







前言
分布式系统设计中,在极大提高可用性、容错性的同时,带来了一致性问题(CAP理论),Raft协议就是解决分布式中的一致性问题。最近研究了 Raft协议,谈谈自己对 Raft 协议的理解。希望这篇文章能够帮助大家理解。
raft协议是什么?
Raft协议是一种分布式一致性算法(共识算法),共识就是多个节点对某一个事件达成一致的算法,即使出现部分节点故障,网络延时等情况,也不影响各节点,进而提高系统的整体可用性。Raft是使用较为广泛的分布式协议,我们熟悉的etcd注册中心就采用了这个算法;
Raft算法将分布式一致性分解为多个子问题,包括Leader选举(Leader election)、日志复制(Log replication)、安全性(Safety)、日志压缩(Log compaction)等。raft将系统中的角色分为领导者(Leader)、跟从者(Follower)和候选者(Candidate)。
- Leader:接受客户端请求,并向Follower同步请求日志,当日志同步到大多数节点上后高速Follower提交日志。
- Follower:接受并持久化Leader同步的日志,在Leader告知日志可以提交后,提交日志。当Leader出现故障时,主动推荐自己为候选人。
- Candidate:Leader选举过程中的临时角色。向其他节点发送请求投票信息,如果获得大多数选票,则晋升为Leader。

Raft要求系统在任意时刻最多只有一个Leader,正常工作期间只有Leader和Follower,Raft算法将时间划分为任意不同长度的任期(Term),每一任期的开始都是一次选举,一个或多个候选人会试图称为Leader,在成功选举Leader后,Leader会在整个任期内管理整个集群,如果Leader选举失败,该任期就会因为没有Leader而结束,开始下一任期,并立刻开始下一次选举。

Leader选举
Raft使用心跳机制来触发领导者选举,当服务器启动时,初始化都是Follower身份,由于没有Leader,Followers无法与Leader保持心跳,因此,Followers会认为Leader已经下线,进而转为Candidate状态,然后Candidate向集群其他节点请求投票,同意自己成为Leader,如果Candidate收到超过半数节点的投票(N/2 +1),它将获胜成为Leader。

Leader向所有Follower周期性发送heartbeat,如果Follower在选举超时时间内没有收到Leader的heartbeat,就会等待一段随机的时间后发起一次Leader选举。

日志同步
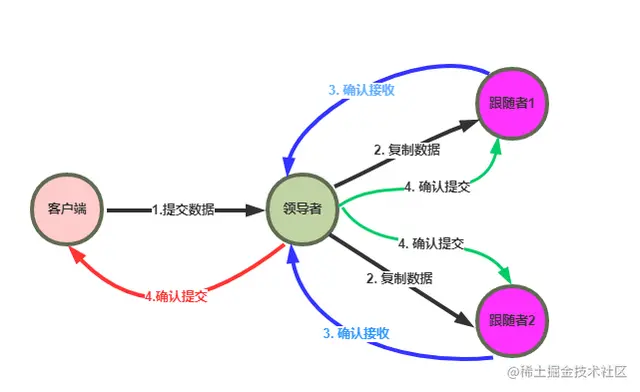
Raft算法实现日志同步的具体过程如下:
Leader收到来自客户端的请求,将之封装成log entry并追加到自己的日志中;Leader并行地向系统中所有节点发送日志复制消息;- 接收到消息的节点确认消息没有问题,则将
log entry追加到自己的日志中,并向Leader返回ACK表示接收成功; Leader若在随机超时时间内收到大多数节点的ACK,则将该log entry应用到状态机并向客户端返回成功。
总结
Raft协议是解决分布式中的一致性问题的算法,包括Leader选举(Leader election)、日志复制(Log replication)、安全性(Safety)、日志压缩(Log compaction)等。
Raft算法会先选举出Leader,Leader完全负责replicated log的管理,Leader负责接受所有客户端更新请求,然后复制到Follower,并在“安全”的时候执行这些请求,如果Leader故障,Follower会重新选举出新的Leader,保证一致性。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









