







大概在2年多前也就是22年9月,英伟达正式发布了RTX 40系列中的旗舰GeForce RTX 4090,这款显卡大家关注更多的是相比上一代的GeForce RTX 3090性能提升了多少?在人工智能如此蓬勃发展的今天,在深度学习,推理方面这两台机器的对比又如何呢?
1、全方位参数对比
内存与带宽:显存方面,这两款显卡都是24GB。GPU显存(Graphics Processing Unit Video Random Access Memory),也称为显存或显示内存,是专门为图形处理单元(GPU)设计的内存,用于存储和管理GPU在渲染图形时所需的数据。

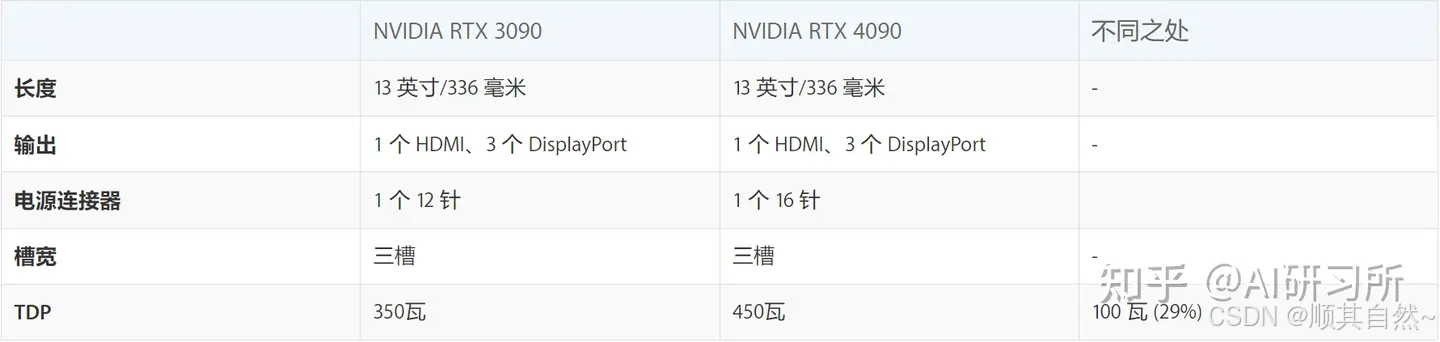
时钟速度:GPU时钟速度是指图形处理单元(GPU)的核心运行速度,它代表了GPU中多个核心渲染图像的速度。GPU时钟速度的高低会影响GPU处理数据的能力,即GPU的快慢。这一点上4090各方面都比3090强大不少

电路板设计:4090对比3090能耗相对更高,大约30%左右。
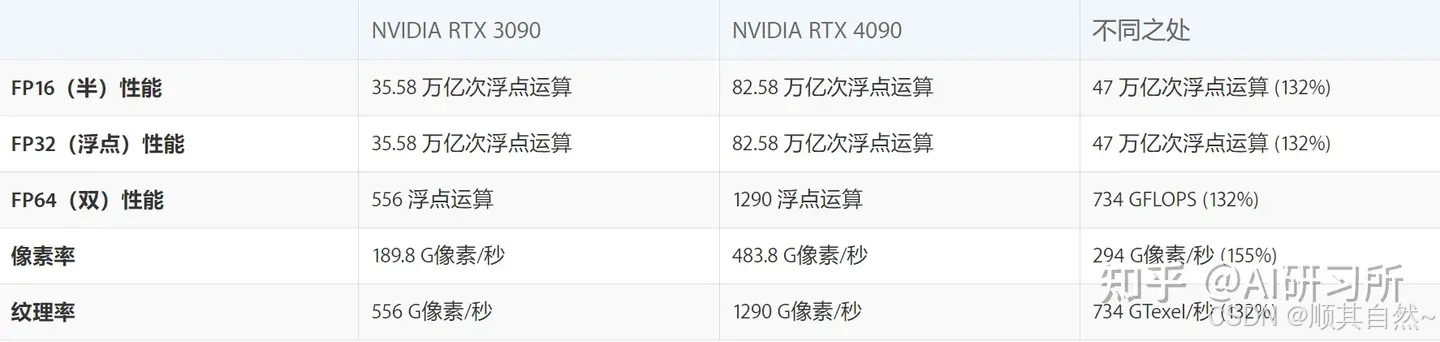
理论性能:4090FP16(半精度浮点数)、FP32(双精度浮点数)、FP64(双精度浮点数)、像素填充率、纹理率性能全方面高于3090。
像素填充率指的是GPU每秒钟可以绘制图像的像素数。这对于游戏等需要高清晰度图像的应用来说尤为重要。纹理填充率指的是GPU每秒钟可以呈现的纹理像素数量,也就是图形中所需的表面纹理贴图。纹理填充率越高,计算机的图像处理速度也会更快。
2、模型推理方面对比
高性价比4090平台:
4090推理显卡低至2.6元/时-UCloud中立云计算服务商
在ResNet50的能力对比中,4090的性能是3090的1.5倍。ResNet50是一种深度学习模型,由微软研究院的研究人员在2015年提出。"ResNet"的全称是"Residual Network",意为"残差网络","50"则表示这个网络包含50层。
ResNet50的主要特点是引入了"残差块"(Residual Block)。在传统的神经网络中,每一层都是在前一层的基础上添加新的变换,而在ResNet中,每一层都是在前一层的基础上添加新的变换,同时还保留了前一层的原始输入,这就是所谓的"残差"。这种设计使得网络可以更好地学习输入和输出之间的差异,而不是直接学习输出,这有助于提高模型的性能。

3、AI绘画能力对比
3090:基于Ampere架构旗舰产品3090,24G大显存,三星代工和高规格带来的巨大发热量。在stable diffusion测试中一共用时21秒,speed:13.68it/s,平均每张图用时2.1秒。
4090:基于Ada Lovelace架构旗的4090相比3090的CUDA Core提升了75%,达到了恐怖的18432 个!在stable diffusion测试中只用了17秒就全部完成10张小姐姐的画图快得离谱,speed:17.68it/s,平均每张图用时1.7秒。
| 显卡型号 | SD绘图时间(秒) | SD单位效率(it/s) |
| 3090 | 21 | 13.68 |
| 4090 | 17 | 17.68 |
总体无论是基本的参数还是在推理方面的能力,4090对比3090各方面都有不小的提升。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









