据支持。 在线预测服务还需要考虑的一点是,如何定期更新系统中的模型。模型的更新方式有主动定时拉取和被动推送两种方式。主动定时拉取方式优点是实现简单、资源消耗小,缺点是可控性小。而被动拉取方式反之。两种方式优缺点互补。基于点我达现有的服务基础框架,项目中选用了被动推送方式进行更新。
3.项目实施过程介绍
3.1 xgboost实现和安装介绍
XGBoost算法是在GBDT的基础上对boosting算法进行改进后的实现,内部使用的是决策树,决策树的具体选择可以是回归树(回归问题),也可以是分类树(分类问题)。单机版实现的核心代码使用C++开发完成。在C++版本的基础上,提供了Python、JAVA、Spark等版本的接口,但底层仍是调用C++模块实现,其余版本的接口只是做了一层Wripper。
算法的核心是建立决策树,单机版建树的计算逻辑如下:
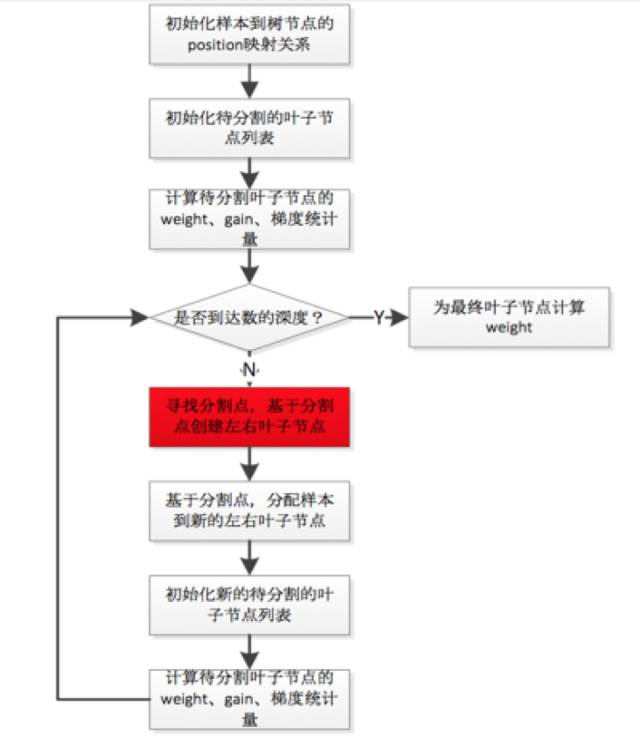
建树过程是顺序从根节点开始,先选择可以作为叶子结点的特征,然后计算分割点,依次迭代直至树的最大深度。每次选择叶子结点,会并行的计算样本的所有特征的,然后选择gain或者weight等最大的特征作为结点。这个并行的特性,使得单机版的XGBoost训练效率很高。
Spark版本的建树逻辑基本和单机版一致,计算上区别在于:并行的特征计算在不同的服务器上进行,计算结果需要通过消息在Tracker(负责控制计算逻辑)上进行汇总。Spark版本的消息使用rabit(dmlc的开源通信框架)通信,该框架提供了容错的Allreduce and Broadcast的MPI接口。Spark版本的整体架构逻辑图如下:
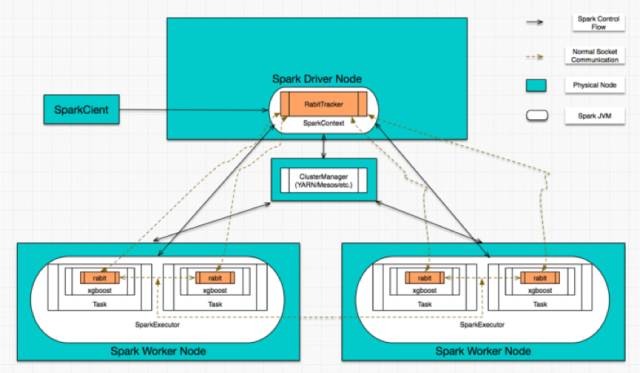
由于本项目的训练数据量较大,因而使用Spark版本进行离线训练模型;鉴于公司使用JAVA的背景下,使用JAVA版本的接口提供服务。
对于这两个版本的安装,都需要完成两个步骤:首先,编译生成xgboost的C++版本的依赖,生成目标是libxgboost.so(linux/osx)或者libxgboost.dll(windos平台)两个文件。Spark版本依赖于Java版本,在C++版本的基础上,使用maven package生成JAVA版本,然后基于Java版本编译Spark版本XGBoost包。
XGBoost官方手册(https://xgboost.readthedocs.io/en/latest/build.html)提供了c++版本安装指导和trouble shot。基于经验,在osx和linux平台上,需要先确认一下config.mk文件的gcc版本配置选项,该选项需要和操作系统的gcc版本保持一致。Xgboost的Java模块和Spark模块在jvm-packages目录下,模块使用MVN进行管理,打包和部署非常方便。
3.2 数据清洗和特征提取
数据清洗,会把作弊数据、异常数据等进行过滤,例如某些餐厅是快餐店,在接单以后不需要进行烹饪,也就是没有出餐时间,需要排除在训练数据之外。
特征方面,此项目的特征可以分为两类:一类是通过简单汇总聚合计算而生成,包括商家,骑手等类别。另一类是使用复杂的特征提取方式而得到,如餐品内容。因为不同食物的烹饪时长,直接决定了出餐需要的时间。用户的订单内容,即文本特征,如蛋炒饭、包子等,是出餐预测的重要特征。 提取完成特征后,把它和目标的相关性进行分析,是一块重要的内容。
