






自回归语言模型(Causal Language Modeling,简称 Causal LM)是一类通过 条件概率 生成文本的语言模型,它的工作原理是根据输入序列中的前面部分(上下文),依次生成后续的每一个词。这种模型的训练和推理过程是 从左到右 或 从前到后 的,这意味着在生成每个词时,只能依赖已经生成的词,而不能使用未来的信息。
工作原理
在训练或推理过程中,自回归语言模型会根据序列中已经生成的词预测下一个词,生成的过程是逐步完成的。它基于条件概率的思想,预测每个词的概率依赖于之前生成的所有词。
假设我们有一个词序列
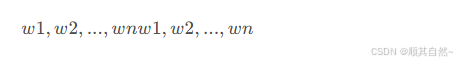
那么自回归语言模型的目标是学习该序列的联合概率分布:
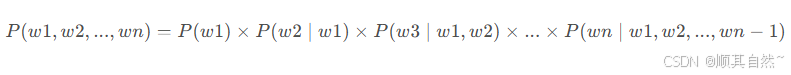
通过依次条件化每个词,它将整个句子的生成过程分解为一系列的逐步预测,即:
1)预测第一个词w1
2)基于 w1预测第二个词 w2
3)基于 w1,w2 预测第三个词 w3
4)… 直到预测完整个句子。
这种生成方式保证了在生成过程中,每个词只能“看”到它之前生成的词,而无法访问未来的词,因此叫做 自回归。
自回归模型的特点
1)单向性(从左到右):在生成过程中,模型只能根据已经生成的内容预测下一个词,无法使用未来词的信息。因为预测是逐步进行的,未来的词对当前词的预测没有影响。
2)逐词生成:自回归模型会一个词一个词地生成。它依赖前面的词来生成后续的词,形成一个因果关系,因此被称为“Causal”(因果的)。
3)适合生成任务:自回归模型特别适合生成式任务,如文本生成、代码生成等。经典模型如 OpenAI 的 GPT 系列(GPT-2、GPT-3)就是自回归语言模型。
应用场景
1)文本生成
自回归模型广泛应用于生成文本的任务。给定一个初始输入,模型可以生成一个连续的文本片段,常用于对话系统、自动写作、故事生成等任务。
例如:GPT-3 是一个典型的自回归语言模型,可以根据一个提示生成文章、诗歌或代码。
2)对话系统
自回归模型可以用来生成对话回复。例如,聊天机器人可以根据用户的对话历史生成一个符合上下文的回应。
3)机器翻译(部分方法)
在一些情况下,自回归模型用于翻译任务,逐步生成目标语言中的每个词。
4)代码自动补全
自回归模型也可以应用于代码生成或代码补全任务,比如 GitHub Copilot 就利用了自回归语言模型来辅助编程。
与其他模型的对比
1)与 BERT 类模型的区别
BERT 类模型(如 BERT、RoBERTa)使用的是 双向(bidirectional)或遮掩语言模型(Masked Language Modeling),它在预测某个词时能够同时利用前后上下文的信息。这使得 BERT 模型在 自然语言理解(NLU) 任务中表现得很好,例如文本分类、问答、文本相似度等任务。
自回归模型则只能从左到右进行生成,更适合 自然语言生成(NLG) 任务,例如生成文本、对话系统等。
2)与 Seq2Seq 模型的区别
序列到序列(Seq2Seq)模型是另一种生成模型,常用于翻译、摘要生成等任务。这类模型通常有一个编码器-解码器架构,编码器处理输入序列,解码器在逐步生成每个词时可以访问编码器的整个输入序列信息(即可以同时使用前向和反向的上下文)。
自回归语言模型没有编码器,纯粹依赖先前的生成词进行预测。
总结
1)自回归语言模型是一种从左到右逐步生成词的语言模型,只能基于前面的词预测后续词,广泛用于文本生成和生成式任务。
2)自回归语言模型(Causal Language Modeling) 强调了生成过程中预测的因果性,即只能基于已经生成的内容来生成新的内容,而不能使用未来的信息。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









