






这半年来一直做文档阅读器相关的事情,后来无意中发现了 pdf.js ,这真是一个宝库,为啥这样说?
大多数人不会看它的源码,除非你想要用它做点高难度的事。其实大多数人目的是在网页中显示 pdf 文件,曾经看到过一篇文章,在安卓端用 pdf.js 来渲染 pdf 文档。
最近看了它的源码,感触颇深,和大家随便聊聊。
把它的代码下载下来,跑起来,用它来渲染《你不知道的JS》这本电子书。可以看到,效果非常棒,有目录、缩略图、页面任意切换、全文检索、自由缩放等等,效果如下:
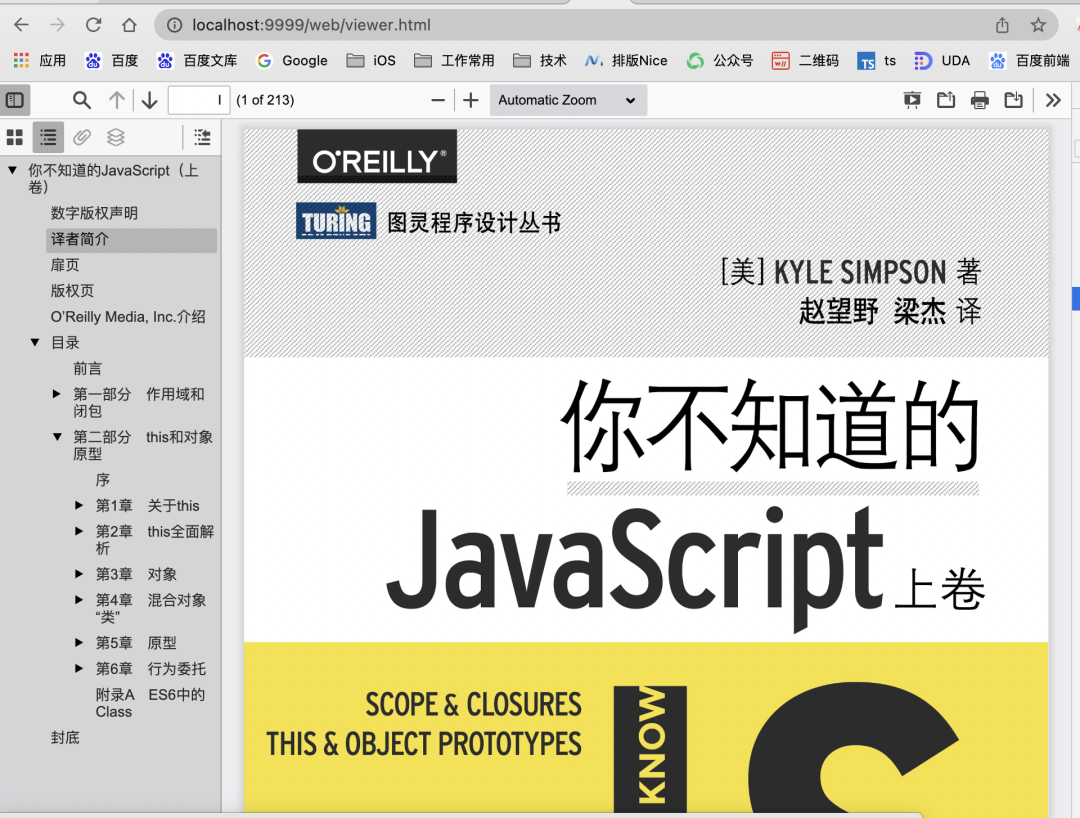

这一切是如何实现的呢?
pdfjs 总共分为3层,每层负责不同的事情:
core层:负责pdf文件的解析,通过这层可以把 pdf 转换成 json,比如 pdf2json 这个库做了这件事情;
display层:提供一些便捷的 API 供显示PDF文档使用,包含了 pdf 的渲染;
viewer层:一个完整的PDF阅读器,支持了一些功能,比如翻页、缩放、阅读模式切换等;
下面分享一些实现思路:
采用什么方式渲染、文本选择如何做?
使用 Canvas 渲染,文本选择直接使用的HTML自带的文本选择。我们可以看下 DOM 结构,包含两层,一层是用 Canvas 绘制的,用户所看到的内容,另一层是透明的,用来做文本选择。不过文本选择会出现来回跳动的问题,但是能够解决左右分栏文本选择的问题。
大文档,如何渲染,如何保证性能?
对于大文档来说主要采用只渲染可视区域的文档内容,对不不可见的内容进行释放内存空间,每次页面即将出现时会重新渲染。当然也做了 LRU 缓存策略。渲染的时候,会优先渲染用户能够看到的页面,然后再渲染当前页面的前后几页,这样能保持用户滑动就能过看到内容。
左侧的缩略图是如何渲染的?

