






1、010editor
官网下载:https://www.sweetscape.com/download/010editor/
010editor 15.0.1:https://www.52pojie.cn/thread-1863194-1-1.html
宇宙最强 010 Editor 模板开发教程(附带示例):https://bbs.pediy.com/thread-257797.htm
打开 010 Editor,按 F1 即可查看 帮助文档,下面都是从里面截取的
010 Editor 是什么
010 Editor 是一款专业的文本和十六进制编辑器,同时也是最强大的十六进制编辑器。其旨在快速轻松地编辑计算机上任何文件的内容。该软件可以编辑文本文件,包括 Unicode 文件、批处理文件、C/C++、XML 等,而在编辑二进制文件中,010 Editor 有很大的优势。二进制文件是一种计算机可读,但人很难读懂的文件 (二进制文件如在文本编辑器中打开将显示为乱码)。十六进制编辑器是一种程序,它允许您查看和编辑二进制文件的单个字节,以及包括 010 Editor 的高级十六进制编辑器还允许您编辑硬盘驱动器、软盘驱动器、内存密钥、闪存驱动器、CD-ROM、进程等中的字节。010 Editor 的一些优点:
- 查看和编辑硬盘上的任何二进制文件(文件大小不受限制)和文本文件,包括 Unicode 文件、C/C++、XML、PHP、Ruby、JSON 等。
- 独特的二进制模板技术允许你了解任何二进制文件 格式。
- 具有使用 Tree-sitter 对源代码进行实时语法解析的功能。
- 查找并修复硬盘驱动器、软盘驱动器、内存密钥、闪存驱动器、CD-ROM、进程等的问题。
- 用强大的工具包括查找、替换、多文件中查找、多文件中替换、二进制比较、校验和/哈希算法、直方图等,来分析和编辑文本和二进制数据。
- 反汇编二进制数据。
- 强大的脚本引擎允许多任务的自动化(语言非常类似于 C)。
- 轻松下载并安装其他使用 010 Editor 存储库共享的二进制模板和脚本。
- 以不同的格式导入和导出二进制数据。
在 010 的官网上已经有仓库存放了大量的 "脚本、模板" 库可以使用
- 官网脚本:https://www.sweetscape.com/010editor/repository/scripts/
- 官网模板:https://www.sweetscape.com/010editor/repository/templates/
4 种数制系统使用的列表:
- 十进制 - 数字表示为底数 10。数字可以是从“0”到“9”的任何数字。例如,在十进制中 153 = 1*102 + 5*101 + 3。
- 十六进制 - 数字表示为底数 16。使用所有十进制数字, 加上字母 "a"、"b"、"c"、"d"、"e" 和 "f" 来表示数字 10 到 15。例如, 在十六进制中 3d7 = 3*162 + 13*161 + 7 = 983。这个系统通常被称为十六进制。
- 八进制 - 数字表示为底数 8。仅使用数字 "0" 到 "7" (不允许使用 "8" 或 "9")。例如, 数字 2740 = 2*83 + 7*82 + 4*81 + 0 = 1504。
- 二进制 - 数字表示为底数 2。只能使用数字 "0" 或 "1"。例如, 数字 10110 = 1*24 + 0*23 + 1*22 + 1*21 + 0 = 22。
在文本字段中输入数字。在 010 Editor (大多数文本字段,检查器等) 中输入数字的任何地方,程序都支持多种不同格式的输入。通常,数字的格式假定为十进制 (某些字段旁边有十进制 和十六进制 切换 - 单击十六进制 切换将默认值设置为十六进制)。但是,可以使用特殊语法输入其他格式:
- 十六进制 - 在数字前使用 '0x' 或在数字后使用 ',h'、',x' 或 'h'。例如,'0x100' 或 '3f,h'、'd2,x' 或 'FFh' 表示十六进制数。
- 八进制 - 在数字后面输入 ',o'。例如, '377,o' 是八进制数。
- 二进制 - 在数字后面输入 ',b'。例如,'0101,b'是二进制数。
- 十进制 - 在数字后输入 ',d'。例如,'123,d' 是十进制数。
- 字符 - 可以通过在字符周围放置单引号来输入字符。例如,'A' 将转换为数字 65。使用 '\' 也支持大多数标准 C 转义序列。例如,'\n' 将转换为数字 10。
有关如何将字节组合在一起以使数字大于 255 的信息,请参见 字节序简介。脚本和模板中支持的数字格式略有不同。有关更多信息,请参见 模板和脚本简介。
计算机上的数据通常分为 8 位一组,称为字节 (参见 数制系统简介)。一个字节可以存储为 256 种不同的值,但要存储较大的数字, 必须将一组字节组合在一起。术语 "字节序" 是指如何将这些字节组合在一起。
- 小端字节序(Little Endian) - 在小端字节序系统中 (例如,Intel 机器),字节首先以最低有效字节存储。例如,十六进制字节 '2f 75 05' 实际上表示数字 0x05752f (十进制中的 357679)。'2f' 是最低有效字节,'05' 是最高有效字节。
- 大端字节序(Big Endian) - 在大端字节序系统中 (例如,Motorola 机器),字节首先存储最高有效字节。在同一个例子中,十六进制字节 '2f 75 05' 将代表数字 0x2f7505 (十进制中的 3110149)。
使用哪种字节序将字节转换为数字非常重要,而 010 Editor 中的每个文件都有一个字节序设置。在当前文件处于小端字节序模式时,小端 将出现在状态栏中,而大端 将在大端字节序模式下显示。大多数工具和检查器都使用该字节序设置。若要更改用于文件的默认字节序,可使用“视图 >字节序”菜单 ,或在状态栏中点击小端 或大端。010 Editor 可以根据文件扩展名自动设置字节序配置(参见使用编辑方式)。
- 小端字节序(Little Endian) - 在小端字节序系统中 (例如,Intel 机器),字节首先以最低有效字节存储。例如,十六进制字节 '2f 75 05' 实际上表示数字 0x05752f (十进制中的 357679)。'2f' 是最低有效字节,'05' 是最高有效字节。
- 大端字节序(Big Endian) - 在大端字节序系统中 (例如,Motorola 机器),字节首先存储最高有效字节。在同一个例子中,十六进制字节 '2f 75 05' 将代表数字 0x2f7505 (十进制中的 3110149)。
010 Editor 可以立即打开任何十六进制文件或驱动器。可以打开的文件大小没有限制,但某些文件系统 (包括 FAT) 将文件大小限制为 2 GB。所有操作都进行无限制的撤消和重做。无论复制、粘贴或删除的数据多大,都可以使用 Ctrl+Z 或 Ctrl+Shift+Z 执行撤消或重做操作。
快捷 方式
"快捷方式" 选项允许为 010 Editor 中的许多操作自定义快捷键 (也称为热键)。通过点击 "工具>选项... "菜单选项并从列表中选择 "快捷方式 "来访问快捷方式选项。
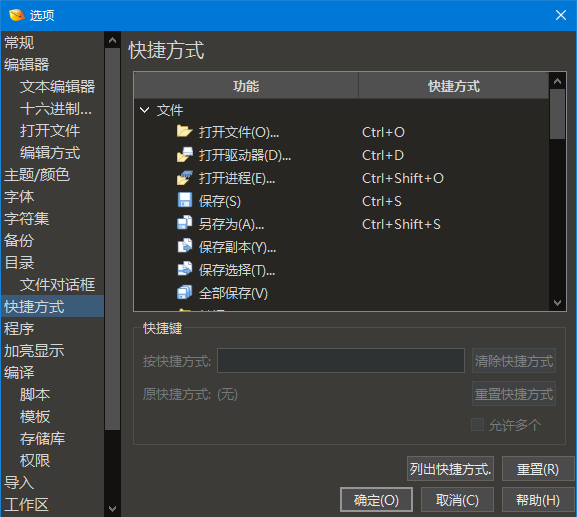
大多数快捷方式适用于整个应用程序,但请注意,"编辑器" 组中的快捷方式仅在文本编辑器或十六进制编辑器具有焦点时才处于活动状态。同样,"工具" 类别中的一些快捷方式,仅在比较结果表具有焦点且 (比较结果表) 显示在快捷方式列表中的这些快捷方式之后时,才处于活动状态。
单击 “重置” 按钮会将所有快捷键重置为其原始值。
单击 “列出快捷方式” 按钮显示应用程序中按快捷方式名称排序的所有快捷方式。仅当文本编辑器或十六进制编辑器具有焦点时,编辑器组中的快捷方式才处于活动状态,而“比较结果表”组中的快捷方式仅在比较结果表具有焦点时才处于活动状态。
文件 相关
Ctrl+O 打开文件
Ctrl+D 打开驱动器
Ctrl+shift+O 打开进程
Ctrl+S 保存
Ctrl+shift+S 另存为
Ctrl+W 关闭
Ctri+Alt+W 全部关闭
F6 恢复/刷新
Ctrl+N 新建文本文件
Ctrl+shift+N 新建16进制文件
视图 相关
Ctrl+H 切换16进制编辑方式,再次按下切换到之前的编辑方式
Ctrl++ 放大字体
Ctrl-- 缩小字体
Ctrl+Shift+F6 编辑语法文件
Ctrl+F6 刷新语法
Ctrl+Shift+\ 打印语法树
Ctrl+; 自动换行
Ctrl+Shift+; 显示空格
Ctrl+E 切换字节序
所有 快捷键

编辑文本文件时可以使用以下键:
- 左, 右, 上, 下箭头 - 将光标向任何方向移动。
- Ctrl+左箭头, Ctrl+右箭头 - 将光标移动到下一个或上一个单词。
- Ctrl+上箭头, Ctrl+下箭头 - 向上或向下滚动编辑器而不移动光标。
- Enter - 插入新行。
- Home - 将光标移动到行的第一个字符。
- End - 将光标移动到行的最后一个字符。
- Ctrl+Home - 将光标移动到文件的顶部。
- Ctrl+End - 将光标移动到文件的尾部。
- Ins - 切换插入和覆盖模式。
- Del - 从文件中删除当前字符。
- Ctrl+Shift+Backspace - 如果未选择任何字节,则删除当前行。如果选择了字节,则删除包含选择的所有行。
- Ctrl+Backspace - 如果没有选择字节,则删除前一个单词。
- Ctrl+Del - 如果没有选择字节,则删除下一个单词。
- Tab - 如果一次选择多行,则插入制表符或缩进行块。
- Shift+Tab - 如果选择了多行, 则此选项将取消选定行的缩进。
编辑 方式
编辑方式 是 010 Editor 中的一个重要概念。会为每个加载的文件分配一个编辑方式。常用的编辑方式是 "文本编辑、16进制编辑"。
当前文件的 "编辑方式" 名称会显示在状态栏中,点击状态栏中的名称会弹出一个列表,可以选择不同的 "编辑方式"。或者,也可以使用 "视图 > 编辑方式" 菜单选择不同的 "编辑方式"。
要创建新的编辑方式,可使用“视图 > 编辑方式> 创建新编辑方式”菜单 (有关详细信息,请参见视图菜单) 或编辑方式选项对话框。"视图 > 编辑方式 " 菜单包含所有可用编辑方式的列表,以及复选标记将放在当前活动的编辑方式旁边。
基本 编辑
16进制 编辑
十六进制编辑器窗口(如上所示)是在 010 Editor 中查看和编辑二进制文件的主要方法(要编辑文本文件可参见使用文本编辑器)。它为每个在编辑器中加载的二进制文件显示一个十六进制编辑器窗口。每个文件都显示在文件选卡中,该文件选卡显示文件名的缩写形式,但可以在应用程序标题栏中查看完整的文件名,也可以通过将鼠标光标放在文件选卡上来显示提示的弹出窗口。十六进制编辑器窗口分为左右区域。默认情况下,左侧区域将文件的字节显示为一系列十六进制字节,右侧区域将字节显示为一系列字符(如果字节不能显示为字符,则将显示为 '.')。在滚动条旁边的编辑器的最右侧,迷你地图将文件的字节显示为一组颜色。十六进制编辑器窗口左侧是地址列表。每个地址指示在行上第一个字节的文件位置。在窗口的顶部,标尺指示该行上的地址的字节偏移量。可以将编辑器更改为以多种不同格式显示数据,并修改十六进制编辑器窗口显示数据的方式,参见使用编辑方式。
编辑文件时可以使用以下键:
- 左、右、上、下箭头 - 将光标向任何方向移动。
- Ctrl+左箭头、Ctrl+右箭头 - 将光标移动到下一个或上一个字节组。
- Ctrl+上箭头、Ctrl+下箭头 - 向上或向下滚动编辑器而不移动光标。
- Home - 将光标移动到行的第一个字节。
- End - 将光标移动到行的最后一个字节。
- Ctrl+Home - 将光标移动到文件的第一个字节。
- Ctrl+End - 将光标移动到文件的结尾。
- Insert - 切换插入和覆盖模式。
- Delete - 从文件中删除当前字节。
- Tab - 在左右编辑区域之间切换。
- Alt+Up - 移动到硬盘驱动器中的上一个扇区。
- Alt+Down - 移动到硬盘驱动器中的下一个扇区。
自定义起始地址
通常二进制文件中的第一个字节位于地址 0,但可以通过单击“视图 > 地址 > 设置起始地址”将自定义起始地址分配给文件。
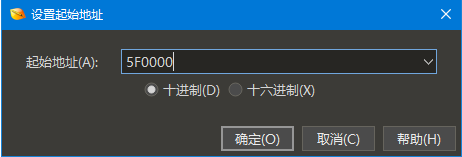
在如上所示的对话框中输入地址,然后单击十进制 以十进制形式输入地址,或单击十六进制 以十六进制形式输入地址。文件中的第一个字节现在将具有给定的地址,应用程序将使用该地址进行查找、转到、状态栏、模板结果等。起始地址也可以通过右键单击十六进制编辑器中的地址列,并选择“地址 > 设置起始地址”来更改。选择非零起始地址时,状态栏中会出现偏移量。单击偏移量 会显示一个弹出菜单,可用于更改偏移量或清除偏移量(将偏移量设置回零)。自定义起始地址与当前工作区一起存储。
还可以使用命令行或脚本中的 GetStartingAddress/SetStartingAddress 函数设置自定义起始地址。请注意,在编写脚本或模板时,函数仍将文件的第一个字节作为地址 0 访问,有关详细信息,请参阅本地坐标。
在导入文件开头包含空白区域的 Intel 十六进制或 Motorola S-Record 文件时,将在包含数据的第一个字节处自动为文件设置自定义起始地址。要关闭此功能,请使用导入选项对话框。
模板 执行 结果
在当前文件上运行二进制模板后,结果将显示在十六进制编辑器窗口底部的模板结果面板中。此面板有时是隐藏的,可以通过单击垂直滚动条下方的小按钮并向上拖动来显示。有关使用模板结果工作面板的更多信息,请参见使用模板结果工作。
将鼠标光标放在十六进制编辑器中与模板中变量相对应的字节上,这些十六进制字节就会高亮显示。弹出的提示也会显示有关变量的更多信息。如果变量是结构体的一个成员,那么整个结构体都会显示出轮廓
状态栏
状态栏位于应用程序底部,包含有关当前文件和编辑器当前状态的有用信息。 状态栏分为多个面板,其中大多数面板都可以单击以更改在编辑器中查看信息的方式,或控制以何种格式显示数据。根据正在编辑的文件类型,将显示不同的面板,下面显示的是底部文本文件的典型状态栏:

- 消息区 (A) - 显示有关最后完成的操作的信息。
- 文件位置/选择开始 (B) - 如果未选择字节, 则此组将显示文件中光标的当前地址。
- 当前字节/选择大小 (C) - 如果未选择字节, 则此组将显示光标所在字节的当前值。
- 文件大小 (D) - 显示正在编辑的文件的大小。
- 编辑方式 (E) - 显示为当前文件选择的编辑方式。
- 语法 (F) - (仅文本) - 显示为当前文本文件选择的语法加亮显示器。
- 字符集 (G) - 展示哪种字符集用于显示当前文件。
- 换行符 (H) - (仅文本) - 如果当前文件是文本文件,则显示当前的换行类型。
- 制表符 (I) - (仅文本) - 如果当前文件正在编辑为文本文件,则状态栏的此组将列出文件中每个制表位的字符数。
- 字节序 (J) - (仅十六进制或 Unicode) - 指示使用哪种字节序来解释当前文件。"小端" 表示小端字节序(例如:Intel 机器),"大端" 表示大端字节序(例如:Motorola 机器)。有关详细信息,请参阅字节序简介。010 Editor 可以在十六进制编辑器窗口中直观地交换字节,而无需修改基础数据。此交换仅在小端模式下发生,并且在启用交换时,此字段将显示 LIT<>(有关更多信息,请参阅交换字节)。
- 剪贴板 (W) - 共有 10 个剪贴板可用于复制和粘贴数据。此字段指示当前选择的剪贴板。"W" 表示默认 Windows 剪贴板处于活动状态,数字 "1" 到 "9" 表示用户剪贴板处于活动状态。有关更多信息,请参见使用剪贴板。
- 插入模式 (X) - 显示编辑器是处于 "插入" 还是 "覆盖" 模式。按 Ins 键或单击此状态栏区域可在两种状态之间切换。在编辑器中编辑数据时,或者从剪贴板粘贴数据时使用此模式 (有关详细信息,请参阅使用文本编辑器、使用十六进制编辑器和使用剪贴板)。编辑器窗口中的光标处于“覆盖”模式时将显示为粗线,处于“插入”模式时显示为细线。
停靠 窗口
010 Editor 主应用程序包含许多名为“停靠窗口”的特殊面板,例如工作区、资源管理器、检查器和输出窗口。这些“停靠窗口”可以移动到应用程序中的其他位置,作为一组选卡停靠在一起,或移动到自己的浮动窗口。esc 键可用于隐藏“输出”选卡。
重新安排停靠窗口有两种主要方法。
- 第一种方法是单击并拖动窗口顶部的 "停靠标题"。例如,对于上面的工作区,单击并拖动蓝色条,这样做会将所有停靠在一起的窗口作为选卡移动。动画将显示停靠窗口将移动到的位置,并释放鼠标按钮以完成停靠。
- 第二种方法是单击并拖动选卡名称 (在上图中为灰色工作区选卡)。这样做可以重新排列列表中的选卡,如果拖动选卡足够远,它将被拉出并变为单独的窗口。将停靠窗口移动到单独窗口的另一种方法是单击停靠标题中的向下箭头以访问停靠菜单 (如下所示) 并单击“浮动”。
重置 停靠 窗口
- 要将停靠窗口恢复到在首次安装 010 Editor 时的原始位置,可单击停靠标题中的向下箭头,然后从下拉菜单中选择“重置所有停靠”(参见上一节的图表)。
- 也可以在运行 010 Editor 时使用 -resetdocks 命令行选项重置停靠。
高级 编辑
编辑 进程
010 Editor 可以将任何当前正在运行的进程打开为界面中的文件。然后可以编辑进程使用的单个内存字节,并将其保存回进程。要打开一个进程,可使用“打开进程”对话框,该对话框可以通过单击“文件 > 打开进程...”菜单选项或按 Ctrl+Shift+O 来访问。也可以使用命令行来打开进程。
一旦在编辑器中打开了一个进程,就可以像编辑任何其他文件一样编辑它(参见使用十六进制编辑器)。由于进程的大小是固定的,因此不能在进程中插入或删除字节。对进程进行了修改后,单击“文件 > 保存”菜单选项将更改写回进程。如果进程已更改,或者您尝试修改只读区域,则在保存数据时会收到一个错误消息。
在 010 Editor 中加载进程后, 可以使用 "文件 > 另存为..." 或 "文件 > 保存副本..." 将进程的逐字节副本保存到磁盘 (这称为进程映像)。通过在编辑器中选择字节,并单击 "文件 > 保存选择..." 菜单选项,可将部分进程保存到磁盘上。
可以通过 "属性" 对话框查看当前进程的各种属性。点击 "编辑 > 属性..." 菜单选项查看属性 (参见文件属性以获取更多信息)。
在编辑器中打开进程后,单击输出窗口的“进程”选卡将显示当前为进程打开的所有堆的列表。如果输出窗口被隐藏,则可以使用“视图 > 输出窗口 > 进程 ”菜单选项来显示它。进程的每个堆都将映射到文件的一个区域。堆地址 和堆大小 列,列出了实际内存中堆的地址。本地起始 列,列出了本地坐标中的堆起始位置,这在编写脚本或模板时使用。右键单击任何列都可以通过“列显示格式”菜单选项设置显示格式。标志、状态、类型 和模块 列与上述打开的进程对话框中的列相同。
进程的图表显示在“输出窗口”的左侧。此图类似于打开进程对话框的图形,但仅显示已打开的堆。打开堆的总数显示在图表下方。从列表中选择堆会加亮显示图表中的堆,并同样在十六进制编辑器窗口中选择堆的字节。
使用 工作区
工作区是 010 Editor 中管理文件的主要控制中心,包括三个选卡:工作区、项目 和资源管理器。使用 "工作区" 选卡管理打开的、收藏的、最近的和书签的文件,并使用“资源管理器" 选卡浏览磁盘上的文件。可以使用“工作区”选卡或“项目”选卡来管理项目。使用“视图 > 工作区窗口”菜单显示或隐藏工作区选卡。当前打开的文件列表可以作为工作区文件保存到磁盘。以下部分描述了工作区的不同选卡。
使用 检查器
检查器 是一种功能强大的工具,用于检查和编辑作为多种不同数据类型的二进制数据。与检查器组合在一起的是其他七个选卡:变量、可视化、书签、函数、监视、调用堆栈 和断点。使用 “视图 > 检查器窗口” 菜单可显示或隐藏选卡。
- 变量 选卡显示运行二进制模板或脚本后创建的变量列表。变量也显示在模板结果面板中,但“变量”选卡是可以取消停靠的备用位置。
- 可视化 选卡是查看迷你地图的备用位置。书签选卡显示为当前文件创建的所有书签的列表(请参阅使用书签),
- 函数选卡显示可在脚本或模板中使用的所有内置函数的列表。
- 监视、调用堆栈 和断点 选卡在使用调试器帮助主题中讨论。
使用 列模式
要输入列模式,可单击“视图 > 换行 > 列模式”菜单选项、键入 Alt+3 或单击工具栏中的 "列模式" 图标。也可以 在不输入列模式的情况下, 通过在拖动鼠标的同时按住 Ctrl 键进行列选择。当列选择已复制到剪贴板并使用粘贴时,即使编辑器不是列模式,数据也会粘贴为列
查找、替换、多文件、正则
要用正则表达式搜索,请单击 查找栏中的 “选项” 按钮,然后启用“使用正则表达式搜索”切换
"查找字串" 对话框可用于发现二进制文件中字串的位置。使用“搜索 > 查找字串...”菜单选项访问“查找字串”对话框,并注意此工具通常对文本文件无用,因为文本文件完全由一组字串组成。
使用项目和工作区
项目 是正在处理的文件列表,该列表可以组织成具有一系列文件夹的树结构。项目中的文件可以在 010 Editor 中打开或关闭。工作区文件是包含 010 Editor 中所有打开文件的列表的文件,包括其选卡的布局方式以及任何额外的浮动选卡窗口。可以在有或没有关联工作区的情况下创建项目。项目中的所有文件都显示在工作区选卡或项目选卡的项目节点中。使用项目菜单或通过右键单击工作区选卡或项目选卡中的项目结构来管理项目中的文件。项目以扩展名为“.1pj”保存到磁盘,工作区文件以扩展名“.1wk”保存。
可以通过单击“项目>新建项目/工作区”来创建新项目,该按钮将显示“项目选项”对话框:
如果选中“使用项目存储工作区(打开的文件)”开关,则工作区文件将与新建项目相关联,并且在创建项目时将关闭所有当前打开的文件。如果未选中该开关,则将改用当前应用程序中的工作区。加载具有关联工作区的项目时,工作区将显示打开的文件:<项目名称>,但如果没有关联的工作区,则工作区仅显示打开的文件。
设置“相对于项目文件的存储路径”切换开关后,磁盘上存储的任何路径都将是相对路径,如果未设置切换,则路径将存储为绝对路径。例如,如果项目文件为 "C:\Projects\Proj1.1pj",数据文件为 "C:\Projects\Data\File1.dat",则相对路径为 "Data\File1.dat",绝对路径为 "C:\Projects\Data\File1.dat"。如果项目文件与数据文件一起移动,请使用相对路径。
当创建项目时,在单击“项目>保存项目”或单击“项目>将项目另存为”之前,不会将项目保存到磁盘。修改项目时,工作区选卡或项目选卡中的项目名称后会显示一个“*”符号。通过保存为项目分配文件名后,在项目中添加或移动文件将导致项目被修改。如果在“项目选项”对话框中设置了“自动保存项目”切换开关,则项目将自动写入磁盘。如果未启用自动保存项目,则必须使用“项目>保存项目”手动保存项目。
要将文件添加到当前项目,请单击“项目 > 添加到项目”或右键单击工作区选卡或项目选卡中的项目节点,然后选择“添加到项目”。以下选项可用于添加文件:
- 现有文件 - 打开一个标准文件对话框,可用于选择一个或多个文件添加到项目中。
- 现有文件夹 - 显示一个标准的文件夹对话框,可以用来选择磁盘上的一个实时文件夹添加到项目中。更多信息参见项目文件夹和实时文件夹。
- 新建文件夹 - 在项目中创建一个与硬盘上的目录无关的新文件夹。项目中的文件可以拖到文件夹中。有关详细信息,请参阅项目文件夹和实时文件夹。
- 当前文件 - 将当前活动文件添加到项目中,并注意当前文件在应用程序的选卡列表中标记为粗体。
- 所有打开的文件 - 所有当前打开的文件都添加到项目中。如果任何文件已经在项目中,它们将不会被添加。
也可以在工作区中使用拖放来添加文件。例如,可以在打开文件或收藏文件列表中选择文件,然后将其拖入项目中。使用 Shift 和 Control 键 (macOS 上的 Cmd) 拖放也支持多选。
处理项目时存在两种类型的文件夹:
- 项目文件夹 - 一种可以容纳多个文件或其他文件夹的常规文件夹。该文件夹在磁盘上不存在。任何其他文件或文件夹都可以拖到该文件夹中,并且该文件夹内的所有文件不必存在于同一目录中。将文件添加到项目时,通过单击新建文件夹 来创建项目文件夹。
- 实时文件夹 - 磁盘上存在的文件夹以及文件夹内的所有文件也会自动添加到项目中。掩码可用于限制包含哪些文件。每当打开项目或单击“项目 > 刷新文件夹”时,都会刷新文件夹中的文件。在将文件添加到项目时,通过单击现有文件夹来创建活动文件夹。
设置 文件大小
010 Editor 包含一个用于设置当前文件中字节数的有用工具。请注意,驱动器和进程的大小是固定的,无法使用此工具进行编辑。单击“编辑 > 设置文件大小...”菜单选项以显示“设置文件大小”对话框。在“大小”字段中输入所需的文件大小。请注意,可以使用十六进制或十进制格式,具体取决于十六进制和十进制单选按钮。如果新文件大小大于当前文件大小,则会将多个字节附加到文件中。可以使用字节值框中的“十六进制”、“十进制”和“字符”字段来控制插入字节的值。请注意,在一个字段中键入值时,其他字段将自动显示转换后的值 (上面屏幕截图中“字符”字段为空,因为字节值 0 无法转换为可打印字符)。如果新文件大小比当前文件小,则字节将从文件末尾删除。单击“确定”执行操作,或单击“取消”关闭对话框。
自带的工具
计算器
010 Editor 提供的“计算器”是一种使用类似于 C 语法完整表达式的计算器。可以通过单击“工具 > 计算器...”菜单选项或按 F8 来加载计算器。
表达式
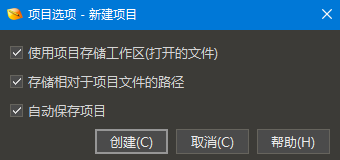
要计算简单表达式,请在计算器中输入一个在行末尾不带分号(';')的表达式。注意,当输入十六进制数字时,在数字后面加一个 'h' (例如 '2Fh')。因为计算器使用 C 语法,所以在以字母开头的任何十六进制数之前一定要加上 '0' (例如,您必须使用 '0FFh' 而不能是 'FFh')。单击“运行”按钮或再次按 F8 以在计算器中显示结果。例如:1000h+512*123 将显示结果 '67072 [10600h]'。如果在行的末尾包含分号,则表达式将被视为 C 程序,并且为了显示结果,必须使用 return 关键字。例如:return 0x1000 + 512*123; 支持所有标准 C 运算符,包括 +、-、*、/、~、^、&、%、|、<<、>>、?:、括号,等。支持十进制、十六进制、八进制和二进制数格式。例如:(312 + 013) * (0x1000 | 0b10) 请注意,乘法与在脚本和模板中看到的略有不同,因为在完成乘法之前整数会自动转换为 64 位整数。有关表达式的更多信息,请参见编写脚本和表达式。
变量也可以使用 C 语法在计算器中声明和使用。例如:
int x = 0x4210 + 512;
int y = (x << 16) + x;
return y; 计算器中声明的变量将显示在“检查器”的“变量”选卡中。还支持字串和数组。参见数据类型获取支持的数据类型的完整列表。
函数。010 Editor 包含许多用于数学运算、编辑文件、编辑字串以及与界面交互的函数。大多数函数与 C 语言相似,但首字母大写。支持 Printf 函数,可用于在“输出”面板的“输出”选卡中显示文本。例如:Printf( "Integer result = %d, String result = '%s'\n", 0x24 << 3, "Test" );
完整的函数列表,请参见接口函数、I/O 函数、字串函数、数学函数或工具函数。
比较 文件
"比较文件" 工具允许对两个文件或两个数据块进行二进制比较,以显示逐字节差异。请注意,这种比较不同于大多数文本编辑器只能逐行比较。单击“工具 > 比较文件...”菜单选项访问“比较文件”工具。比较工具支持两种不同的算法:"二进制" 和 "逐字节"。
- "逐字节" 算法比较两个文件之间的对应字节 (例如:文件A 的地址n 处的每个字节仅与文件B 的地址 n 处的字节进行比较) 并且通常会快速运行。
- "二进制" 算法尝试识别匹配文件中的块。当文件之间的差异数量较少时,此算法很快,但如果存在许多差异,则算法会减慢 (算法为 O(d2),其中 d 是差异的数量)。在“比较类型”框中选择使用哪种算法。
在“选项”框中运行比较有两个选项。如果启用了“匹配大小写”切换,则 ASCII 字串必须完全匹配,否则会匹配大写和小写字母混合的字串。如果启用了“启用同步滚动”切换,则在比较之后,滚动其中一个文件将导致另一个文件也滚动。可以使用 "窗口 > 同步滚动" 菜单选项关闭同步滚动 (有关详细信息,请参阅窗口菜单)。
十六进制 运算
十六进制运算工具,提供了将数学运算应用于任何一组字节的简单方法。单击“工具 >十六进制运算 ”菜单选项并从列表中选择一种运算,则打开十六进制运算对话框。
所有十六进制运算都将文件中的字节视为数组。通过从 "将数据视为" 下拉列表中选择一种类型来选择数组的数据类型。使用数制系统简介中描述的任何格式在操作数 字段中输入一个数字。请注意,如果设置了十六进制 切换,则假定操作数为十六进制,如果设置了十进制 切换,则假定操作数为十进制。操作数 如何应用于数据取决于选择的操作。以下列表以 C 表示法描述每个操作,假设 X[i] 表示要修改文件中的每个值。
- 赋值: X[i] = 操作数
- 加法: X[i] += 操作数 (这相当于 X[i] = X[i] + 操作数)
- 减法: X[i] -= 操作数 (这相当于 X[i] = X[i] - 操作数)
- 乘法: X[i] *= 操作数 (这相当于 X[i] = X[i] * 操作数)
- 除法: X[i] /= 操作数 (这相当于 X[i] = X[i] / 操作数)
- 求反: X[i] = -X[i]
- 模数: X[i] = X[i] % 操作数 (模数运算符 % 在将 X[i] 除以操作数之后计算余数)
- 设置最小值: 设置 X[i] 的最小限制。如果 X[i] 小于操作数,则将 X[i] 设置为操作数。
- 设置最大值: 设置 X[i] 的最大限制。如果 X[i] 大于操作数,则将 X[i] 设置为操作数。
- 交换字节: 交换 X[i] 的字节
- 二进制与: X[i] &= 操作数
- 二进制或: X[i] |= 操作数
- 二进制异或: X[i] ^= 操作数
- 二进制反转: X[i] = ~X[i]
- 左移: X[i] <<= 操作数
- 右移: X[i] >>= 操作数
- 块左移: 类似于 "左移", 但数据除外, 它被视为一个长块。从 X[i+1) 移出的字节数将被移到 X[i] 上。
- 块右移: 类似于 "右移", 但除数据外, 它被视为一个长块。从 X[i] 移出的字节数将被移到 X[i+1] 上。
- 向左旋转: 类似于 "左移", 除了从 X[i] 移出字节外还将被添加到 X[i] 的右侧。
- 向右旋转: 类似于 "右移", 除了从 X[i] 移出字节外还将被添加到 X[i] 的左侧。
请注意,操作数 不用于某些运算,某些运算只能用于某些数据类型。所选运算的说明显示在“描述”框中,可以通过单击“选项”按钮来控制对话框的其他选项。
转换 文件
010 Editor 提供的转换工具可用于将字节从一个字符集转换为另一个字符集,还可以将换行符从一种类型转换为另一种类型。选择“工具 > 转换”或按 Ctrl+T 打开“转换”对话框。可以使用字符集选项对话框控制可用字符集列表。使用“文件>导入十六进制...”或“文件 > 导出十六进制...”工具,也可以将文件转换为其他格式 (更多信息请参见导入/导出文件)。
直方图
直方图是指示某些数据值在文件中出现的频率的图表。单击“工具 > 直方图”菜单选项以计算并显示当前文件的直方图。
直方图是首先通过将文件解释为数据数组来计算的。通过从 "将数据视为" 下拉列表中选择一个值来选择数组的数据类型 (了解有关不同数据类型的更多信息,参见使用检查器)。然后直方图生成多个存储段,并将每个值放入一个存储段中,具体取决于它的值。例如,最常见的直方图将数据视为无符号字节,并使用 256 个存储段。文件中值为 0 的字节放入第一个存储段中,值为 1 的字节放入第二个存储段中,等等。生成的图表表示每个存储段中放置了多少个值。
单击“选项”按钮以控制直方图的范围和存储段配置。默认情况下,010 Editor 生成 256 个存储段以放置值,但可以使用“存储段数”字段修改存储段的数量。可以通过分别修改“最小值”和“最大值”字段来编辑最小和最大接受值。通过将最小值和最大值指定的范围,将“存储段数”划分为等间隔来计算每个存储段所保持的值。在直方图计算中忽略文件中超出最小值和最大值之外的任何值。
如果未对文件进行选择,则直方图将在整个文件上运行。如果进行了选择,请选取“所选内容”切换以仅根据所选字节 (默认值) 计算直方图,或选择“整个文件”以计算文件中所有字节的直方图。
校验和/哈希算法
验和..." 菜单选项或按 Ctrl+K 来运行 "校验和 " 工具。
反汇编器
反汇编器工具将一组二进制字节转换为汇编语言。汇编语言是一种低级语言,其中每一行通常对应一个可以在机器 CPU 上完成的操作,也称为操作码。反汇编程序与汇编程序相反,汇编程序采用汇编语言并将其转换为二进制字节,这通常用于逆向工程。反汇编可以通过反汇编工具或模板或脚本完成,如在模板中反汇编帮助主题中所述。检查器还可用于对单个操作码执行反汇编。
通过单击主菜单上的“工具>反汇编器…”或单击工具栏上的反汇编器图标来访问反汇编器工具。使用对话框左侧的列表选择要反汇编的体系结构类型。某些体系结构的选项在选项部分中显示为复选框。以下列表显示了每个体系结构的可用选项:
- X86 (16-位): (无)
- X86 (32-位): (无)
- X86 (64-位): (无)
- ARM (32-位): ARM v8, ARM MClass, ARM Thumb Mode, 字节序
- ARM (64-位): 字节序
- MIPS (32-位): MIPS Micro, MIPS 32r6, MIPS ii, MIPS iii, 字节序
- MIPS (64-位): MIPS Micro, MIPS ii, MIPS iii, 字节序
- PowerPC (32-位): PowerPC QPX, 字节序
- PowerPC (64-位): PowerPC QPX, 字节序
- SPARC: SPARC v9
- SystemZ: (无)
- XCore: (无)
- Motorola 68000: 68010, 68020, 68030, 69040, 68060 (also called m68k)
如果打开对话框时未选择任何字节,则反汇编将在整个文件上运行。如果在对话框打开时进行了选择,则可以通过所选内容 切换仅对选择运行反汇编,或通过选择整个文件 切换对整个文件运行反汇编。生成的汇编语言可以是 Intel 语法 (例如, "mov rbx, rcx") 或 AT&T 语法 (例如, movq %rcx, %rbx)。通过单击语法 下拉列表选择要使用的语法。
单击“反汇编”按钮执行反汇编,并在反汇编器输出窗口中显示结果。
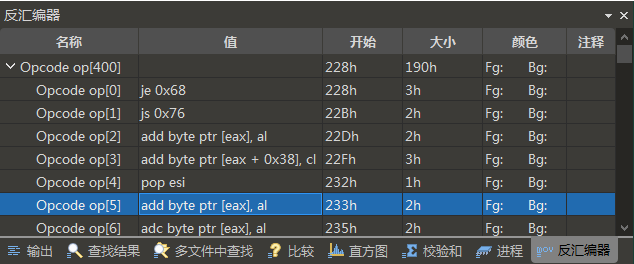
运行反汇编程序后,结果将显示在输出窗口的反汇编器 选卡中,如上所示。反汇编语言指令显示在“值”列中,并在表中选择一行可在十六进制编辑器中选择与该指令对应的字节。“开始”列和“大小”列的格式可以通过右键单击列中的单元格来控制,如使用模板结果工作帮助主题中所述。“名称”列列出从零开始的每个操作码的编号。请注意,在名称列的第一行中,列出的数组大小是反汇编的字节数,而不是生成的操作码数。010 Editor 目前没有执行生成的反汇编的能力,为此,应使用单独的模拟器或调试器工具。在表格上单击鼠标右键,然后选择“清除”以清除反汇编器结果,或者在表格具有焦点时按 Esc 键以隐藏窗口。
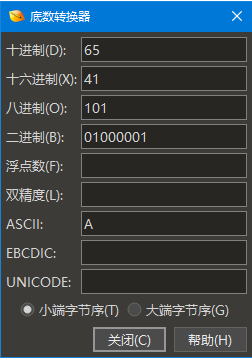
进制 转换器
底数转换器是一种易于使用的工具,用于在十进制,十六进制,八进制和二进制数字格式,以及一些浮点和字串格式之间进行转换。单击“工具 > 底数转换器...”菜单选项以显示底数转换器窗口。
语法
语法 是一组定义的规则,一种用于文本文件的语言,如 C++、JavaScript、XML 等。010 Editor 支持两种语法:Tree-sitter 基本语法和基本二进制模板。
- Tree-sitter 语法将源代码解析为语法树,并可以在文件编辑时实时更新树。Tree-sitter 语法需要更多内存,并且比二进制模板语法慢,但 Tree-sitter 语法在语法加亮显示方面提供了更多详细信息,并提供高级功能,例如匹配大括号、展开选择和识别代码段。
- 二进制模板 语法使用一次解析一行二进制模板。
视图 > 语法”菜单或状态栏的语法部分来选择当前文件的语法。
模板 和 脚本
010 Editor 最强大的功能之一是能够运行二进制模板和脚本。二进制模板允许通过将文件解析为层次结构来理解二进制文件。模板具有与 C/C++ 结构类似的语法,但它们作为程序运行。
运行模板和脚本
有许多方法可以运行一个二进制模板。
- 最简单的是打开一个文件,如果 010 Editor 为这种类型的文件安装了二进制模板,模板将自动运行。010 Editor 预装了二进制模板,用于 BMP、WAV 和 ZIP 文件,但可以安装其他模板 (参见模板选项或存储库对话框以获取更多信息)。
- 也可以在 “模板” 菜单中通过单击模板名称来运行模板 (可以使用模板选项对话框或存储库对话框在此菜单上安装模板) 或使用调试菜单来运行模板。
- 也可以在 工具栏 中通过 “运行模板” 打开 “打开的模板”,“已安装的模板”和“最近的模板”,然后单击列表中的模板名称,以在当前文件上执行该模板。运行模板后,其名称将显示在模板结果面板中,然后单击“模板结果”标题中的图标以重新运行模板或按 F5。如果编辑文本文件,则可以使用“运行模板”图标在当前文件上执行语法突出显示器。
-
运行模板的最后一种方法是右键单击十六进制编辑器中的文件,然后选择“运行模板...”或“在偏移量运行模板...”。单击“运行模板...”
模板会在单独的线程中运行,这意味着在运行模板时仍可以使用编辑器。一次只能运行一个模板或脚本,并且必须停止当前模板或脚本,然后才能运行另一个模板或脚本。要停止正在运行的模板,请单击 "模板 > 停止模板" 或按 Shift+Esc。
运行脚本 与 运行模板 类似,可以通过单击“脚本”菜单中的脚本名称来运行脚本 (有关在此菜单上放置脚本的信息以及所有可用脚本的列表,请参阅脚本选项对话框)。同样,通过相同对话框,“脚本”可以设置为在打开某个文件类型时运行,或者可以设置为在应用程序启动或关闭时自动运行。有关安装其他人已提交到存储库的脚本的信息,请参阅存储库对话框。
或者,可以通过单击工具栏中的 "运行脚本" 图标来运行脚本,如上图所示。从打开脚本、已安装脚本或最近脚本列表中选择脚本,以在当前文件上运行该脚本。选择脚本后,按 F7 再次运行脚本。
脚本在不同的线程中运行,这意味着在脚本运行时仍然可以执行编辑。一次只能运行一个模板或脚本,并且必须停止当前的模板或脚本,然后才能启动另一个模板或脚本。要停止正在运行的脚本,请单击 "脚本 > 停止脚本" 或按 Shift+Esc。
通常,模板是在整个数据文件上运行的,但模板也可以只在文件的一部分上运行。此功能可用于仅在当前光标位置或当前所选内容上应用模板。要在偏移处运行模板,请右键单击十六进制编辑器,然后从弹出菜单中选择 "在偏移量运行模板...",
使用 调试器
调试器 允许查找和修复为 010 Editor 编写的脚本或模板的问题。使用调试器,可以逐行逐步执行脚本或模板,并在每行之后检查每个变量的值。许多调试操作可以使用调试菜单进行控制。
默认情况下,调试器始终在 010 Editor 中启用,但可以通过单击“调试>启用调试”菜单选项打开或关闭调试器。
启动调试器的另一种方法是选择脚本或模板,然后单击“调试>单步进入”菜单选项。此选项启动程序的执行,但暂停在程序的第一个可执行行并启动调试器。也可以通过右键单击文本编辑器中的脚本或模板并从右键单击菜单中选择“运行到光标”来启动调试器。此选项尝试运行脚本或模板,直到到达所选行,此时暂停执行并启动调试器。
编写 脚本
010 Editor 拥有强大的脚本引擎,可以自动完成许多任务。脚本文件的扩展名为“.1sc”,语法与 C 非常相似。所有脚本的执行方式类似于解释器运行文件的方式,从程序的第一行开始向下进行 (无需编写 ANSI C 中的 "main" 函数)。脚本可用于对文件执行编辑操作,磁盘上文件的操作,甚至执行复杂的操作,如文件比较、校验和以及多文件查找。要打开或运行脚本,请参阅脚本菜单或运行模板和脚本。可以通过单击“脚本 > 脚本存储库”菜单选项访问脚本存储库 (请参阅存储库对话框)。可以将脚本配置为在启动、关闭或打开文件时运行,脚本也可以添加到“脚本”菜单中 (参见脚本选项)。
有关编写脚本时使用语法的详细信息,请查看以下主题:
编写脚本时可以使用大量函数。可用函数描述如下:
二进制模板具有类似于脚本的语法,但允许将文件解析为多个变量。脚本可用于修改模板中定义的变量。参见编写模板来了解如何使用模板。
常用的脚本库(*.1sc)用于操作数据http://www.sweetscape.com/010editor/repository/scripts/
- CountBlocks.1sc 查找指定数据块
- DecodeBase64.1sc 解码base64
- EncodeBase64.1sc 编码base64
- Entropy.1sc 计算熵
- JoinFIle.1sc SplitFile.1sc 分隔合并文件
- Js-unicode-escape.1sc Js-unicode-unescape.1sc URLDecoder.1sc js编码解码
- CopyAsAsm.1sc CopyAsBinary.1sc CopyAsCpp.1sc CopyAsPython.1sc 复制到剪贴板
- DumpStrings.1sc 查找所有ascii unicode字符串
编写 模板
菜单 ---> Templates ---> Template Repository,会出现各种文件格式的模板。
比如选择 EXE 文件的模板来分析 PE 文件,然后打开一个 PE 文件,效果如图:


文件模板。(*.bt) 用于识别文件类型 http://www.sweetscape.com/010editor/repository/templates/
- 支持cab gzip rar zip cda midi mp3 ogg wav avi flv mp4 rm pdf iso vhd lnk dmp dex androidmanifest class
- Drive.bt 解析mbr fat16 fat43 hfs ntfs等
- elf.bt 解析Linux elf格式的文件
- exe.bt 解析windows pe x86/x64 格式文件(dll sys exe ...)
- macho.bt 解析mac os可执行文件
- registrayhive.bt 解析注册表(Hive)文件
- bson.bt 解析二进制json
“二进制模板”是 010 Editor 最强大的功能之一,几乎可以将任何二进制文件解析为一系列变量。模板允许以比典型的十六进制编辑器更容易的方式理解和编辑二进制文件。每个模板都存储为扩展名为“.bt”的文本文件,可以直接在 010 Editor 中编辑 (参见模板菜单)。模板在解析器运行时执行,从文件的第一行开始向下进行。执行模板时,文件被解析为多个变量,变量显示在“模板结果”面板中 (参见模板结果以获取更多信息)。模板可以配置为每次打开文件时自动加载和执行 (参见模板选项)。有关模板如何在您的计算机上打开任何 ZIP、BMP 或 WAV 文件的示例,请参阅存储库对话框,以获取有关从存储库安装模板的信息。
“二进制模板”的语法类似于脚本的语法。以下主题描述了编写“二进制模板”时特定使用的语法:
编写模板时有大量的函数可以使用。以下主题列出了所有可用的函数:
脚本可用于修改模板中定义的变量。有关脚本和使用脚本编辑变量的更多信息,有关将脚本和模板一起使用的信息,请参见编写脚本。
010 模板(010 Editor Templates)的基本语法和 C 语言类似,毫不夸张的说你要是会 C 的话,你已经学会了一半。剩下一半你就记住这句话:将整个文件的二进制数据当作输入,将其强制转换为一个结构体就行了。不过当你动手开始实践的时候,你会发现事情果然没有那么简单的,要将整个文件的数据转换成一个结构体,其内部需要更细粒度的结构体来支撑。在 010 的官网上已经有仓库存放了大量的 脚本 和 模板 库供大伙使用。但问题一定是解决不完的,当遇到冷门文件而官方仓库没有模板咋办?办法只有一个:自己写。
变量类型
C 语言中基本变量类型都是支持,包括 int、char、short、long、float 等,结构体 struct,枚举 enum,位域 bitfield 以及联合体 union 也是没问题的。C 中常用的关键字 define、const 和 unsigned 等也是可以用在 010 模板中的。除此之外,Windows 中定义的变量类型也是受支持的,诸如 WORD、DWORD、UINT32、UINT64、LONG。
表达式及语法
C 中的各种加减乘除,大于小于,与或非等表达式也是可以用在模板中的,具体的如下:
- 数值运算:+ - * / ~ ^ & | % ++ -- ?: << >> ()
- 逻辑运算:&& || !
- 比较操作:< ? <= >= == != !
- 赋值操作:= += -= *= /= &= ^= %= |= <<= >>=
C 语言本身的语法并不复杂,在 010 模板中你更不必了解某些生僻的语法,只需要知道 if...else、while、for、switch 以及数组和函数即可。C 语言强大而复杂的指针在 010 中完全用不着,是不是贼开心,可以不用顶着多级指针去操作数据了。
需要注意的是在 010 模板中不能使用二维数组以及 goto 语句。
特殊属性
在官网的文档中,给出了 010 模板中具有的特殊属性:
<format=hex|decimal|octal|binary,
fgcolor=<color>,
bgcolor=<color>,
comment="<string>"|<function_name>,
name="<string>"|<function_name>,
open=true|false|suppress,
hidden=true|false,
read=<function_name>,
write=<function_name>,
size=<number>|<function_name>>
下面将简单介绍下这些属性
- format: 以某种进制格式显示,默认为十进制,显示在 Vlaue 栏
- fgcolor: 设置字体色
- bgcolor: 设置背景色
- comment: 添加注释,显示在 Comment 栏
- name: 替换显示的字符,默认为结构体中的变量名,显示在 Name 栏
- open: 设置树形图是否展开,默认不展开
- hidden: 设置是否隐藏,默认为不隐藏
- read: 读回调,返回字符串并显示在 Vlaue 栏
- write: 写回调,将读回调返回的字符写入结构体某个字段中
- size: 按需执行,可节约系统内存
把这些特殊属性归个类,不常用的属性有 open、write 和 size,某些比较特殊情况下会用到的属性 name 和 hidden,花里胡哨时才会用到 fgcolor 和 bgcolor,快速开发模板你只需要记住 read、format 和 comment。
上边提到特殊情况我展开说明下,name 属性我没怎么用到过,感觉是给强迫症用的,hidden 这个属性在某些情况下有奇效,比如定义的局部变量可能显示在结果中,这时候就可以利用<hidden=true>来隐藏冗余的输出。
下面我放两张图,帮助大伙更好的理解以上这几个特殊的属性,图 1 中的 1 处是 name 属性显示的字符,如果不指定 name 属性默认就是结构体中的变量名。2 处是 format 属性,默认是十进制,这里指定为 16 进制。3 处是背景颜色和字体颜色缩影,这里没设置颜色所以显示为空。4 处就是 comment 属性显示的位置。