以上的特征提取方面的详细工作,请参考前文提及的另一篇文章。
3.3 Spark XGBoost训练过程分析
数据清洗好以后,需要把数据进行初始化Spark mllib模型的通用数据结构。通用数据结构可以使用ml和mllib两类接口进行操作。其中,mllib提供RDD-based的接口,ml对应的是DataFrame-based的接口,而两种接口都有各自的输入向量实现,实现的向量也都分为稀疏向量和稠密向量。
针对mllib两类接口,XGBoost分别提供了XGBoost.trainWithDataFrame() 和XGBoost.trainWithRDD()两个训练接口。trainWithDataFrame只是trainWithRDD的Wrapper,其接口内部最终还是调用XGBoost.trainWithRDD()执行训练。trainWithRDD方法内部会检查cpu、nWorkers等参数,并完成资源分配计划。接着启动rabit tracker(用于管理实际计算的rabit worker),调用buildDistributedBoosters进行分布式初始化和计算。
buildDistributedBoosters方法先根据参数nWorkers对数据进行repartition(nWorkers)操作,进行数据重分布,接着,直接调用mapPartion进行partition层面的数据逻辑处理。可以看出,nWorkers决定了最终数据的partition情况,以及rabit worker的数量。在RDD partition内部,数据会先进行稀疏化处理,然后再转为JXGBoost接受的数据结构。接着,启动rabit worker 和JXGBoost进行训练。至此spark 的分布式模型转化为JXGBoost的分布式训练。从结果上看,spark就像是数据和资源管理的框架,核心的训练过程还是封装在rabit中。上述的接口调用的整体流程如下图:
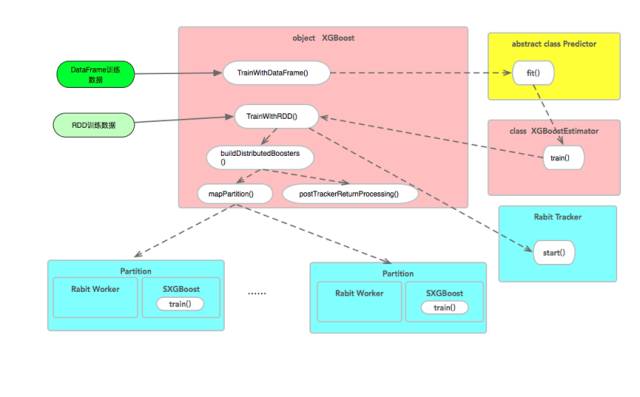
上述分析的内容,结合3.1中的架构逻辑图,基本覆盖了实际使用XGBoost中会遇到问题的范围,JXGBoost部分就不进行分析了。XGBoost训练过程中会输出每一轮的估算结果。依据结果的变化,调参上提供很大的参考。在训练数据的构建上可以参考如下的代码:
val testTrainDF = spark.createDataFrame(Seq(
(1.0, Vectors.sparse(3,Seq((1,2d),(0,4d)))),
(0.0, Vectors.dense(3.0, 2, -0.1)),
(1.0, Vectors.dense(0.2, 2.2, -1.5))
)).toDF("label", "features")
val xgboostModel = XGBoost.trainWithDataFrame(testTrainDF, paramMap, numRound,nWorkers=1, useExternalMemory = fal
se) model.write.overwrite().save(modelPath)
训练完成的模型会直接保存在HDFS的path目录下,该模型文件可以被其他语言版本的XGBoost加载。
3.4 在线服务模型跟新
