









Lua的Table的内存结构主要分array part和hash part,它们俩的内存大小是动态变化的,如果空间不够就需要分配更多的空间,如果空间利用率太少就需要缩减内存,这个过程叫做rehash。
现在来看看rehash是怎么样的过程。
rehash内部,主要是做了以下几件事:
a.计算array part的key的数量
b.计算hash part的key的数量
c.计算新设的key之后array part部分的数量,
d.计算一个新的array part部分需要分配的内存大小
e.resize。(大概过程如上,后面是每个步骤的细节,如不需要了解,可以跳到最后了。)
static void rehash (lua_State *L, Table *t, const TValue *ek) {
int nasize, na;
int nums[MAXBITS+1]; /* nums[i] = number of keys with 2^(i-1) < k <= 2^i */
int i;
int totaluse;
for (i=0; i<=MAXBITS; i++) nums[i] = 0; /* reset counts */
nasize = numusearray(t, nums); /* count keys in array part */
totaluse = nasize; /* all those keys are integer keys */
totaluse += numusehash(t, nums, &nasize); /* count keys in hash part */
/* count extra key */
nasize += countint(ek, nums);
totaluse++;
/* compute new size for array part */
na = computesizes(nums, &nasize);
/* resize the table to new computed sizes */
luaH_resize(L, t, nasize, totaluse - na);
} 一、rehash过程:根据需要新设置的key,计算出array部分和hash部分:
1.计算当前array part的数量
(1)计算函数是numusearray(ltable.c, line:229),array part实际按2的指数增长,新增部分为一个切片。例如1,2,4,8增长,切片分为(1,2,3~4,5~8)四片,[2^(lg-1), 2^lg]
(2)遍历每一个切片,统计每个不为nil的下标,直到统计次数大于array的长度(2的指数),同时记录每一个切片的不为空的数量(存为nums, 留待后面计算使用)。
(3)把统计结果返回,即为array部分的数量。
2.计算当前hash part的数量
(1)计算函数为numusehash(ltable.c, line:254),这个函数会做两个统计:hash part的数量,以及keys为正整数在hash part的数量。
(2)遍历hash部分,计算hash part的总数量
(3)遍历hash部分,同时计算key为number在hash部分的数量,而且把这些数量加到array part上面去,同时所属的切片数量nums也会加1。(注意,有一些正整数的key-value,会放在hash部分。)
3.把array part和hash part的数量加起来,并且加1(加1是把新设的加进去)
4.判断新设的key是否属于array part,如果是,array part的数量增加1,并且所属性切片的数量nums也增加1。(另一层意思是:如果不是,则属性hash part,总量已变,array part数量不变,相当于hash part总量加1)
5.根据新设置key以后的table情况,计算array part需要分配size.
(1)根据第1,2,4步骤,会计算到一个最新的nums数组,这个是为最新的array part记录
(2)根据nums这个记录,计算array part部分到底需要分配多少空间,计算函数是computesizes((ltable.c, line:196))。
(3)computesizes的计算过程:
i.根据array part的总量,遍历每一个切片,累加遍历到当前切片的总量。
ii.如果累加的当前切片总量,对于当前切片假设要分配的数量,超过一半的使用率,则先记为最优的分配size.
举例子来说:假设当前数组为{1,2,3,nil, nil, nil, nil, nil, nil, 10}, 切片标记数组nums应该为[1,1,1,0,1]
遍历第一个切片时,累加总量为1,应该分配的数量为2^0=1,使用率为100%,当前最优的分配size为1,在array part数量为1;
遍历第二个切片时,累加总量为1+1=2,应该分配的数量为2^1=2,使用率为100%,当前最优的分配size为2,在array part数量为2;
遍历第三个切片时,累加总量为2+1=3,应该分配的数量为2^2=4,使用率为75%,当前最优的分配size为4,在array part数量为3;
遍历第四个切片时,累加总量为3+0=3,应该分配的数量为2^3=8,使用率3/8为37.5%,最优的分配size不需要修改;
遍历第五个切片时,累加总量为3+1=4,应该分配的数量为2^4=16,使用率4/16为25%,最优的分配size不需要修改;
此时总量和数量总量相同,遍历计算结束。所以最优分配size为4, array part会有3个节点被使用。
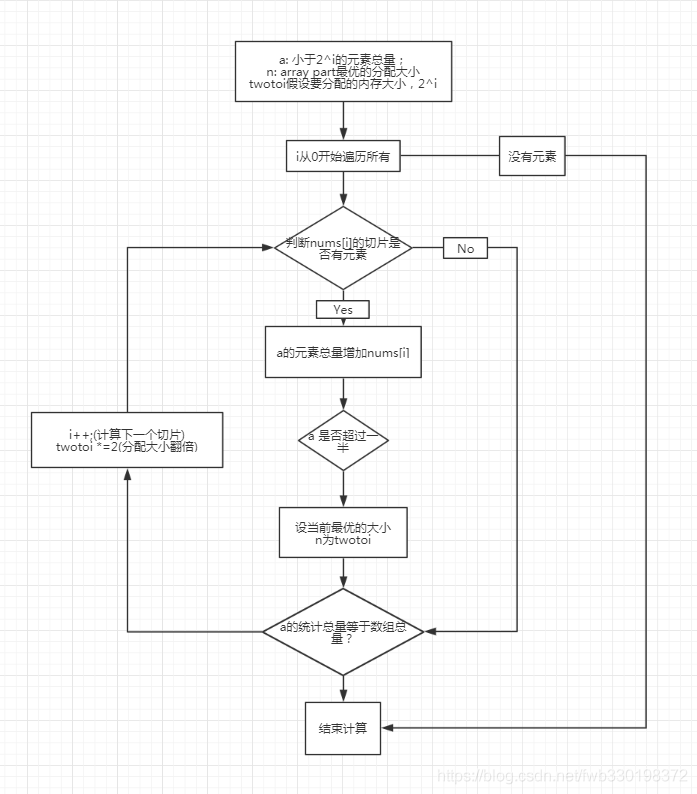
6.根据计算得出的array part占用的数量(不是分配的size)和总量相减,得出hash part的数量,用array part和hash part的总量进行resize.对于array part,内存需要扩容的时候调用setarrayvector,而在最后调用的是原生接口:realloc。realloc的实现方法是:先在该内存块后面检查是否有足够的空间进行扩容,如果可以,则在该内存块后面增加需要扩容的空间;否则,需要申请一块新的内存块进行扩容。
二、最后:使用table时的建议。
尽量可以提前分配大小,明确知道table的内容或者知道大小的,可以先预先初始化。例如:
(1)不建议:local tb = {}; tb[1] = 1; tb[2] = 2; tb[3] = 3; 因为这样会多次触发rehash
(2)建议:local tb = {nil, nil, nil},或者local tb = {1, 2, 3},后面再作赋值操作














 4037
4037











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