背景颜色 bgcolor 和字体颜色 fgcolor 明眼人一看就明白了。

API 接口
010 模板的 Api 比较多,我将一些使用频率比较高的 Api 罗列出来,如果你想要完整的 Api 列表,请看官网的函数接口(https://www.sweetscape.com/010editor/manual/FuncInterface.htm)。不过个人认为下面的 Api 已经足够使用了,除非你要写非常复杂的解析模板:
- void BigEndian()
- void LittleEndian()
- char ReadByte(int64 pos=FTell())
- uchar ReadUByte(int64 pos=FTell())
- short ReadShort(int64 pos=FTell())
- ushort ReadUShort(int64 pos=FTell())
- int ReadInt(int64 pos=FTell())
- uint ReadUInt(int64 pos=FTell())
- int64 ReadInt64(int64 pos=FTell())
- uint64 ReadUInt64(int64 pos=FTell())
- void ReadBytes(uchar buffer[], int64 pos, int n)
- char[] ReadString(int64 pos, int maxLen=-1)
- int ReadStringLength(int64 pos, int maxLen=-1)
- wstring ReadWString(int64 pos, int maxLen=-1)
- int ReadWStringLength(int64 pos, int maxLen=-1)
- void WriteByte(int64 pos, char value)
- int FSeek(int64 pos)
- int FSkip(int64 offset)
- int64 FTell()
- int FEof()
- void Strcpy(char dest[], const char src[])
- void Strcat(char dest[], const char src[])
- int Strchr(const char s[], char c)
- int Strcmp(const char s1[], const char s2[])
- int Printf(const char format[] [, argument, ... ])
- int SScanf(char str[], char format[], ...)
- int SPrintf(char buffer[], const char format[] [, argument, ... ])
这些 Api 大部分都能猜出来是干嘛的,比如 ReadByte 是指定位置读取一个字节,WriteByte 是指定位置写入一个字节,Strcmp 是字符串比较,Printf 打印字符,SScanf 将字符数组 buffer 格式化为多种数据格式,SPrintf 将各种数据格式化后置于字符数组 buffer。
特别需要注意的是以下几个函数,对于解析偏移后的动态数据它们是不可或缺的:
- FEof 判断当前读取位置是否在文件末尾
- FTell 返回文件的当前读取位置
- FSeek 将当前读取位置设置为指定地址
- FSkip 将当前读取位置向前移动多个字节
如果你想要操控 010 模板内部指针的位置,你就得牢记模板在解析文件时内部指针的移动方式:
- 每次在模板中定义变量时,读取位置都会向前移动该变量使用的字节数
- ReadByte 等函数既可以读取数据也不会影响读取位置
示例:解析 .lib 文件
下面以微软的静态库.lib文件为例,演示一个 010 模板从无到有的完整过程。如果要解析某个文件,第一步会干嘛呢?当然是了解该文件的构成,所以第一步就是搜集相关的资料。
搜集资料
在看雪论坛上找到一篇LIB文件解析的文章,将其消化理解后我画了一张结构图来帮助大伙理解,如图:

要是没接触过 Lib 文件,是很难参悟上图的,所以我将上图简要的阐述下,可能会利于大伙理解:
- 开头 8 字节固定为
!<arch>. - 随后为 60 字节的第一链接成员以及 Size 字节的数据
- 然后是第二链接成员及其数据
- 紧接着又是长名称成员及其数据
- 最后是每一个 Obj 成员及其数据
注意,Size 的具体值在其对应的成员结构体中指定。顺便再科普以下,Lib 文件其实是以特定格式打包多个 Obj 文件后的产物
定义结构
有了之前准备的那些资料,就可以为 010 模板定义核心的结构了,核心的结构如下所示:
#define IMAGE_ARCHIVE_START_SIZE 8
#define IMAGE_ARCHIVE_START "!<arch>\n"
#define IMAGE_ARCHIVE_LINKER_MEMBER "/ "
#define IMAGE_ARCHIVE_LONGNAMES_MEMBER "// "
typedef struct _ARCHIVE_START
{
char StartStr[IMAGE_ARCHIVE_START_SIZE];
}ARCHIVE_START;
typedef struct _IMAGE_ARCHIVE_MEMBER_HEADER {
BYTE Name[16];
BYTE Date[12];
BYTE UserID[6];
BYTE GroupID[6];
BYTE Mode[8];
BYTE Size[10];
BYTE EndHeader[2];
}IMAGE_ARCHIVE_MEMBER_HEADER;
typedef struct _MEMBERDATA(ULONG Size)
{
UCHAR Data[Size];
}MEMBERDATA;一定要注意,IMAGE_ARCHIVE_MEMBER_HEADER 的 最后一个字段 EndHeader 必须是以 `\n 结尾,如果不是则必须将当前指针向后移动直到符合上述条件,否则后续的数据解析会连环出错。为了方便只需判断最后一个字节的 ascii 码是不是 10 即可,如果不是当前指针加 1 即可。
简单解析模板
俗话说饭要一口一口的吃,事要一点一点的做。所以先把 Obj 成员之外的简单结构解析了,这部分的代码如下:
#define IMAGE_ARCHIVE_START_SIZE 8
#define IMAGE_ARCHIVE_START "!<arch>\n"
#define IMAGE_ARCHIVE_LINKER_MEMBER "/ "
#define IMAGE_ARCHIVE_LONGNAMES_MEMBER "// "
typedef struct _ARCHIVE_START
{
char StartStr[IMAGE_ARCHIVE_START_SIZE];
}ARCHIVE_START;
typedef struct _IMAGE_ARCHIVE_MEMBER_HEADER {
BYTE Name[16];
BYTE Date[12];
BYTE UserID[6];
BYTE GroupID[6];
BYTE Mode[8];
BYTE Size[10];
BYTE EndHeader[2];
}IMAGE_ARCHIVE_MEMBER_HEADER;
typedef struct _MEMBERDATA(ULONG Size)
{
UCHAR Data[Size];
}MEMBERDATA;
//--------------------------------------
LittleEndian();
ARCHIVE_START Start;
IMAGE_ARCHIVE_MEMBER_HEADER FirstLinker;
if(ReadByte(FTell() + Atoi(FirstLinker.Size)) == 10)
{
MEMBERDATA Data(Atoi(FirstLinker.Size) + 1);
}
else
{
MEMBERDATA Data(Atoi(FirstLinker.Size));
}
IMAGE_ARCHIVE_MEMBER_HEADER SecondLinker;
if(ReadByte(FTell() + Atoi(SecondLinker.Size)) == 10)
{
MEMBERDATA Data(Atoi(SecondLinker.Size) + 1);
}
else
{
MEMBERDATA Data(Atoi(SecondLinker.Size));
}
IMAGE_ARCHIVE_MEMBER_HEADER LongNames;
if(ReadByte(FTell() + Atoi(LongNames.Size)) == 10)
{
MEMBERDATA Data(Atoi(LongNames.Size) + 1);
}
else
{
MEMBERDATA Data(Atoi(LongNames.Size));
}010 模板语法是脚本类型的,即它也是顺序执行。代码的前半部分是一堆类型定义,所以执行的第一行代码是 LittleEndian(),该函数指定为小端解析。后半部分代码是把文件数据依次对应到某个变量,在解析时文件指针会跟随每个结构体的大小移动,解析的效果如图:

完整解析模板
前面已经解析了 Lib 文件中比较简单的结构,剩下的是多个 Obj 成员和数据,这部分解析起来比较复杂。而且最复杂的地方是将其文件名找到并显示在 Value 栏或者 Comment 栏中。所以必须使用 read 和 comment 回调来实现该功能,完整的模板代码如下:
#define IMAGE_ARCHIVE_START_SIZE 8
#define IMAGE_ARCHIVE_START "!<arch>\n"
#define IMAGE_ARCHIVE_LINKER_MEMBER "/ "
#define IMAGE_ARCHIVE_LONGNAMES_MEMBER "// "
typedef struct _ARCHIVE_START
{
char StartStr[IMAGE_ARCHIVE_START_SIZE];
}ARCHIVE_START;
typedef struct _IMAGE_ARCHIVE_MEMBER_HEADER {
BYTE Name[16];
BYTE Date[12];
BYTE UserID[6];
BYTE GroupID[6];
BYTE Mode[8];
BYTE Size[10];
BYTE EndHeader[2];
}IMAGE_ARCHIVE_MEMBER_HEADER;
typedef struct _MEMBERDATA(ULONG Size)
{
UCHAR Data[Size];
}MEMBERDATA;
typedef struct _IMAGE_ARCHIVE_MEMBER_HEADER_OBJ(int i) {
local int index <hidden=true>;
index = i;
BYTE Name[16];
BYTE Date[12];
BYTE UserID[6];
BYTE GroupID[6];
BYTE Mode[8];
BYTE Size[10];
BYTE EndHeader[2];
}IMAGE_ARCHIVE_MEMBER_HEADER_OBJ <comment=GetFullObjName,read=GetObjName>;
typedef struct _ALLOBJS
{
local int i <hidden=true>;
i = 0;
while(!FEof())
{
IMAGE_ARCHIVE_MEMBER_HEADER_OBJ ObjMember(i++);
if(FTell() + Atoi(ObjMember.Size) >= FileSize())
{
MEMBERDATA Data(Atoi(ObjMember.Size));
break;
}
if(ReadByte(FTell() + Atoi(ObjMember.Size)) == 10)
{
MEMBERDATA Data(Atoi(ObjMember.Size) + 1);
}
else
{
MEMBERDATA Data(Atoi(ObjMember.Size));
}
}
}ALLOBJS;
string GetFullObjName(IMAGE_ARCHIVE_MEMBER_HEADER_OBJ& MemberHeader)
{
local int j <hidden=true>;
j = 0;
local int NameOffset <hidden=true>;
NameOffset = LongNameBase;
while(j++ < MemberHeader.index)
{
NameOffset += Strlen(ReadString(NameOffset)) + 1;
}
return ReadString(NameOffset);
}
string GetObjName(IMAGE_ARCHIVE_MEMBER_HEADER_OBJ& MemberHeader)
{
local int j <hidden=true>;
j = 0;
local int k <hidden=true>;
k = 0;
local int NameOffset <hidden=true>;
NameOffset = LongNameBase;
local int start <hidden=true>;
start = 0;
while(j++ < MemberHeader.index)
{
NameOffset += Strlen(ReadString(NameOffset)) + 1;
}
for(start = NameOffset + Strlen(ReadString(NameOffset));start >= NameOffset;start--)
{
if(ReadByte(start) == '\\')
{
break;
}
}
return ReadString(start + 1);
}
//--------------------------------------
LittleEndian();
local int LongNameBase <hidden=true>;
ARCHIVE_START Start;
IMAGE_ARCHIVE_MEMBER_HEADER FirstLinker;
if(ReadByte(FTell() + Atoi(FirstLinker.Size)) == 10)
{
MEMBERDATA Data(Atoi(FirstLinker.Size) + 1);
}
else
{
MEMBERDATA Data(Atoi(FirstLinker.Size));
}
IMAGE_ARCHIVE_MEMBER_HEADER SecondLinker;
if(ReadByte(FTell() + Atoi(SecondLinker.Size)) == 10)
{
MEMBERDATA Data(Atoi(SecondLinker.Size) + 1);
}
else
{
MEMBERDATA Data(Atoi(SecondLinker.Size));
}
IMAGE_ARCHIVE_MEMBER_HEADER LongNames;
LongNameBase = FTell();
if(ReadByte(FTell() + Atoi(LongNames.Size)) == 10)
{
MEMBERDATA Data(Atoi(LongNames.Size) + 1);
}
else
{
MEMBERDATA Data(Atoi(LongNames.Size));
}
ALLOBJS Object;这里讲起来有点绕,所以我会挑一些我认为的重点来说,先给大伙看些最终的效果吧,示例文件是 VS 中的 libcmt.lib。

