







 本文介绍了Spark中RDD的基本概念,包括transformation与action的区别、narrow dependency与wide dependency的概念及其影响,同时还提供了RDD cache的默认设置及Spark支持的语言API,并通过具体案例展示了如何使用Spark进行数据处理。
本文介绍了Spark中RDD的基本概念,包括transformation与action的区别、narrow dependency与wide dependency的概念及其影响,同时还提供了RDD cache的默认设置及Spark支持的语言API,并通过具体案例展示了如何使用Spark进行数据处理。
- RDD执行transformation和执行action的区别是什么?
1、transformation是得到一个新的RDD,方式很多,比如从数据源生成一个新的RDD,从RDD生成一个新的RDD
2、action是得到一个值,或者一个结果(直接将RDDcache到内存中)。所有的transformation都是采用的懒策略,就是如果只是将transformation提交是不会执行计算的,计算只有在action被提交的时候才被触发。 - 说明narrow dependency 和 wide dependency的区别? 从计算和容错两方面说明!
在Spark中,每一个 RDD 是对于数据集在某一状态下的表现形式,而这个状态有可能是从前一状态转换而来的,因此换句话说这一个 RDD 有可能与之前的 RDD(s) 有依赖关系。根据依赖关系的不同,可以将 RDD 分成两种不同的类型: Narrow Dependency 和 Wide Dependency 。
Narrow Dependency 指的是 child RDD 只依赖于 parent RDD(s) 固定数量的partition。
Wide Dependency 指的是 child RDD 的每一个partition都依赖于 parent RDD(s) 所有partition。
它们之间的区别可参看下图: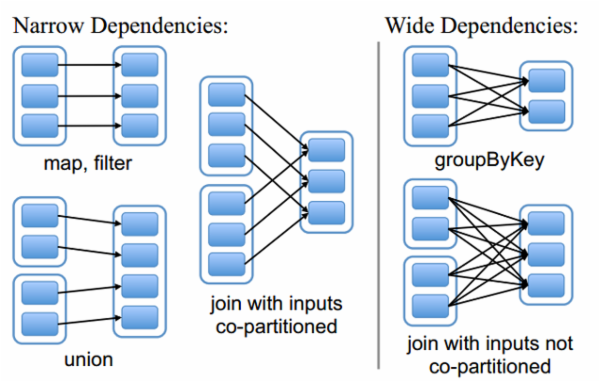
根据 RDD 依赖关系的不同,Spark也将每一个job分为不同的stage,而stage之间的依赖关系则形成了DAG。对于 Narrow Dependency ,Spark会尽量多地将 RDD 转换放在同一个stage中;而对于 Wide Dependency ,由于 Wide Dependency 通常意味着shuffle操作,因此Spark会将此stage定义为 ShuffleMapStage ,以便于向 MapOutputTracker 注册shuffle操作。对于stage的划分可参看下图,Spark通常将shuffle操作定义为stage的边界。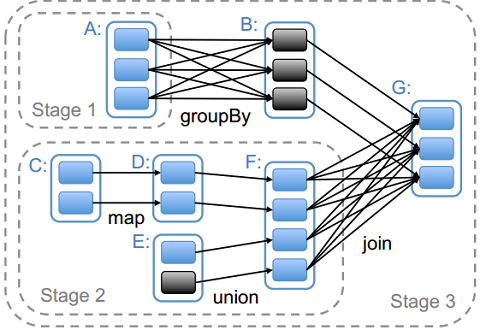
3. RDD cache默认的StorageLevel级别是什么?
1)RDD的cache()方法其实调用的就是persist方法,缓存策略均为MEMORY_ONLY;
2)可以通过persist方法手工设定StorageLevel来满足工程需要的存储级别;
3)cache或者persist并不是action;
4. Spark目前支持哪几种语言的API?
Scala API/Java API/Python API
5. 下载搜狗实验室用户查询日志精版:http://www.sogou.com/labs/dl/q.html (63M),做以下查询:
1) 用户在00:00:00到12:00:00之间的查询数?
package cn.chinahadoop.scala
import org.apache.spark.{SparkContext, SparkConf}
object SogouA {
def main(args: Array[String]) {
if (args.length == 0) {
System.err.println("Usage: SogouA <file1>")
System.exit(1)
}
val conf = new SparkConf().setAppName("SogouA")
val sc = new SparkContext(conf)
val sgRDD=sc.textFile(args(0))
sgRDD.map(_.split('\t')(0)).filter(x => x >= "00:00:00" && x <= "12:00:00").saveAsTextFile(args(1))
sc.stop()
}
}客户端运行命令:
./spark-submit
--master spark://SparkMaster:7077
--name chinahadoop
--class cn.chinahadoop.scala.SogouA
/home/chinahadoop.jar
hdfs://SparkMaster:9000/data/SogouQ.reduced
hdfs://SparkMaster:9000/data/a2) 搜索结果排名第一,但是点击次序排在第二的数据有多少?
package cn.chinahadoop.scala
import org.apache.spark.{SparkContext, SparkConf}
object SogouB {
def main(args: Array[String]) {
if (args.length == 0) {
System.err.println("Usage: SogouB <file1>")
System.exit(1)
}
val conf = new SparkConf().setAppName("SogouB")
val sc = new SparkContext(conf)
val sgRDD=sc.textFile(args(0))
println(sgRDD.map(_.split('\t')).filter(_.length ==5).map(_(3).split(' ')).filter(_(0).toInt ==1).filter(_(1).toInt ==2).count)
sc.stop()
}
}客户端运行命令:与上雷同
3)一个session内查询次数最多的用户的session与相应的查询次数?
package cn.chinahadoop.scala
import org.apache.spark.{SparkContext, SparkConf}
import org.apache.spark.SparkContext._
object SogouC {
def main(args: Array[String]) {
if (args.length == 0) {
System.err.println("Usage: SogouC <file1>")
System.exit(1)
}
val conf = new SparkConf().setAppName("SogouC")
val sc = new SparkContext(conf)
val sgRDD=sc.textFile(args(0))
sgRDD.map(_.split('\t')).filter(_.length ==5).map(x=>(x(1),1)).reduceByKey(_+_).map(x=>(x._2,x._1)).sortByKey(false).map(x=>(x._2,x._1)).take(10).foreach(println)
sc.stop()
}
}客户端运行命令:与上雷同



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











