本文转自http://blog.csdn.net/sunshine_in_moon/article/details/53541573,并修改了其中一丁点儿问题。非常感谢博主的分享,跟着博主的攻略一步步做下来,完全实现,没有问题。
请注意如果.py文件中有中文,请在文件开头加上# -*- coding: utf-8 -*-,否则会报错yntaxError:Non-ASCII character '\xe6' in file,文章最后原博主给的下载代码中没有这句话,需要大家手动加上。
另外代码是Python2.7版本的,如果是Python3版本的,运行会出错,解决方案请参考http://blog.csdn.net/zyx19950825/article/details/61919038
本篇博客主要讲述怎样在Windows下利用Caffe提供的脚本程序和Caffe训练日志画loss曲线与accuracy曲线。如果你是在Linux下使用Caffe可以参考这篇博客:http://blog.csdn.net/fx409494616/article/details/53197209?ref=myread。
如果你还没有Caffe训练日志,请参考上一篇博客http://blog.csdn.net/fuwenyan/article/details/62418108,生成自己的训练日志。
好了废话少说,直接上干货!!!
1、修改tools/extra/plot_training_log.py,这里面需要修改的东西太多了,我们分步讲解,可能代码优点乱,大家不要介意。
1.1、生成*****log.test,*****log.train两个文件
方法一:利用tools/extra/parse_log.py文件
- python parse_log.py ****.log save_path
第一个参数:我们的训练日志,后缀名必须是".log",其实这也不是必须的,我们可以修改plot_training_log.py中子函数
- def get_log_file_suffix():
- return '.log'
第二个参数:保存路径,执行上述命令后会生成两个文件****.log.test,****.log.train。
方法二:将生成这两个文件集成到plot_training_log.py中。我们首先看一下两个plot_training_log.py文件中的子函数
- def get_log_parsing_script():
- dirname = os.path.dirname(os.path.abspath(inspect.getfile(
- inspect.currentframe())))
- return dirname + '/parse_log.sh'
返回的是parse_log.sh脚本的路径,看来要调用这个脚本,但是我们知道在Windows下是无法使用shell脚本的。所以我们需要修改调用这个shell脚本的地方。就在下面这个子函数
- def plot_chart(chart_type, path_to_png, path_to_log_list):
- for path_to_log in path_to_log_list:
-
-
- train_dict_list, test_dict_list = parse_log.parse_log(path_to_log)
- parse_log.save_csv_files(path_to_log, './', train_dict_list,test_dict_list)
-
- data_file = get_data_file(chart_type, path_to_log)
- x_axis_field, y_axis_field = get_field_descriptions(chart_type)
- x, y = get_field_indices(x_axis_field, y_axis_field)
- data = load_data(data_file, x, y)
-
- color = [random.random(), random.random(), random.random()]
- label = get_data_label(path_to_log)
- linewidth = 0.75
-
-
- use_marker = True
- if not use_marker:
- plt.plot(data[0], data[1], label = label, color = color,
- linewidth = linewidth)
- else:
- ok = False
-
- while not ok:
- try:
- marker = random_marker()
- plt.plot(data[0], data[1], label = label, color = color,