以下是我认为的代码中的重点:
- 必须判断成员结构的尾部是否为
\n - 必须记录长名称的基址 LongNameBase
- 回调函数可以访问结构体中的局部变量
- 解析时文件指针一定不能超过文件的大小
示例:IDA Pro + 010 Editor 反编译和修改 so 文件
当需要查看 so 源码时,可以使用 IDA Pro 对 so 文件进行反编译,然后就能阅读源码了。如果涉及到修改需求时,则可以先在 IDA Pro 工具里找到对应代码的汇编地址 ,然后使用 010 Editor 打开 so 文件,以汇编地址作为关键字进行查找,找到对应的代码,直接修改即可。

此时,切换到 IDA View-A 界面,在里面查找到 1D592,右侧的 #2 就是需要修改的值。

同样用鼠标选中 #2,然后切换到 Hex View-1 窗口,查看其十六进制的表示:

看到对应的 02 20 也被选中了,02 就是要修改的值的十六进制表示。把整个十六进制串拷贝一下,如红框圈起来所示:

然后用 010 Editor 打开 so 文件,用 ctrl+F 调出搜索框,粘贴刚刚拷贝的十六进制串,定位到对应的代码,然后将 02 改为 00。

修改完后,修改后的值会显示为红色。此时记得点击 保存,然后可以关掉工具。
此时,使用 IDA Pro 再次打开 so 文件,找到刚刚的代码,发现 2 已经变成了 0。

以上就是修改流程。只演示了修改静态资源值,如果对汇编语言很熟悉,可以直接修改代码逻辑。
2、ultraedit
UltraEdit 64 位 v30.2.0.27:https://www.xue51.com/soft/1989.html
UltraEdit 是一套非常强大的文本编辑器,它拥有编辑文本、十六进制、ASCII 码等等功能,并且内建英文单字检查、C++ 及 VB 指令突显,内置英文单字检查、代码提示、折叠等功能,同时还支持配置高亮语法和几乎所有编程语言的代码结构,可以同时打开多个文件进行编辑,即使文件比较大也不会导致它的运行速度变得很慢。
官网:https://www.ultraedit.com/catalog/#ultraedit

一、中文乱码的解决方法
1、现象问题:
同样的一个文件打开是乱码,显示文件的编码是U8-DOS,可是用EditPlus 、记事本,打开,就是正常的,编码显示是ANSI。
即使在打开文件的时候,手动选择各种编码,也不能正确显示文件内容。
2、解决方法:
高级-配置-常规,在“常规”下找到“自动检测UTF-8文件”,挑勾。确定后,把UE关了,再重开。你的文本就能正常显示了,试试吧。
二、删除空行
如何在 UltraEdit 删除空行(含空格,制表符),打开软件,ctrl+r弹出替换对话框,点选启用正则表达式
方法1:
1、在查找框输入 ^p^p:
2、在替换框输入 ^p
3、执行全部替换;
4、这种方法是对连续的两个回车换行,替换成一个回车换行;如果空行中含有空格或者制表符,则不能处理;
方法2:
1、查找框中输入:%[ ^t]++^p,注意^t之前有空格
2、在替换框什么也输入
3、执行全部替换;
4、这种方法可以处理方法1中的缺陷
三、如何设置自动换行
有时候这会非常麻烦, 要让自动换行请按发下方法:
1、点击菜单栏的“高级→配置”,找到“编辑器→自动换行/制表符设置”。
2、然后,把“默认为每个文件启用自动换行”,这样就可以了。 还有一种临时的让软件自动换行的方法就是按下: Ctrl+W,这种方法下次再启动UltraEdit,还是不能自动换行。
四、切换到传统菜单模式
UltraEdit 是一套功能强大的文本编辑器,可以编辑文本、十六进制、ASCII 码,完全可以取代记事本。新的版本安装后界面为 RIbbon 风格,比较占空间,如果电脑屏较小的话,则编辑界面较小。可以改为传统风格模式,图标更小,空间更大。
步骤:打开 ultraedit 后,在工具栏空白处点击右键 ---> 在弹出的右键菜单中,点击工具栏菜单模式 ---> 选择传统模式功能即可。

默认 不显示 标签页,可以设置:菜单栏 ---> 视图 ---> 视图/列表 ---> 打开文件标签
使用 UltraEdit
UltraEdit 支持二进制和16进制编辑,所以还可以用来修改EXE 或DLL 文件。
列模式
列模式能让您按列选取和编辑数据,而一般编辑器只能按行选择数据。
使用快捷键 Alt+C,或者使用菜单 列->列模式。进入列模式后,通过按下键盘上的SHIFT键和方向键来选择多列,光标变成了多列光标。如果敲入的是英文字母或字符是没有问题,当在列模式下敲入的是汉字的时候会出现乱码,因此可以用插入/填充列这个功能来解决这个问题。
插入/填充列
在列模式下选择要填充的列,选择菜单 列->插入/填充列,然后出现一个对话框,在这里填写要插入的文字后点”确定”。
排序(Sort)
排序是UltraEdit提供的非常实用的一个功能,也许您会觉得用Excel更方便,但别忘了Excel只能支持65535行数据,而UltraEdit处理上百万行的数据也不成问题,功能决不逊色于Excel。
菜单 ---> 文件 ---> 排序 ---> 高级排序/选项
排列顺序:可以选择是升序还是降序
删除重复项:可以将文件中一模一样的行删除,只保留一行。(想想用Excel怎么去除重复项)
数字排序:当要排序的列是数字,并且关心它的实际大小时需要勾选这一项,下面的示例将说明这个问题。
排序列:一共可以设置4个列,通过起始列和结束列来指定。
正则表达式搜索与替换
- Ctrl+F 在弹出的查找对话框中输入表达式,并且勾选”正则表达式”
- Ctrl+R 调出替换对话框
在UltraEdit中,正则表达式被很好地支持,目前的版本中一共支持三种,UltraEdit风格正则表达式、Unix风格正则表达式和Perl兼容正则表达式,本文介绍Perl兼容正则表达式,这是一条被广泛使用的正则表达式,绝大多数的编程语言都支持这种表达式。
要使用Perl兼容正则表达式,需要在UltraEdit中做一下设置。点击菜单 高级->配置,出现下图的对话框,在左侧选中”正则表达式引擎”,右边勾选”Perl兼容正则表达式”。
正则表达式语法
| 元字符 | 说明 |
| . | 匹配除换行符以外的任意字符 |
| \w | 匹配字母或数字或下划线或汉字 |
| \s | 匹配任意的空白符() |
| \d | 匹配数字 |
| \b | 匹配单词的开始或结束 |
| \W | 匹配任意不是字母,数字,下划线,汉字的字符 |
| \S | 匹配任意不是空白符的字符 |
| \D | 匹配任意非数字的字符 |
| \B | 匹配不是单词开头或结束的位置 |
| ^ | 匹配行首 |
| $ | 匹配行尾 |
如果查找元字符本身的话,需要使用 \ 来转义。
| 语法 | 说明 |
| * | 重复零次或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
若要匹配 aeiou 五个字符中的任意一个,可以表示成 [aeiou]。再如 [0-9] 表示0到9之间的任意一个数字,它的含义和元字符中的 \d 实际上是一样的。
反意:如果要匹配非a则 [^a] ,除 aeiou 五个字母之外的表示成 [^aeiou]
贪婪与止贪
有字符串 dveadebcadefboipi,正则表达式 a.*b,表达式的意思是匹配由a开始中间包含任意多个字符并以b结尾,这个表达式匹配出来的结果是adebcadefb,而不会是adeb,我们称这种匹配为贪婪匹配,因为它匹配了尽可能多的字符。要防止这种贪婪匹配,使用 ?,把上面的表达式写成a.*?b 则匹配出来的结果就是 adeb ,这就是 "止贪匹配"
示例:很多日期,都是这样的格式dd/mm/yyyy,我们希望把他替换成yyyy-mm-dd的格式。既然是替换,那么必需先查到目标串,用\d表示数据,月和日都一位或两位数据组成,正则表达式表示为\d{1,2},年份都四个数字表示为\d{4},加上中间的分隔符/,整个日期串可以表示为\d{1,2}/\d{1,2}/\d{4}。我们替换的目标是要把最后的年份放到第一位去,因此还需要这个搜索能返回各个部分的值,在Perl正则表达式中用()可以返回搜索串中的值,并用$1表示第一个括号中的值,因此我们加上3个括号表达式变成(\d{1,2})/(\d{1,2})/(\d{4}),那么$1表于日,$2表示月,$3表示年。说到这里要达到我们的目标就很简单了。按下键盘上的Ctrl+R调出替换对话框,查找内容为(\d{1,2})/(\d{1,2})/(\d{4}),替换为$3-$2-$1,记得勾上”正则表达式”。
常用的正则表达
行首空格: ^\s+
行尾空格:\s+$
IP地址:[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}
正整数: ^[1-9]\d*$
负整数: ^-[1-9]\d*$
远程文件直接编辑
要编辑Linux上的文件是一件很痛苦的使用,Linux上的VI编辑器可不像UltraEdit这么好用,在没有UltraEdit前也许您只能把文件下载回来编辑好后再传上来,有了UltraEdit的话不需要这么麻烦了,他直接打开远程机器上的文件,保存后自动上传到远程服务器。
步骤:菜单 ---> 文件 ---> FTP/Telnet ---> 从FTP打开
注意:不建议使用该功能编辑系统核心文件,保存的时候如果出现网络故障容易导致文件丢失。
冻结窗口
实现上UltraEdit中并没有冻结窗口这个概念,之所以这么中是因为UltraEdit可以实现类似Excel的冻结窗口的功能。在Excel中我们常用这个功能来固定表头,这样上下滚动的时候可以保持表头不动。
UltraEdit中可以实际固定左侧列,滚动水平条的时候只有右边动。例如一个书目文件,第一列是书名,而价格这一列在最后,中间夹着很多内容,当把价格这一类滚动到视图中间的时候却看不到书名。因此我们想把书名这一列固定下来,在滚动水平条的时候固定不动,先要设置一个列标记,点菜单 视图->设置列标记,在出现的设置列标记对话框中,勾选要冻结的列,设好后,点”确定”,这样 冻结的列的内容在水平条滚动的时候不会变,可以把后面的内容滚到前面来
语法加亮
语法加亮是UltraEdit的一个突出亮点,它能像各种语言的IDE开发环境一样,对各种语法的关键字着色。UltraEdit通过一个叫wordfile的文件来定义各种语言的着色规则。通过添加语法规则即可增加UltraEdit的识别能力。
默认安装后的UltraEdit不支持Oracle的SQL语法着色,下面举例如何让UltraEdit识别Oracle的SQL脚本并对关键字着色。
首先打开wordfile定义文件,点菜单 高级->配置,在左侧找到”语法加亮”,点右边的”打开”按钮即可打开wordfile文件。
到官方网站下载Oracle的语法定义文件,官方提供了上百种语法的定义文件,可以根据需要下载,路径为http://www.ultraedit.com/downloads/extras.html#wordfiles。
把下载回来的文件粘在wordfile的结尾保存一下就行了
注意一下,下回来内容的开头有一个/L后面有个数字,这个数据需要根据自己的情况改变一下。这是一个编号,不能和wordfile已有的编号重复,并且不能大于20。您可以通过以下方法确定这个编号,点一下工具栏上的”查看方式”按钮,
弹出下图的菜单,红色框内语言15到语言20都是目前系统没有用到的编号,因此在这里我们可以把这个编号改成15。保存后,当我们再次打开Oracle的SQL脚本的时候,语法中的关键字已经会自动着色了。
3、Sublime Text
官网:http://www.sublimetext.com/
Sublime Text 文档
Sublime Text 系列
Sublime Text:学习资源篇:https://www.jianshu.com/p/d1b9a64e2e37
Sublime插件:增强篇:https://www.jianshu.com/p/5905f927d01b
Sublime插件:Markdown篇:https://www.jianshu.com/p/aa30cc25c91b
Sublime插件:C语言篇:https://www.jianshu.com/p/595975a2a5f3
Sublime插件:主题篇:https://www.jianshu.com/p/13fedee165f1
Sublime插件:Git篇:https://www.jianshu.com/p/3a8555c273d8
编辑器有 EditPlus、UltraEdit、Notepad++、Vim、TextMate 和 Sublime Text 等。关于 vs code、sublime text、atom 究竟谁才是编辑器之王的话题,这里不做评论,反正Sublime text 出道很久,至今仍占据主流编辑器一席之地,自然有它的可取之处的。
- Sublime Text 是一款 跨平台 代码编辑器,在 Linux、OS X 和 Windows 下均可使用。
- Sublime Text 是可扩展的,并包含大量实用插件。
- Sublime Text 支持 命令行环境、图形界面
- Sublime Text 为收费软件,不过不购买也可以一直使用。
编辑器(Editor)vs 集成开发环境(Integrated Development Environment,下文简称IDE)
- 编辑器面向无语义的纯文本,不涉及领域逻辑,因此速度快体积小,适合编写单独的配置文件和动态语言脚本(Shell、Python和Ruby等)。
- IDE面向有语义的代码,会涉及到大量领域逻辑,因此速度偏慢体积庞大,适合编写静态语言项目(Java、C++和C#等)。
安装、汉化
官网直接下载安装即可。
sublime 汉化:https://jingyan.baidu.com/article/ca2d939d1e83feeb6c31cefc.html
- 1. 打开 Sublime Text,使用快捷键 Shift + Ctrl + P
- 2. 在搜索框中输入关键字 install,选择 Package Control: Install Package 点击,点击之后并不会立刻有反应,稍等一会就会弹出一个消息框,表示插件列表加载完成
- 3. 在搜索框中输入chinese,选择下拉框中的 ChineseLocalizations,点击之后,中文包就安装完成了,注意需要重新打开Sublime Text,点击任务栏中的Help->最下面的Language->简体中文