为了保证预测的准确性,在线接口需要定期更新训练好的模型文件。XGBoost提供了直接加载本地文件和Stream加载两种方式用语更新模型。 而在线预测服务部署在多台服务器上,考虑读取模型的便利性,笔者搭建了模型文件的HTTP服务,该HTTP服务直接构建于HDFS上。更新的过程如下:首先模型训练进程在训练完成后,主动更新zookeeper上的更新标示,用于通知在线预测服务拉取新模型进行更新。在线接口服务watch 到zookeeper的变化后,读取http服务,获取新的模型文件,然后更新服务中的模型对象。结构图如下:
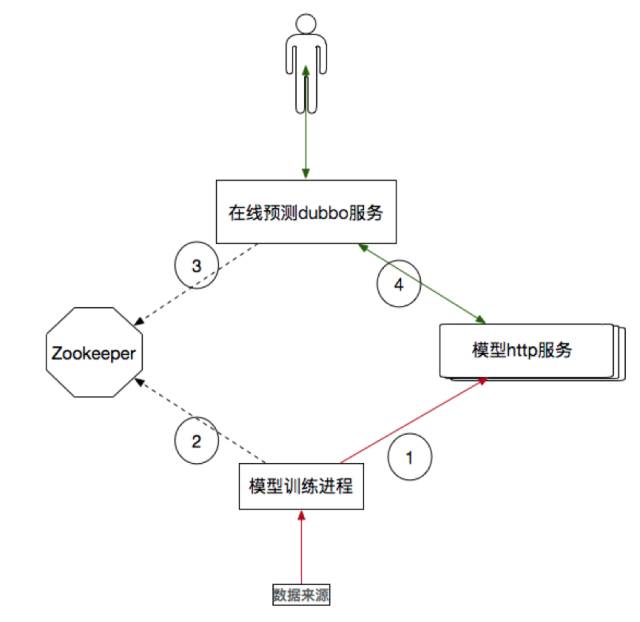
圆圈内所标注的是处理逻辑的先后顺序。
接口服务加载模型代码上有一个小注意点:新加载的对象先使用新的java引用,等模型加载好以后,提供服务的引用再链到新的对象上,保证预测响应时间的稳定性。目前预测服务的响应时间稳定在5ms左右。
3.5 在线预测特征构建和接口设计
在线预测的过程是输入一组特征给模型,模型返回一个Lable作为预测结果。这个过程中,重点在于如何构建输入模型的这一组在线预测特征。在线预测特征与模型训练的特征项基本一致,区别点在于,预测特征需要根据接口的输入信息实时生成。细分在线预测特征中的维度,可以分为两类:一类是根据输入信息,直接生成特征维度,例如文本特征可以根据餐品信息处理生成,另一类,是实时计算生成的维度,比如按天更新的商家的一月累计平均信息。
第一类维度在服务内部处理后就可以的生成,实现上并不困难。第二类维度需要从实时数据仓库中实时的提取特征,并进行存储,不同纬度相差教大。本项目使用streaming 实时进行计算,以redis作为该类特征存储的容器,存储的结构上是以商家为key,特征为value。
基于以上的特征存储设计,使得在线服务接口的入参只需要商家id和餐品信息两个特征,其余特征根据商家id和当前时间从redis获取。组装好的特征需要封装为DMtrix作为入参,调用Booster.predict预测方法,获得模型的返回值。示例代码:
Booster newBooster = XGBoost.loadModel(is)DMatrix mat = new DMatrix(vectorFloat,rows,columns,Float.NaN);
float[][] predictResult = booster.predict(mat);
模型返回精确到分钟的出餐时长,即为接口的返回值。
4.总结
本文主要对XGBoost算法实现和点我达在线出餐预测服务的设计作了大概的分享,侧重点在于软件工程相关方面。XGBoost算法在兼容性和计算速度方面很优秀,而且算法决策树包含了回归树和分类树,使得算法的适用性很高,可应用于很多场景。出餐预测的服务已经应用于调度系统中,效果稳定。今后,出餐预测还会在模型训练和特征提炼两个方面不断优化,包括模型训练实时化、使用模型组合算法、使用tensorflow深度学习框架进行文本挖掘等。机器学习是一门综合性很强的技术,若想用好它,需要保持不断尝试和探索的精神。
这个世界正在奖励默默努力的人

推荐阅读:
python 数据清洗篇(上)
python 数据清洗篇(下)
(视频讲解!!!)python量化 | 10年翻400倍的炒股策略














 1189
1189











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