- marker = marker, linewidth = linewidth)
- ok = True
- except:
- pass
- legend_loc = get_legend_loc(chart_type)
- plt.legend(loc = legend_loc, ncol = 1)
- plt.title(get_chart_type_description(chart_type))
- plt.xlabel(x_axis_field)
- plt.ylabel(y_axis_field)
- plt.savefig(path_to_png)
- plt.show()
看到了第一句就是调用shell脚本,我们将其注释掉,然后利用parse_log.py文件中的子函数来实现相同的功能。
2.2、Caffe提供的工具可以生成8种不同的曲线
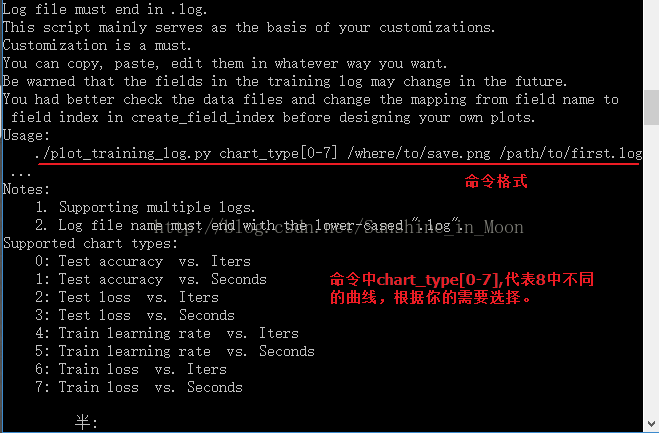
1.3、修改子函数creat_field_index()
- def create_field_index():
- train_key = 'Train'
- test_key = 'Test'
- field_index = {train_key:{'Iters':0, 'Seconds':1, train_key + ' learning rate':2,
- train_key + ' loss':3},
- test_key:{'Iters':0, 'Seconds':1, 'learning rate':2,test_key + ' accuracy':3,
- test_key + ' loss':4}}
- fields = set()
- for data_file_type in field_index.keys():
- fields = fields.union(set(field_index[data_file_type].keys()))
- fields = list(fields)
- fields.sort()
- return field_index, fields
主要修改的地方就是field_index,这要根据你前面生成的****.log.test和****.log.train两个文件中第一行的单词的顺序修改字典对应顺序。我此处的修改是根据我的文件,切记一定要和你的文件核对,否则生成的曲线是不对的。我已经测试过8种曲线都能正确画出。
2.4、修改load_data()
- def load_data(data_file, field_idx0, field_idx1):
- data = [[], []]
- fr = open(data_file,'r')
- lines = fr.readlines()
- for i in range(1,len(lines)):
- line = lines[i].strip()
- if line[0] != '#':
- fields = line.split(',')
- data[0].append(float(fields[field_idx0].strip()))
- data[1].append(float(fields[field_idx1].strip()))
- fr.close()
- return data
之所以修改这个函数,因为原函数是从****.log.test和****.log.train的第一行读取数据,但是第一行是单词如法转换成浮点数,必须从第二行开始读取数据。
OK,到此为止,需要修改的地方基本上已经没有了。
需要注意两点:
1、保存的图片默认后缀名.png,如果你想保存成其他后缀名,可修改下面的代码
- path_to_png = sys.argv[2]
- if not path_to_png.endswith('.png'):
- print 'Path must ends with png' % path_to_png
2、Windows命令格式
- python plot_training_log.py 7 train.png INFO2016-12-09T12-54-26.log
结果如下:
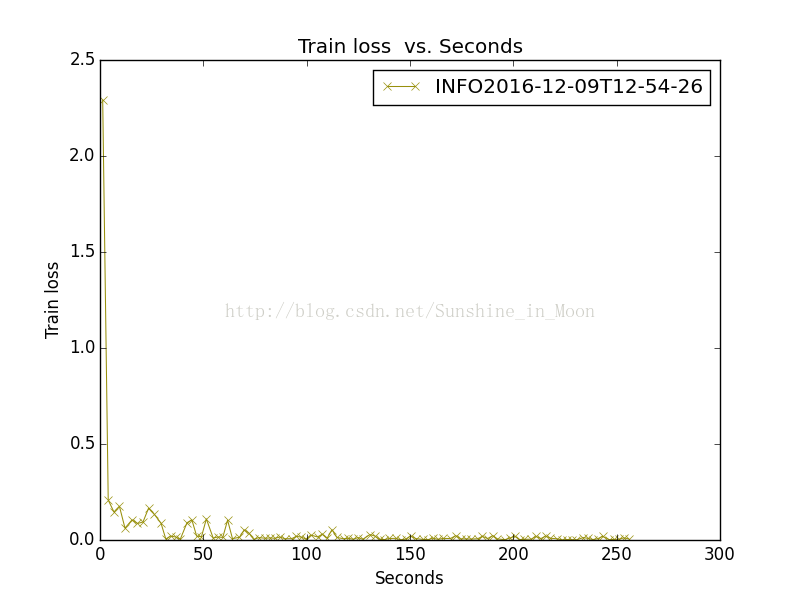
是不是很酷!
修改后的完整代码请到此处下载:http://download.csdn.net/detail/sunshine_in_moon/9706954
下载积分为5分,毕竟辛辛苦苦改了很长时间,请多多支持。如果你的积分确实有限,可以给我留言并附上邮箱。
























 651
651











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