插件管理 (Package Control)
Sublime Text支持大量插件,如何找到并管理这些插件就成了一个问题,Package Control正是为了解决这个问题而出现的。Package Control 是插件管理包,所以我们首先要安装它。有了它,我们就可以很方便的浏览、安装和卸载Sublime Text中的插件。在ST中按Ctrl+`进入ST的控制台,然后去官网上将ST3的安装命令拷贝到其中执行就可以完成安装了。有了它,在ST中按Ctrl+Shift+P,输入Install或Remove后,就可以随便安装、卸载各种扩展了,包括各种ST的插件、主题等等。
Package Control 安装 教程 ( Installation - Package Control )。
Package Control 安装完成。之后使用 Ctrl + Shift + P 打开命令板,输入 PC 应出现 Package Control:

成功安装 Package Control 之后,我们就可以方便的安装使用 Sublime Text 的各种插件:

如下图:插件管理包 已安装成功。

安装插件
Sublime Text 插件官方网站:Package Control - the Sublime Text package manager

插件所在目录
菜单 ---> Preferences--->Browse Packages
列出 已安装的插件
快捷键 Ctrl+Shift+P,在对话框中输入 “list”,选择 “Package Control:List Packages”。
移除 插件
快捷键 Ctrl+Shift+P,在对话框中输入 “remove”,选择 “Package Control: Remove Packages”。
备份 Sublime Text 的所有插件及所有配置
:https://www.zhihu.com/question/39064280
这是 Package Control 的 Sync ( Syncing - Package Control ) 特性。

Sublime 安装的数据目录:

- 不要同步 Packages 和 Installed Packages,不同平台内容不同;
- 同步 Packages/User/ 即可,该文件夹里面有 Package Control.sublime-settings 文件,它会帮你做好未装插件的安装工作;
具体操作步骤:https://www.jianshu.com/p/82f9e92fefb6
Sublime 配置好后,只要备份Packages\User文件夹即可,里面的 sublime-settings 文件都保存了你的所有设置,更换电脑之后,只要恢复过去,打开Sublime的时候会自动检测,下载并安装你需要的包。
实用插件
ConvertToUTF8 插件安装
功能说明:ConvertToUTF8 能将除UTF8编码之外的其他编码文件在 Sublime Text 中转换成UTF8编码,在打开文件的时候一开始会显示乱码,然后一刹那就自动显示出正常的字体,当然,在保存文件之后原文件的编码格式不会改变。
安装
- 方法 1:快捷键 Ctrl+Shift+p ,打开 “Command Palette” 悬浮对话框,在顶部输入 “install”, 然后下选点击 “Package Control:Install Package”。 在出现的悬浮对话框中输入 “convert”, 然后点选下面的 “ConvertToUTF8” 插件,就会自动开始安装,安装成功后,底部的状态栏会有安装成功的提示。
- 方法 2:下载完整的插件包后解压放到插件所在的目录下,以达到安装插件的目的。下载地址:https://github.com/seanliang/ConvertToUTF8。
BracketHighlighter
功能说明:高亮显示匹配的括号、引号和标签。
插件地址:https://github.com/facelessuser/BracketHighlighter/tree/BH2ST3
LESS
功能说明:LESS 语法高亮显示。
插件地址:https://github.com/danro/LESS-sublime
sublime-less2css
功能说明:将 less 文件编译成 css 文件。
插件地址:https://github.com/facelessuser/BracketHighlighter/tree/BH2ST3
辅助工具:安装后从 https://github.com/duncansmart/less.js-windows 下载 less.js-windows,然后配置 less.js-windows 的环境变量。
Emmet
功能说明:Emmet的前身是大名鼎鼎的Zen codin。前端开发必备,HTML、CSS代码快速编写神器。
使用方法:默认快捷键 Tab
插件地址:https://github.com/sergeche/emmet-sublime
辅助工具:PyV8 下载地址: https://github.com/emmetio/pyv8-binaries
Emmet 官网文档:http://docs.emmet.io/
中文文档:https://yanxyz.github.io/emmet-docs/css-abbreviations/vendor-prefixes/
前端开发必备!Emmet使用手册:https://www.w3cplus.com/tools/emmet-cheat-sheet.html
JsFormat 插件
功能说明:JavaScript 代码格式化。
使用方法:在打开的 JavaScript 文件里点右键,选择 JsFormat。
插件地址:https://github.com/jdc0589/jsformat
可以使用 HTML-CSS-JS Prettify 插件 代替
ColorHighlighter 插件
功能说明:显示所选颜色值的颜色,并集成了 ColorPicker
插件地址:https://github.com/Monnoroch/ColorHighlighter
Compact Expand CSS Command 插件
功能说明:使CSS属性展开及收缩,格式化CSS代码。
使用方法:按 Ctrl+Alt+[ 收缩CSS代码为一行显示,按 Ctrl+Alt+] 展开CSS代码为多行显示。
插件地址:https://gist.github.com/vitaLee/2863474 或者:https://github.com/TooBug/CompactExpandCss
快捷键 Ctrl+Alt+[ 收缩CSS代码为单行效果:
快捷键 Ctrl+Alt+] 展开CSS代码为多行显示效果:
SublimeTmpl 插件
功能说明:快速生成文件模板。
使用方法:SublimeTmpl 默认的快捷键如下,如果快捷键设置冲突可能无效。
Ctrl+Alt+h 新建 html 文件
Ctrl+Alt+j 新建 javascript 文件
Ctrl+Alt+c 新建 css 文件
Ctrl+Alt+p 新建 php 文件
Ctrl+Alt+r 新建 ruby 文件
Ctrl+Alt+Shift+p 新建 python 文件
插件地址:https://github.com/kairyou/SublimeTmpl
相应的模板为 tmpl 格式的文件,保存在 Packages\SublimeTmpl\templates
新增语言:你还可以增加模板文件夹中没有的文件模板,并做相应的设置来使用这一功能。
具体可以参考它的中文文档:http://www.fantxi.com/blog/archives/sublime-template-engine-sublimetmpl/
Alignment 插件
功能说明:使代码格式的自动对齐。
使用方法:快捷键 Ctrl+Alt+A,可能与QQ截图冲突,二者中的一个要重置快捷键。
插件地址:https://github.com/kevinsperrine/sublime_alignment
AutoFileName 插件
功能说明:自动补全文件(目录)名。
插件地址:https://github.com/BoundInCode/AutoFileName
DocBlockr 插件
功能说明:快速生成JavaScript (including ES6), PHP, ActionScript, Haxe, CoffeeScript, TypeScript, Java, Groovy, Objective C, C, C++ and Rust语言函数注释。
使用方法:在函数上面输入/** ,然后按 Tab 就会自动生成注释。
插件地址:https://github.com/spadgos/sublime-jsdocs
SublimeCodeIntel 插件
支持所有 Komode Editor 支持的代码语言,如:JavaScript, Mason, XBL, XUL, RHTML, SCSS, Python, HTML, Ruby, Python3, XML, Sass, XSLT, Django, HTML5, Perl, CSS, Twig, Less, Smarty, Node.js, Tcl, TemplateToolkit, PHP等。
功能说明:智能提示。
插件地址:https://github.com/SublimeCodeIntel/SublimeCodeIntel
Better Completion,全能代码提示
HTML-CSS-JS Prettify 插件
功能说明:HTML、CSS、JS格式化。
插件地址:https://github.com/victorporof/Sublime-HTMLPrettify 安装方法:安裝这个套件前必须先安裝node.js,指定 node.exe 的执行档所在位置。进而安装HTML-CSS-JS Prettify。
使用方法一:View -> Show console 或者使用快捷键 Ctrl + `,在命令列的地方輸入:view.run_command("htmlprettify"),然后按下Enter。
使用方法二:默认快捷键:Ctrl+Shift+H。 你也可以自行设置快捷键,菜单 “Preferences---> Key Bindings – User” 里新增:
{
"keys": ["ctrl+shift+o"],
"command": "htmlprettify"
}
完成后保存,以上代码设定执行此插件的快捷键是:Ctrl+Shfit+O,自己设定的话就要测试一下,不要跟其他快捷键冲突。
其实有了这个代码格式化插件,就可以删除其他代码格式化插件了,因为功能确实强大!
官网插件配置:https://packagecontrol.io/packages/HTML-CSS-JS%20Prettify
FED社区:sublime text 3 插件:HTML-CSS-JS Prettify:
http://frontenddev.org/article/sublime-does-text-three-plug-ins-html-and-css-js-prettify.html
SideBarEnhancements 插件
功能说明:侧栏菜单扩充功能。
插件地址:https://github.com/titoBouzout/SideBarEnhancements/tree/st3
View In Browser 插件
功能说明:Sublime Text 保存后网页自动同步更新。
插件地址:https://github.com/adampresley/sublime-view-in-browser 使用方法:在打开的文档任一处点右键,选择 “View In Browser”,就会用默认的浏览器自动打开该文件。
LiveReload 插件
功能说明:调试网页实时自动更新。
使用说明:快捷键 Ctr+Alt+V
插件地址:https://github.com/dz0ny/LiveReload-sublimetext2
同时Chrome浏览器也要安装LiveReload 的扩展插件。
SyncedSidebarBg 插件
自动同步侧边栏底色为编辑窗口底色
SFTP 插件
快速编辑远程服务器文件
使用 SFTP 插件快速编辑远程服务器文件:http://blog.wpjam.com/m/sublime-text-2-sftp/
sublime text同步文件神器 SFTP:http://blog.csdn.net/yangxuan0261/article/details/52075395
Python PEP8 Autoformat
这是用来按PEP8自动格式化代码的。可以在包管理器中安装。如果以前写程序不留意的话,用SublimeLinter一查,满屏都是白框框,只要装上这个包,按 ctrl+shift+r 代码就会按PEP8要求自动格式化了,一屏的白框几乎都消失了。
SublimeREPL
对开发者来讲这个可能是最有用的插件之一了。SublimeREPL 可以直接在编辑器中运行一个解释器,支持很多语言:Clojure, CoffeeScript, F#, Groovy, Haskell, Lua, MozRepl, NodeJS, Python, R, Ruby, Scala, shell
AllAutocomplete
传统的Sublime Text自动补全插件仅仅在当前文件下工作。AllAutocomplete 可以搜索全部打开的标签页,这将极大的简化开发进程。当然,还有一个插件叫 CodeIntel,实现了一些IDE的功能并且为一些语言提供了“代码情报”: JavaScript, Mason, XBL, XUL, RHTML, SCSS, Python, HTML, Ruby, Python3, XML, Sass, XSLT, Django, HTML5, Perl, CSS, Twig, Less, Smarty, Node.js, Tcl, TemplateToolkit, PHP
Theme-Soda 插件
功能说明:最受欢迎的 Sublime Text 主题之一。
插件地址:https://github.com/buymeasoda/soda-theme
安装完成后,点菜单 Preferences--->Settings - User,根据需要的主题效果,添加如下代码。
Soda 亮色主题请添加:
{
"soda_classic_tabs": true,
"theme": "Soda Light 3.sublime-theme",
}
Soda 暗色主题请添加:
{
"soda_classic_tabs": true,
"theme": "Soda Dark 3.sublime-theme",
}
要达到更好的效果,你还需要下载与之搭配的 color scheme。
下载地址:http://buymeasoda.github.com/soda-theme/extras/colour-schemes.zip
如果你喜欢 Soda Dark 和 Monokai,可以使用 Monokai Extended。这个 color scheme 是 Monokai Soda 的增强,再配合 Markdown Extended ,将大大改善 Markdown 的语法高亮。
Theme-Flatland 插件
功能说明:最受欢迎的 Sublime Text 主题之一。
插件地址:https://github.com/thinkpixellab/flatland
Theme-Nexus 插件
功能说明:最受欢迎的 Sublime Text 主题之一。
插件地址:https://github.com/EleazarCrusader/nexus-theme
Sublime Text 的使用
Sublime Text 的界面如下:

- 标签(Tab):无需介绍。
- 编辑区(Editing Area):无需介绍。
- 侧栏(Side Bar):包含当前打开的文件以及文件夹视图。
- 缩略图(Minimap):如其名。
- 命令板(Command Palette):Sublime Text的操作中心,它使得我们基本可以脱离鼠标和菜单栏进行操作。
- 控制台(Console):使用Ctrl + `调出,它既是一个标准的Python REPL,也可以直接对Sublime Text进行配置。
- 状态栏(Status Bar):显示当前行号、当前语言和Tab格式等信息。
配置(Settings)
与其他GUI环境下的编辑器不同,Sublime Text并没有一个专门的配置界面,与之相反,Sublime Text 使用 JSON 配置文件,例如:
{
"font_size": 12,
"highlight_line": true,
}
会将默认字体大小调整为12,并高亮当前行。
JSON 配置文件的引入简化了Sublime Text的界面,但也使得配置变的复杂,一般我会到这里查看可用的Sublime Text配置。
设置字体及字体大小
点菜单 “Preferences--->Setting - User”,打开 “Preferences.sublime-settings”。

如下图添加所需代码,根据自己的喜好进行设置。设置字体用 "font_face":"字体名称",设置字体大小用 "font_size":"字体大小",注意它们之间需要用逗号隔开。

编辑(Editing)
Sublime Text 的编辑十分人性化,不像 Vim 那样反人类。
基本编辑(Basic Editing)
- ↑↓←→ 就是 ↑↓←→, 不像 vim 的 KJHL,粘贴剪切复制均和系统一致。
- Ctrl + Enter 在当前行下面新增一行然后跳至该行;
- Ctrl + Shift + Enter 在当前行上面增加一行并跳至该行。

Ctrl + ←/→ 进行逐词移动,相应的,Ctrl + Shift + ←/→ 进行逐词选择。

Ctrl + ↑/↓ 移动当前显示区域,Ctrl + Shift + ↑/↓ 移动当前行。

选择(Selecting)
多重选择:同时选择多个区域,然后同时进行编辑。多重选词的一大应用场景就是重命名
Ctrl + D 选择当前光标所在的词,并高亮该词所有出现的位置,再次 Ctrl + D 选择该词出现的下一个位置,在多重选词的过程中,
- 使用 Ctrl + K 进行跳过,
- 使用 Ctrl + U 进行回退,
- 使用 Esc 退出多重编辑。
可以通过多重选词+多重编辑进行直观且便捷的重命名:

有时我们需要对一片区域的所有行进行同时编辑,Ctrl + Shift + L 可以将当前选中区域打散,然后进行同时编辑:

有打散自然就有合并,Ctrl + J可以把当前选中区域合并为一行:

查找 & 替换(Finding&Replacing)
Sublime Text 提供了强大的查找(和替换)功能,为了提供一个清晰的介绍,可以将 Sublime Text的查找功能分为三种类型
- 快速查找
- 标准查找
- 多文件查找。
快速查找 & 替换
多数情况下,我们需要查找文中某个关键字出现的其它位置,这时并不需要重新将该关键字重新输入一遍然后搜索,我们只需要使用 Shift + ←/→ 或 Ctrl + D 选中关键字,然后 F3 跳到其下一个出现位置,Shift + F3 跳到其上一个出现位置,此外还可以用 Alt + F3 选中其出现的所有位置(之后可以进行多重编辑,也就是快速替换)。

标准查找 & 替换
常见的使用场景:搜索某个已知但不在当前显示区域的关键字,这时可以使用Ctrl + F调出搜索框进行搜索:
以及使用 Ctrl + H 进行替换:


关键字查找 & 替换
一般常规的关键字搜索就可以满足大部分需求:在搜索框输入关键字后 Enter 跳至关键字当前光标的下一个位置,Shift + Enter 跳至上一个位置,Alt + Enter 选中其出现的所有位置(同样的,接下来可以进行快速替换)。
Sublime Text 的查找有不同的模式:Alt + C 切换大小写敏感(Case-sensitive)模式,Alt + W切换整字匹配(Whole matching)模式,除此之外Sublime Text 还支持在选中范围内搜索(Search in selection),这个功能没有对应的快捷键,但可以通过以下配置项自动开启:"auto_find_in_selection": true
这样之后在选中文本的状态下范围内搜索就会自动开启,配合这个功能,局部重命名(Local Renaming)变的非常方便:
使用 Ctrl + H 进行标准替换,输入替换内容后,使用 Ctrl + Shift + H 替换当前关键字,Ctrl + Alt + Enter 替换所有匹配关键字。

正则表达式查找 & 替换
正则表达式是非常强大的文本查找&替换工具,Sublime Text 中使用 Alt + R 切换正则匹配模式的开启/关闭。Sublime Text 使用 Boost里的Perl正则表达式风格 ( Perl Regular Expression Syntax - 1.44.0 )。
正则表达式的优秀教程
在线测试工具
sublimeText 正则删除和替换
([A-Z]{3})(.*?)([^.]http.*)$
$1$3
多文件搜索&替换
使用 Ctrl + Shift + F 开启多文件搜索&替换(注意此快捷键和搜狗输入法的简繁切换快捷键有冲突):

多文件搜索&替换,默认在当前打开的文件和文件夹进行搜索/替换,也可以指定文件/文件夹进行搜索/替换。
跳转(Jumping)
Sublime Text 提供了强大的跳转功能,可以在不同的文件/方法/函数中无缝切换。
跳转到文件
Ctrl + P 会列出当前打开的文件(或者是当前文件夹的文件),输入文件名然后 Enter 跳转至该文件。Sublime Text 使用模糊字符串匹配(Fuzzy String Matching),可以通过文件名的前缀、首字母或是某部分进行匹配:例如,EIS、Eclip 和 Stupid 都可以匹配EclipseIsStupid.java。

跳转到符号
Sublime Text 能够对代码符号进行一定程度的索引。
- Ctrl + R 会列出当前文件中的符号(例如类名和函数名,但无法深入到变量名),输入符号名称Enter即可以跳转到该处。
- F12 快速跳转到当前光标所在符号的定义处(Jump to Definition)。

对于 Markdown,Ctrl + R 会列出其大纲,非常实用。

Ctrl + G 然后输入行号以跳转到指定行:

组合跳转。在 Ctrl + P 匹配到文件后,可以进行后续输入以跳转到更精确的位置:
- @ 符号跳转:输入@symbol 跳转到 symbol符号 所在的位置
- # 关键字跳转:输入 #keyword 跳转到 keyword 所在的位置
- : 行号跳转:输入:12 跳转到文件的第12行。

中文输入法的问题
从Sublime Text的初版(1.0)到现在,中文输入法(包括日文输入法)都有一个问题:输入框不跟随。目前官方还没有修复这个bug,解决方法是安装IMESupport插件,之后重启Sublime Text问题就解决了。
文件夹(Folders)
Sublime Text 支持以文件夹做为单位进行编辑,这在编辑一个文件夹下的代码时尤其有用。在File下Open Folder:

你会发现右边多了一个侧栏,这个侧栏列出了当前打开的文件和文件夹的文件,使用 Ctrl + K, Ctrl + B 显示或隐藏侧栏,使用 Ctrl + P 快速跳转到文件夹里的文件。
窗口和标签(Windows & Tabs)
Sublime Text是一个多窗口多标签编辑器。既可以开多个Sublime Text窗口,也可以在一个Sublime Text窗口内开多个标签。
窗口(Window)
使用Ctrl + Shift + N创建一个新窗口(该快捷键再次和搜狗输入法快捷键冲突,个人建议禁用所有搜狗输入法快捷键)。
当窗口内没有标签时,使用Ctrl + W关闭该窗口。
标签(Tab)
使用Ctrl + N在当前窗口创建一个新标签,Ctrl + W关闭当前标签,Ctrl + Shift + T恢复刚刚关闭的标签。
编辑代码时我们经常会开多个窗口,所以分屏很重要。Alt + Shift + 2进行左右分屏,Alt + Shift + 8进行上下分屏,Alt + Shift + 5进行上下左右分屏(即分为四屏)。

分屏之后,使用Ctrl + 数字键跳转到指定屏,使用Ctrl + Shift + 数字键将当前屏移动到指定屏。例如,Ctrl + 1会跳转到1屏,而Ctrl + Shift + 2会将当前屏移动到2屏。
全屏(Full Screen)
Sublime Text有两种全屏模式:普通全屏 和 无干扰全屏。
个人强烈建议在开启全屏前关闭菜单栏(Toggle Menu),否则全屏效果会大打折扣。
F11切换普通全屏。 Shift + F11切换无干扰全屏:
分屏
Sublime Text 有多种分屏形式,让我来具体地看一看。菜单 “View -> layout ” 就可以选择你的分屏样式。
对应的快捷键与分屏情况如下:
Alt+Shift+1 Single 独屏
Alt+Shift+2 Columns:2 纵向二栏分屏
Alt+Shift+3 Columns:3 纵向三栏分屏
Alt+Shift+4 Columns:4 纵向四栏分屏
Alt+Shift+8 Rows:2 横向二栏分屏
Alt+Shift+9 Rows:3 横向三栏分屏
Alt+Shift+5 Grid 四格式分屏
风格(Styles)
风格对于任何软件都很重要,对编辑器也是如此,尤其是GUI环境下的编辑器。作为一个程序员,我希望我的编辑器足够简洁且足够个性。
Notepad++默认界面

Sublime Text 默认界面

Sublime Text 自带的风格是 深色风格(也可以调成浅色),默认主题是 Monokai Bright,这两者的搭配已经很不错了,不过还可以做得更好:接下来将会展示如何通过设置偏好项和添加自定义风格/主题使得Sublime Text更加Stylish。
一些设置(Miscellaneous Settings)
下面是我个人使用的设置项。
// 设置Sans-serif(无衬线)等宽字体,以便阅读
"font_face": "YaHei Consolas Hybrid",
"font_size": 12,
// 使光标闪动更加柔和
"caret_style": "phase",
// 高亮当前行
"highlight_line": true,
// 高亮有修改的标签
"highlight_modified_tabs": true,设置之后的效果如下:

主题(Themes)
Sublime Text有大量第三方主题 ( theme - Labels - Package Control )






配色(Color)
colorsublime包含了大量Sublime Text配色方案,并支持在线预览,配色方案的安装教程在这里,恕不赘述。
我个人使用的是Nexus主题和Flatland Dark配色,配置如下:
"theme": "Nexus.sublime-theme",
"color_scheme": "Packages/Theme - Flatland/Flatland Dark.tmTheme",效果如下:

编码(Coding)
优秀的编辑器使编码变的更加容易,所以Sublime Text提供了一系列功能以提高开发效率。
良好实践(Good Practices)
良好的代码应该是规范的,所以Google为每一门主流语言都设置了其代码规范(Code Style Guideline)。我自己通过下面的设置使以规范化自己的代码。
// 设置tab的大小为2
"tab_size": 2,
// 使用空格代替tab
"translate_tabs_to_spaces": true,
// 添加行宽标尺
"rulers": [80, 100],
// 显示空白字符
"draw_white_space": "all",
// 保存时自动去除行末空白
"trim_trailing_white_space_on_save": true,
// 保存时自动增加文件末尾换行
"ensure_newline_at_eof_on_save": true,代码段(Code Snippets)
Sublime Text支持代码段(Code Snippet),输入代码段名称后Tab即可生成代码段。

你可以通过Package Control安装第三方代码段,也可以自己创建代码段,参考这里。
格式化(Formatting)
Sublime Text基本的手动格式化操作包括:Ctrl + [向左缩进,Ctrl + ]向右缩进,此外Ctrl + Shift + V可以以当前缩进粘贴代码(非常实用)。
除了手动格式化,我们也可以通过安装插件实现自动缩进和智能对齐:
- HTMLBeautify:格式化HTML。
- AutoPEP8:格式化Python代码。
- Alignment:进行智能对齐。
自动完成(Auto Completion)
Sublime Text 支持一定的自动完成,按Tab自动补全。

括号(Brackets)
编写代码时会碰到大量的括号,利用Ctrl + M可以快速的在起始括号和结尾括号间切换,Ctrl + Shift + M则可以快速选择括号间的内容,对于缩进型语言(例如Python)则可以使用Ctrl + Shift + J。

此外,我使用BracketHighlighter插件以高亮显示配对括号以及当前光标所在区域,效果如下:

命令行(Command Line)
尽管提供了Python控制台,但Sublime Text的控制台仅支持单行输入,十分不方便,所以我使用SublimeREPL以进行一些编码实验(Experiments)。