主内容区域和缩略图数据是共用的,缩略图直接使用渲染好的 Canvas 转换成 Image,然后放到左侧缩略图的位置上。
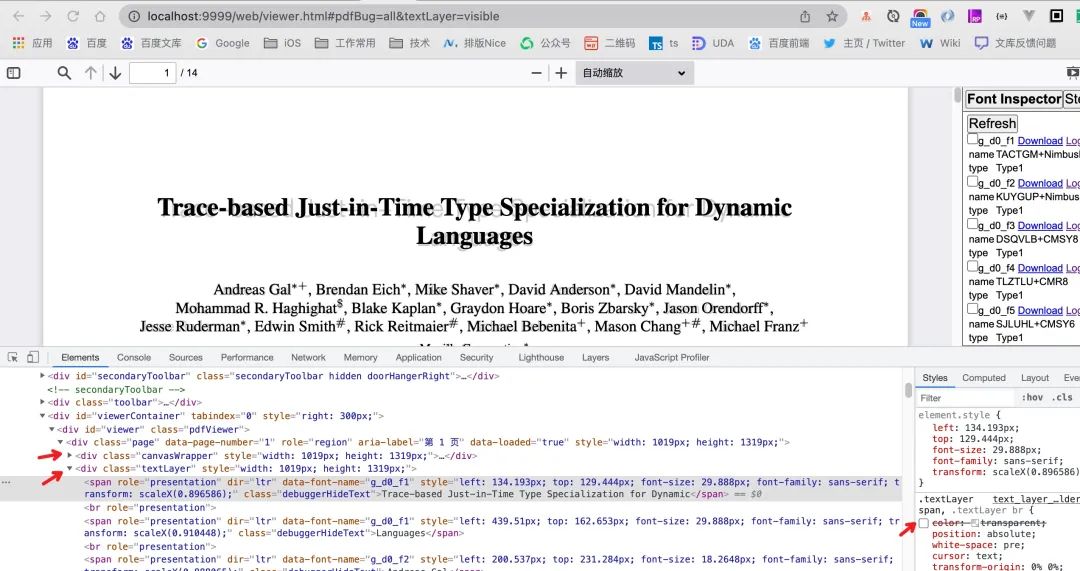
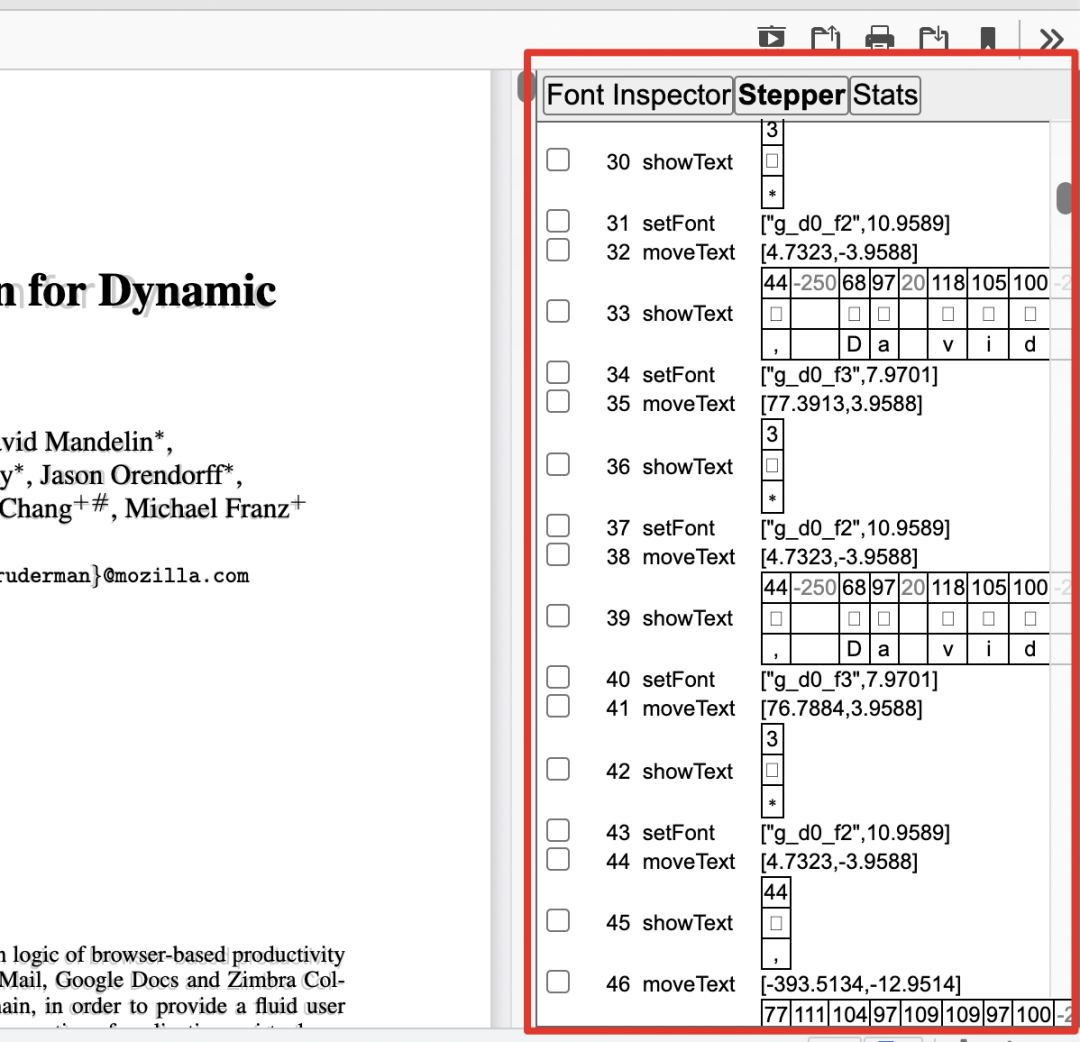
如何 debug?
不得不说,pdf.js 有专门的调试工具,可查看每页的渲染状态。需要在 url 后加上 hash 值,调试面板会自动打开:
/viewer.html#pdfBug=all&textLayer=visible
总得来说,pdf.js 实现起来非常有难度,代码量也很大,看他的源码不太容易,不过起码对我来说作用比较大。后面在看源码的过程中遇到有意思的知识和大家再分享。
大家加油















 1894
1894











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









