







 本文详细介绍了如何基于ncnn架构使用MTCNN进行人脸检测和特征点标定,包括关键参数解释、图像金字塔生成、Pnet、Rnet和Onet的工作流程,以及附带的代码解析。
本文详细介绍了如何基于ncnn架构使用MTCNN进行人脸检测和特征点标定,包括关键参数解释、图像金字塔生成、Pnet、Rnet和Onet的工作流程,以及附带的代码解析。
本博记录为卤煮理解,如有疏漏,请指正。转载请注明出处。
卤煮:非文艺小燕儿
本文主要讲述当你拿到MTCNN的caffemodel后,如何使用它对一张图里的人脸进行检测和特征点标定。
相当于一个代码实现的解释。因为最近卤煮在用ncnn,所以该代码也是基于ncnn架构做的。 caffe架构同理。
如果你对MTCNN这篇论文还不熟悉,建议先去看原理。也可以用我之前写的相关博客做参考:
MTCNN解读:Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks
1. MTCNN关键参数
nms_threshold:非极大值抑制nms筛选人脸框时的IOU阈值,三个网络可单独设定阈值,值设置的过小,nms合并的少,会产生较多冗余计算。示例nms_threshold[3] = { 0.5, 0.7, 0.7 };。
threshold:人脸框得分阈值,三个网络可单独设定阈值,值设置的太小,会有很多框通过,也就增加了计算量,还有可能导致最后不是人脸的框错认为人脸。示例threshold[3] = {0.8, 0.8, 0.8};
minsize :最小可检测图像,该值大小,可控制图像金字塔的阶层数的参数之一,越小,阶层越多,计算越多。示例minsize = 40;
factor :生成图像金字塔时候的缩放系数, 范围(0,1),可控制图像金字塔的阶层数的参数之一,越大,阶层越多,计算越多。示例factor = 0.709;
输入图片的尺寸,minsize和factor共同影响了图像金字塔的阶层数。用户可根据自己的精度需求进行调控。
MTCNN整体过程只管图示如下:
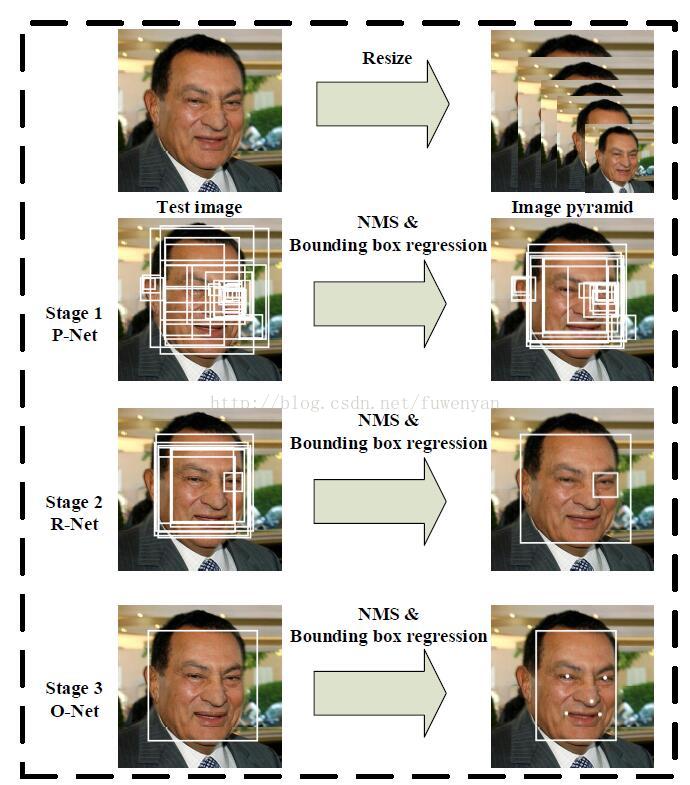
2. 生成图像金字塔
前面提到,输入图片的尺寸,minsize和factor共同影响了图像金字塔的阶层数。也就是说决定能够生成多少张图。
缩放后的尺寸minL=org_L*(12/minisize)*factor^(n),n={0,1,2,3,...,N},缩放尺寸最小不能小于12,也就是缩放到12为止。n的数量也就是能够缩放出图片的数量。
看到上面这个公式应该就明白为啥那三个参数能够影响阶层数了吧。
3. Pnet运算
一般Pnet只做检测和人脸框回归两个任务。忽略下图中的Facial landmark。
< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3168
3168

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