其它(Miscellaneous)
尽管我试图在本文包含尽可能多的Sublime Text实用技能,但受限于篇幅和我的个人经验,本文仍不免有所遗漏,欢迎在评论里指出本文的错误及遗漏。
下面是一些可能有用但我很少用到的功能:
- 宏(Macro):Sublime Text支持录制宏,但我在实际工作中并未发现宏有多大用处。
- 其它平台(Other Platforms):本文只介绍了Windows平台上Sublime Text的使用,不过Linux和OS X上Sublime Text的使用方式和Windows差别不大,只是在快捷键上有所差异,请参考Windows/Linux快捷键和OS X快捷键。
- 项目(Projects):Sublime Text支持简单的项目管理,但我一般只用到文件夹。
- Vim模式(Vintage):Sublime Text自带Vim模式。
- 构建(Build):通过配置,Sublime Text可以进行源码构建。
- 调试(Debug):通过安装插件,Sublime Text可以对代码进行调试。
快捷键列表(Shortcuts Cheatsheet)
Windows/Linux快捷键和OS X快捷键:
通用(General)
↑ ↓ ← →:上、下、左、右、移动光标,注意不是不是KJHL!Alt:调出菜单Ctrl + Shift + P:调出命令板(Command Palette)Ctrl + `:调出控制台
编辑(Editing)
Ctrl + Enter:在当前行下面新增一行然后跳至该行Ctrl + Shift + Enter:在当前行上面增加一行并跳至该行Ctrl + ←/→:进行逐词移动Ctrl + Shift + ←/→进行逐词选择Ctrl + ↑/↓移动当前显示区域Ctrl + Shift + ↑/↓移动当前行
选择(Selecting)
Ctrl + D:选择当前光标所在的词并高亮该词所有出现的位置,再次Ctrl + D选择该词出现的下一个位置,在多重选词的过程中,使用Ctrl + K进行跳过,使用Ctrl + U进行回退,使用Esc退出多重编辑Ctrl + Shift + L:将当前选中区域打散Ctrl + J:把当前选中区域合并为一行Ctrl + M:在起始括号和结尾括号间切换Ctrl + Shift + M:快速选择括号间的内容Ctrl + Shift + J:快速选择同缩进的内容Ctrl + Shift + Space:快速选择当前作用域(Scope)的内容- 列模式
Windows:
-鼠标右键+Shift
-或者鼠标中键
-增加选择:Ctrl,减少选择:Alt
Linux:
-鼠标右键+Shift
-增加选择:Ctrl,减少选择:Alt
查找&替换(Finding&Replacing)
F3:跳至当前关键字下一个位置Shift + F3:跳到当前关键字上一个位置Alt + F3:选中当前关键字出现的所有位置Ctrl + F/H:进行标准查找/替换,之后:Alt + C:切换大小写敏感(Case-sensitive)模式Alt + W:切换整字匹配(Whole matching)模式Alt + R:切换正则匹配(Regex matching)模式Ctrl + Shift + H:替换当前关键字Ctrl + Alt + Enter:替换所有关键字匹配
Ctrl + Shift + F:多文件搜索&替换
跳转(Jumping)
Ctrl + P:跳转到指定文件,输入文件名后可以:@符号跳转:输入@symbol跳转到symbol符号所在的位置#关键字跳转:输入#keyword跳转到keyword所在的位置:行号跳转:输入:12跳转到文件的第12行。
Ctrl + R:跳转到指定符号Ctrl + G:跳转到指定行号
窗口(Window)
Ctrl + Shift + N:创建一个新窗口Ctrl + N:在当前窗口创建一个新标签Ctrl + W:关闭当前标签,当窗口内没有标签时会关闭该窗口Ctrl + Shift + T:恢复刚刚关闭的标签
屏幕(Screen)
F11 切换至普通全屏 Shift + F11 切换至无干扰全屏
Alt+Shift+1 Single (非小键盘)窗口分屏,恢复默认1屏
Alt+Shift+2 Columns:2 左右分屏-2列
Alt+Shift+3 Columns:3 左右分屏-3列
Alt+Shift+4 Columns:4 左右分屏-4列
Alt+Shift+8 Rows:2 垂直分屏-2屏 (进行上下分2屏)
Alt+Shift+9 Rows:3 垂直分屏-3屏 (进行上下分3屏)
Alt+Shift+5 Grid 等分4屏。即四格式分屏 (进行上下左右分屏)
- 分屏之后,使用
Ctrl + 数字键(分屏序号)跳转到指定屏,使用Ctrl + Shift + 数字键(分屏序号)将当前屏移动到指定屏
Sublime Text 3 快捷键精华版
sulime text 菜单栏各个选项中都会提示相关的快捷键,可以自己去看看。
Ctrl + `: 打开Sublime Text控制台
Ctrl+Shift+P: 打开命令面板
Ctrl+Alt+F: 对代码进行格式化
Ctrl+P: 搜索项目中的文件。查找当前项目中的文件和快速搜索;输入 @ 查找文件主标题/函数;或者输入 : 跳转到文件某行;
Ctrl+G: 跳转到第几行
Ctrl+W: 关闭当前打开文件
Ctrl+Shift+W:关闭所有打开文件
Ctrl+Shift+V: 粘贴并格式化
Ctrl+D: 选择单词,重复可增加选择下一个相同的单词
Ctrl+L: 选择整行,重复可依次增加选择下一行
Ctrl+Shift+L: 选择多行
Ctrl+Shift+Enter:在当前行前插入新行
Ctrl+X: 删除当前行
Ctrl+M: 跳转到对应括号。移动至括号内开始或结束的位置
Ctrl+U: 软撤销,撤销光标位置
Ctrl+J: 合并行(已选择需要合并的多行时)
Ctrl+F: 查找内容
Ctrl+Shift+F: 查找并替换
Ctrl+H: 替换
Ctrl+R: 快速 列出/跳转到 某个函数
Ctrl+N: 新建窗口
Ctrl+K Backspace 从光标处删除至行首
Ctrl+K+B 开启 / 关闭 侧边栏
Ctrl+KK 从光标处删除至行尾
Ctrl+K+T 折叠属性
Ctrl+K+U 改为大写
Ctrl+K+L 改为小写
Ctrl+K+0 展开所有
Ctrl+Enter 插入行后(快速换行)
Ctrl+Tab 当前窗口中的标签页切换
Ctrl+Shift+M: 选中当前括号内容,重复可选着括号本身
Ctrl+F2: 设置/删除标记
Ctrl+/: 注释当前行
Ctrl+Shift+/: 当前位置插入注释
Ctrl+Alt+/: 块注释,并Focus到首行,写注释说明用的
Ctrl+Shift+A: 选择当前标签前后,修改标签用的
F11: 全屏
Shift+F11: 全屏免打扰模式,只编辑当前文件
Alt+F3: 选择所有相同的词
Alt+.: 闭合标签
Alt+Shift+数字: 分屏显示
Alt+数字: 切换打开第N个文件
Shift+右键拖动: 光标多不,用来更改或插入列内容
鼠标的前进后退键可切换Tab文件
按Ctrl,依次点击或选取,可需要编辑的多个位置
按Ctrl+Shift+上下键,可替换行Ctrl+Shift+A 选择光标位置父标签对儿
Ctrl+Shift+D 复制光标所在整行,插入在该行之前
ctrl+shift+F 在文件夹内查找,与普通编辑器不同的地方是sublime允许添加多个文件夹进行查找
Ctrl+Shift+K 删除整行
Ctrl+Shift+L 鼠标选中多行(按下快捷键),即可同时编辑这些行
Ctrl+Shift+M 选择括号内的内容(按住-继续选择父括号)
Ctrl+Shift+/ 注释已选择内容。Ctrl+/ 注释整行(如已选择内容,同“Ctrl+Shift+/”效果)
Ctrl+Shift+↑ 可以移动此行代码,与上行互换
Ctrl+Shift+↓ 可以移动此行代码,与下行互换
Ctrl+Shift+[ 折叠代码
Ctrl+Shift+] 展开代码
Ctrl+Shift+Enter 光标前插入行
Ctrl+PageDown 、Ctrl+PageUp 文件按开启的前后顺序切换
Ctrl+Z 撤销
Ctrl+Y 恢复撤销
Ctrl+F2 设置/取消书签
Ctrl+鼠标左键 可以同时选择要编辑的多处文本
Shift+鼠标右键(或使用鼠标中键) 可以用鼠标进行竖向多行选择
Shift+F2 上一个书签
Shift+Tab 去除缩进
Alt+. 闭合当前标签
Alt+F3 选中文本,然后 按下 快捷键,即可 一次性选择 全部相同的文本 进行 同时 编辑
Tab 缩进 自动完成
F2 下一个书签
F6 检测语法错误
F9 行排序(按a-z)
选择类
Ctrl+D 选中光标所占的文本,继续操作则会选中下一个相同的文本。
Alt+F3 选中文本按下快捷键,即可一次性选择全部的相同文本进行同时编辑。举个例子:快速选中并更改所有相同的变量名、函数名等。
Ctrl+L 选中整行,继续操作则继续选择下一行,效果和 Shift+↓ 效果一样。
Ctrl+Shift+L 先选中多行,再按下快捷键,会在每行行尾插入光标,即可同时编辑这些行。
Ctrl+Shift+M 选择括号内的内容(继续选择父括号)。举个例子:快速选中删除函数中的代码,重写函数体代码或重写括号内里的内容。
Ctrl+M 光标移动至括号内结束或开始的位置。
Ctrl+Enter 在下一行插入新行。举个例子:即使光标不在行尾,也能快速向下插入一行。
Ctrl+Shift+Enter 在上一行插入新行。举个例子:即使光标不在行首,也能快速向上插入一行。
Ctrl+Shift+[ 选中代码,按下快捷键,折叠代码。
Ctrl+Shift+] 选中代码,按下快捷键,展开代码。
Ctrl+K+0 展开所有折叠代码。
Ctrl+← 向左单位性地移动光标,快速移动光标。
Ctrl+→ 向右单位性地移动光标,快速移动光标。
shift+↑ 向上选中多行。
shift+↓ 向下选中多行。
Shift+← 向左选中文本。
Shift+→ 向右选中文本。
Ctrl+Shift+← 向左单位性地选中文本。
Ctrl+Shift+→ 向右单位性地选中文本。
Ctrl+Shift+↑ 将光标所在行和上一行代码互换(将光标所在行插入到上一行之前)。
Ctrl+Shift+↓ 将光标所在行和下一行代码互换(将光标所在行插入到下一行之后)。
Ctrl+Alt+↑ 向上添加多行光标,可同时编辑多行。
Ctrl+Alt+↓ 向下添加多行光标,可同时编辑多行。
编辑类
Ctrl+J 合并选中的多行代码为一行。举个例子:将多行格式的CSS属性合并为一行。
Ctrl+Shift+D 复制光标所在整行,插入到下一行。
Tab 向右缩进。
Shift+Tab 向左缩进。
Ctrl+K+K 从光标处开始删除代码至行尾。
Ctrl+Shift+K 删除整行。
Ctrl+/ 注释单行。
Ctrl+Shift+/ 注释多行。
Ctrl+K+U 转换大写。
Ctrl+K+L 转换小写。
Ctrl+Z 撤销。
Ctrl+Y 恢复撤销。
Ctrl+U 软撤销,感觉和 Gtrl+Z 一样。
Ctrl+F2 设置书签
Ctrl+T 左右字母互换。
F6 单词检测拼写
搜索类
Ctrl+F 打开底部搜索框,查找关键字。
Ctrl+shift+F 在文件夹内查找,与普通编辑器不同的地方是sublime允许添加多个文件夹进行查找,略高端,未研究。
Ctrl+P 打开搜索框。举个例子:1、输入当前项目中的文件名,快速搜索文件,2、输入@和关键字,查找文件中函数名,3、输入:和数字,跳转到文件中该行代码,4、输入#和关键字,查找变量名。
Ctrl+G 打开搜索框,自动带:,输入数字跳转到该行代码。举个例子:在页面代码比较长的文件中快速定位。即 跳转到相应的行。
Ctrl+R 打开搜索框,自动带@,输入关键字,查找文件中的函数名。举个例子:在函数较多的页面快速查找某个函数。
Ctrl+: 打开搜索框,自动带#,输入关键字,查找文件中的变量名、属性名等。
Ctrl+Shift+P 打开命令框。场景例子:打开命名框,输入关键字,调用sublime text或插件的功能,例如使用package安装插件。
Esc 退出光标多行选择,退出搜索框,命令框等。
显示类
Ctrl+Tab 按文件浏览过的顺序,切换当前窗口的标签页。
Ctrl+PageDown 向左切换当前窗口的标签页。
Ctrl+PageUp 向右切换当前窗口的标签页。
Alt+Shift+1 窗口分屏,恢复默认1屏(非小键盘的数字)
Alt+Shift+2 左右分屏-2列
Alt+Shift+3 左右分屏-3列
Alt+Shift+4 左右分屏-4列
Alt+Shift+5 等分4屏
Alt+Shift+8 垂直分屏-2屏
Alt+Shift+9 垂直分屏-3屏
Ctrl+K+B 开启/关闭侧边栏。
F11 全屏模式
Shift+F11 免打扰模式
2、Notepad++
Notepad++ 是 Windows 下的一款免费开源代码编辑器,它使用较少的CPU功率,降低电脑系统能源消耗,但轻巧且执行效率高,使得 Notepad++ 可完美地取代微软视窗的记事本(功能对比Windows的记事本强大很多,但比 Vim,Emacs 还是有很大不如,当然 EditPlus,UltraEdit 也是非常好的选择,可惜这两个是收费软件)。内置支持多达27种语法高亮度显示(包括各种常见的源代码、脚本,能够很好地支持.nfo文件查看),还支持自定义语言;可自动检测文件类型,根据关键字显示节点,节点可自由折叠/打开,还可显示缩进引导线,代码显示得很有层次感;可打开双窗口,在分窗口中又可打开多个子窗口,允许快捷切换全屏显示模式(F11),支持鼠标滚轮改变文档显示比例;提供了一些有用工具,如邻行互换位置、宏功能等;可显示选中文本的字节数 (而不是一般编辑器所显示的字数,这在某些情况下,比如 软件本地化 很方便)。
下载、安装
github 下载地址:Notepad++ · GitHub

设置 主题、字体
菜单栏 ---> 设置 ---> 语言格式设置。 上、下 键可以预览效果

插件安装
安装插件的两种方式( 推荐 使用插件管理工具安装 ):
1. 手动安装
notepad-plus-plus/nppPluginList:GitHub - notepad-plus-plus/nppPluginList: The official collection of Notepad++ plugins.

2. 通过插件管理工具安装( 点击插件 ---> 插件管理 )

然后可以看到一个插件列表,选择要安装的插件进行安装即可

推荐插件:
- Exploer:这个插件可以让你在编辑器里面直接访问电脑本地的文件,不用再跳出去打开文件了,非常方便。
- NppFTP:连接远程服务器,然后在notepad++上修改远程服务器上的文本文件。(喜欢用vim的大神忽略我说的)。
- NppExec:这个插件可以在notepa++里面直接打开系统的命令行,省去切换工作窗口的烦恼。
- JSTool:JS 的代码神器。可以格式化JS代码,可以将JS代码进行最小化压缩,也可以解压别人的最小化JS代码。还可以查看json数据,可将JSON数据格式化,并且有一个专门解析好的视图让你看,还可以让JSON数据重新排序。
- XML Tools:可以格式化和校验XML。
使用 Ctrl+Alt+Shif+P 获取当前Xpath路径。
使用 Ctrl+Alt+Shif+B 格式化当前XML。
使用 Ctrl+Alt+Shif+M 校验当前XML。 - Zen Coding:前端开发神器,特有一套简易Coding规则。(参看:分享Notepad++ 史上最牛的插件 - HTML+CSS - php中文网博客)
- Compare:文件对比工具,很简单,也很强大。( 备注:需要 分屏 才能进行对比)
快捷键 Ctrl+Alt+C 进行对比。
快捷键 Ctrl+Alt+X 取消对比。 - Json Viewer:使字符串格式的json转成标准json格式
配置 Python 开发
Notepad++配置 Python 开发环境:Notepad++配置Python开发环境 - 金石开 - 博客园
配置 制表符

自动完成

配置调试工具:

浏览器关联
编写好HTML页面后,之前我总是要缩小工作窗口,然后去找到文件所在的地方,再右键,选择某个浏览器打开。哇,这一套下来真的很繁琐。之后我发现原来notepad++,可以通过一些设置,和选定浏览器关联起来。设置好快捷键后,直接用快捷键就可以让浏览器打开你正在编写的HTML文件了。
首先,你找到你想要选择的浏览器的启动程序的所在位置,我就拿谷歌浏览器为例。我的是:C:\Users\Administrator\AppData\Local\Google\Chrome\Application\chrome.exe

运行 ---> 输入运行程序名
输入C:\Users\Administrator\AppData\Local\Google\Chrome\Application\chrome.exe "$(FULL_CURRENT_PATH)"
注意别漏了中间的空格和双引号

点击保存,自己输入这个命令的名字和定义快捷键

设置完成之后就可以用快捷键打开你的 HTML 页面了
运行 java 文件
简单的使用 notepad++ 运行 java 文件,复杂点的指令可以自己研究.
首先,下载 NppExec 这款插件。按 F6,打开如下界面并输入:

输入的内容:
NPP_SAVE
cd "$(CURRENT_DIRECTORY)"
javac "$(FILE_NAME)"
java "$(NAME_PART)"
这样你就可以运行当前简单的 java 类(因为如果有复杂的话,需要指明类路径这些)
用户手册
- 快速开始
- 处理 文件
- 编辑
- 搜索
- 查看
- 会话、工作区、项目
- 功能 列表
- 自动 完成
- 高亮显示 - 内置语言
- 高亮显示 - 用户定义的语言
- 宏 - 任务自动化
- 运行外部命令
- 插件
- Plugin Communication
- 命令行 参数
- 首选项
- 配置文件详细信息
- 主题
- 本地化 - 用户界面翻译
- 升级
- 右击 - 用notepad++编辑
- Ghost Typing
- Other Resources
- User Manual History
- Copyright & License
快捷键
文件
新建文件 Ctrl+N
打开文件 Ctrl+O
保存文件 Ctrl+S
另存为 Ctrl+Alt+S
全部保存 Ctrl+Shift+S
关闭当前文件 Ctrl+W
打印文件 Ctrl+P
退出 Alt+F4编辑
撤销 Ctrl+Z
恢复 Ctrl+Y
剪切 Ctrl+X
复制 Ctrl+C
删除 Del
全选 Ctrl+A
列编辑 Alt+C缩进 Tab
删除缩进 Shift+Tab
转为大写 Ctrl+Shift+U
转为小写 Ctrl+U复制当前行 Ctrl+D
删除当前行 Ctrl+L
分割行 Ctrl+I
合并行 Ctrl+J
上移当前行 Ctrl+Shift+Up
下移当前行 Ctrl+Shift+Down
添加/删除单行注释 Ctrl+Q
设置行注释 Ctrl+K
取消行注释 Ctrl+Shift+K
区块注释 Ctrl+Shift+Q
函数自动完成 Ctrl+Space搜索
查找 Ctrl+F
在文件中搜索 Ctrl+Shift+F
查找下一个 F3
查找上一个 Shift+F3
选定并找下一个 Ctrl+F3
行定位 Ctrl+G
定位匹配括号 Ctrl+B
设置/取消书签 Ctrl+F2
下一书签 F2
上一书签 Shift+F2视图
全屏 F11
便签模式 F12
折叠所有层次 Alt+0
展开所有层次 Alt+Shift+0
折叠当前层次 Ctrl+Alt+F
展开当前层次 Ctrl+Alt+Shift+F
隐藏行 Alt+H
从视图激活 F8文本比较工具
打开的文件比较 Alt+D
关闭文件比较 Ctrl+Alt+D
跟上次保存的文件比较 Alt+S
跟SVN的文件比较 Alt+B
上一个差异地方 Ctrl+PageUP
下一个差异地方 Ctrl+PageDown
第一个差异地方 Ctrl+Shift+PageUp
最后一个差异地方 Ctrl+Shift+Page Down

















 3699
3699

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









