









Master-Worker设计模式介绍
Master-Worker模式是常用的并行设计模式。核心思想是,系统由两个角色组成,Master和Worker,Master负责接收和分配任务,Worker负责处理子任务。任务处理过程中,Master还负责监督任务进展和Worker的健康状态;Master将接收Client提交的任务,并将任务的进展汇总反馈给Client。各角色关系如下图
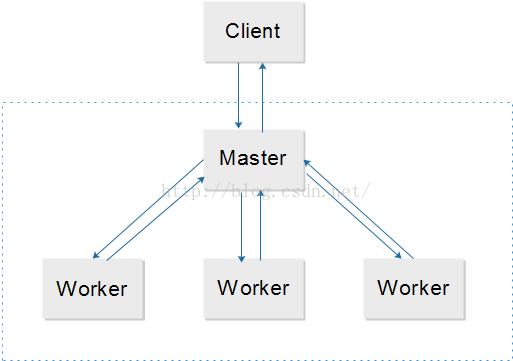
Master-Worker模式满足于可以将大任务划分为小任务的场景,是一种分而治之的设计理念。通过多线程或者多进程多机器的模式,可以将小任务处理分发给更多的CPU处理,降低单个CPU的计算量,通过并发/并行提高任务的完成速度,提高系统的性能。
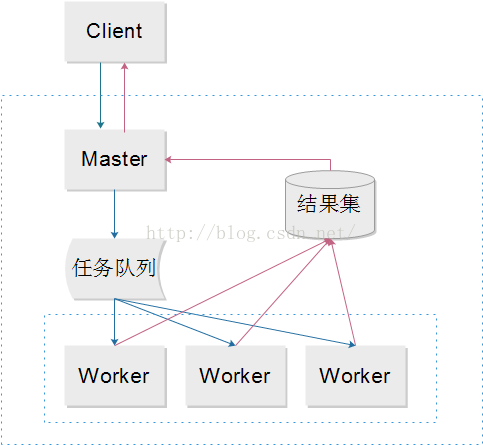
具体细节如上图,Master对任务进行切分,并放入任务队列;然后,触发Worker处理任务。实际操作中,任务的分配有多种形式,如Master主动拉起Workder进程池或线程池,并将任务分配给Worker;或者由Worker主动领取任务,这样的Worker一般是常驻进程;还有一种解耦的方式,即Master指做任务的接收、切分和结果统计,指定Worker的数量和性能指标,但不参与Worker的实际管理,而是交由第三方调度监控和调度Worker。
1.Master类的编写
public class Master {
// 1.应该有一个装任务的集合ConcurrentLinkedQueue
private ConcurrentLinkedQueue<Object> workQueue = new ConcurrentLinkedQueue<Object>();
// 2.使用普通的HashMap去承装所有的Worker对象
private Map<String, Thread> workers = new HashMap<String, Thread>();
// 3.要用一个ConcurrentHashMap去承装每一个Worker执行任务的结果集合,并发执行
private ConcurrentHashMap<String, Object> resultMap = new ConcurrentHashMap<String, Object>();
// 4.要有一个构造方法
public Master(Worker worker, Integer workerCount) {
// 创建worker对Maset中任务队列的引用,用于任务的领取
worker.setWorkerQueue(this.workQueue);
// 创建worker对Maset中结果集合的引用,用于任务的提交
worker.setResultMap(this.resultMap);
// 循环为多个worker创建线程
for (int i = 0; i < workerCount; i++) {
workers.put("W" + String.valueOf(i), new Thread(worker));
}
}
// 5.提交方法
public void Submit(Object obj) {
this.workQueue.add(obj);
}
// 6.启动应用程序,让所有的worker开始工作
public void execute() {
// 启动每个worker线程开始工作
for (Map.Entry<String, Thread> me : workers.entrySet()) {
me.getValue().start();
}
}
// 7.判断线程是否执行完毕
public boolean isComplete() {
// 判断当所有的worker是否都停止
for (Map.Entry<String, Thread> me : workers.entrySet()) {
if (me.getValue().getState() != Thread.State.TERMINATED) {
return false;
}
}
return true;
}
// 8.获取worker的计算结果
public int getResult() {
int sum = 0;
for (Map.Entry<String, Object> me : resultMap.entrySet()) {
sum += (int) me.getValue();
}
return sum;
}
}
1.首先我们需要在Master中定义一个承装任务的集合,那这里的集合我们选择什么好呢?这里不涉及到阻塞,所以我们选择ConcurrentLinkedQueue就好。
2.我们还要选择一个普通的HashMap来装worker,因为他不涉及到高并发。
3.要选择一个容器来承装worker计算的结果集,这个结果集涉及到多线程操作,那么我们选择使用ConcurrentHashMap
4.要创建一个构造方法,把任务集合和结果集合的队列和ConcurrentHashMap传入到每一个worker作为引用!因为每个worker都要从队列中拿取任务然后再把结果集都存放在ConcurrentHashMap这个结果集中,在这个构造方法中要把每一个workr实例对象装到Master的hashMap中。
5.要有一个提交任务的方法Submit,把任务装到队列中。
6.要有个执行的方法execute,让每一个worker线程都启动start方法。
7.创建一个判断线程是否结束的方法isComplete,如果结束就获取结果集计算,在这个方法中写一个while循环去判断是否线程都已经结束,如果都结束就代表所有任务都已经计算完成。
8.创建一个方法获取ConcurrentHashMap中的所有结果集并且计算,上面这个例子中我们计算了Task中的price的和。
2.Worker类的编写如下
public class Worker implements Runnable{
//定义每一个ConcurrentLinkedQueue队列去引用Master中的ConcurrentLinkedQueue
private ConcurrentLinkedQueue<Object> workQueue;
//定义一个ConcurrentHashMap去引用Master中的ConcurrentHashMap承装计算的结果集
private ConcurrentHashMap<String,Object> resultMap;
//创建ConcurrentLinkedQueue引用
public void setResultMap(ConcurrentHashMap<String, Object> resultMap) {
this.resultMap = resultMap;
}
//创建ConcurrentHashMap引用
public void setWorkerQueue(ConcurrentLinkedQueue<Object> workQueue) {
this.workQueue = workQueue;
}
//真正执行业务的方法
public static Object handle(Object input) {
Object output=null;
return output;
}
//run方法中放计算逻辑
@Override
public void run() {
while(true){
//从队列中取出任务并删除
Object input = workQueue.poll();
//当队列中无元素退出循环
if(null==input)
break;
Object output = Data.handle(input);
this.resultMap.put(Integer.toString(input.hashCode()),output);
}
}
}
1.定义每一个ConcurrentLinkedQueue队列去引用Master中的ConcurrentLinkedQueue。
2.定义一个ConcurrentHashMap去引用Master中的ConcurrentHashMap承装计算的结果集。
3.创建ConcurrentLinkedQueue和ConcurrentHashMap的引用。
4.run方法中放计算逻辑。
5.真正执行业务的方法,此处handle方法中只做了定义,这样当我们有任务要执行时可以创建一个类去继承Worker类,这样就可以更加的灵活,也体现了面向对象的继承。
3.创建Data类去阶乘Worker,重写handle方法
public class Data extends Worker{
public static Object handle(Object input) {
try {
Thread.sleep(500);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
Task task = (Task) input;
Object output = task.getPrice();
return output;
}
}
4.创建一个Task类对象
public class Task {
private int id;
private String name;
private int price;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getPrice() {
return price;
}
public void setPrice(int price) {
this.price = price;
}
}
5.创建一个Client端去测试Master-Worker方法
public class Client {
public static void main(String[] args) {
System.out.println(Runtime.getRuntime().availableProcessors());//获取机器的可用线程
Master master = new Master(new Data(),Runtime.getRuntime().availableProcessors());
//提交任务
Random random = new Random();
for(int i=1;i<=100;i++){
Task task = new Task();
task.setId(i);
task.setName("name"+i);
task.setPrice(random.nextInt(1000));
master.Submit(task);
}
//开始执行
master.execute();
//执行开始时间
long start = System.currentTimeMillis();
while (true) {
//判断当所有线程都结束后打印结果
if (master.isComplete()) {
long end = System.currentTimeMillis()-start;//看执行耗时
int result = master.getResult();
System.out.println("执行结果 "+ result + " 执行时间 " + end);
break;
}
}
}
}
6.打印结果
4
执行结果 54205 执行时间 12503
我们发现java.lang.Runtime.availableProcessors() 方法返回到Java虚拟机的可用的处理器数量。此值可能会改变在一个特定的虚拟机调用。应用程序可用处理器的数量是敏感的,因此偶尔查询该属性,并适当地调整自己的资源使用情况.我的机器是4,每个人的结果可能不同,我们用4个worker去执行大概需要12S,可以改变上面Client中Worker的数量测试结果。发现,开的Worker数量越大,计算所用时间就越短!
总结:
Master-Worker模式是一种将串行任务并行化的方案,被分解的子任务在系统中可以被并行处理,同时,如果有需要,Master进程不需要等待所有子任务都完成计算,就可以根据已有的部分结果集计算最终结果集。
---------------------
作者:荒野的尘埃
来源:CSDN
原文:https://blog.csdn.net/a347911/article/details/53421102
版权声明:本文为博主原创文章,转载请附上博文链接!














 1609
1609











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









