






一. Milvus多租户方案
Milvus 支持四个级别的多租户:数据库、Collection、Partition 和Partition Key。
数据库 : 最多64个数据库(64个租户)
Collections :每个 Collections 拥有自己的 Schema,同一个数据库下最多可容纳 65,536 个 Collection,Collection相当于表
Partition : 每个 Collections最多1,024 个分区,默认为default分区,可以crud分区,将实体插入分区,指定collection_name和partition_name:
Partition Key:如果指定一个,标量字段作为 Partition Key 时,Milvus会自定在Collection 中创建 16 个Partition 分区。还可以指定分区数量num_partitions
二. 过期时间
可以在Collections 级别设置TTL过期时间,过期的实体不会被搜索到,但会默认在内存在保留24个小时.
以秒为单位的整数
三. Milvus 提供四种不同 GuaranteeTs 的一致性级别。
对一致性要求较高,设置为强(有延迟),希望能快速返回的设置小点。
强:使用最新的时间戳作为 GuaranteeTs,查询节点必须等到服务时间满足 GuaranteeTs 后才能执行搜索请求。
会话:客户端插入数据的最新时间点被用作 GuaranteeTs,这样查询节点就能对客户端插入的所有数据执行搜索。
有限制的停滞(默认的):GuranteeTs 设置为早于最新时间戳的时间点,以便查询节点在执行搜索时能容忍一定的数据丢失。
最终:GuaranteeTs 设置为极小值(如 1),以避免一致性检查,这样查询节点就可以立即对所有批次数据执行搜索请求。
四. 常见的相识度算法
Milvus 支持这些类型的相似性度量:欧氏距离 (L2)、内积 (IP)、余弦相似度 (COSINE)和BM25 (专门为稀疏向量的全文检索而设计)

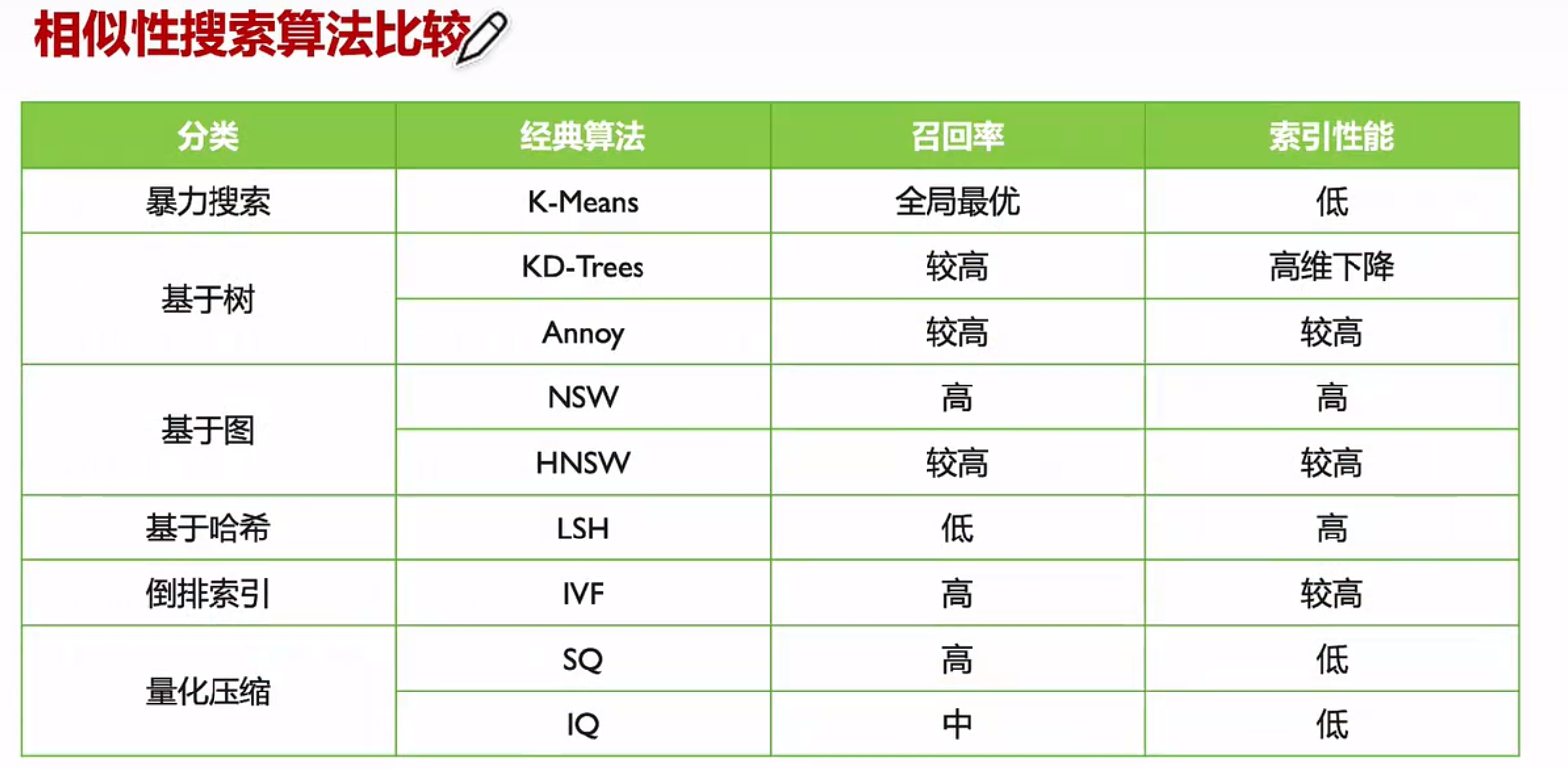
五. 相似性搜索分类
除了暴力搜索能找到最近邻的向量外,其他任何算法都只能得到一些【近似的】结果,这些算法就是
ANN 近似近邻(Approximate Nearest Neighbors)
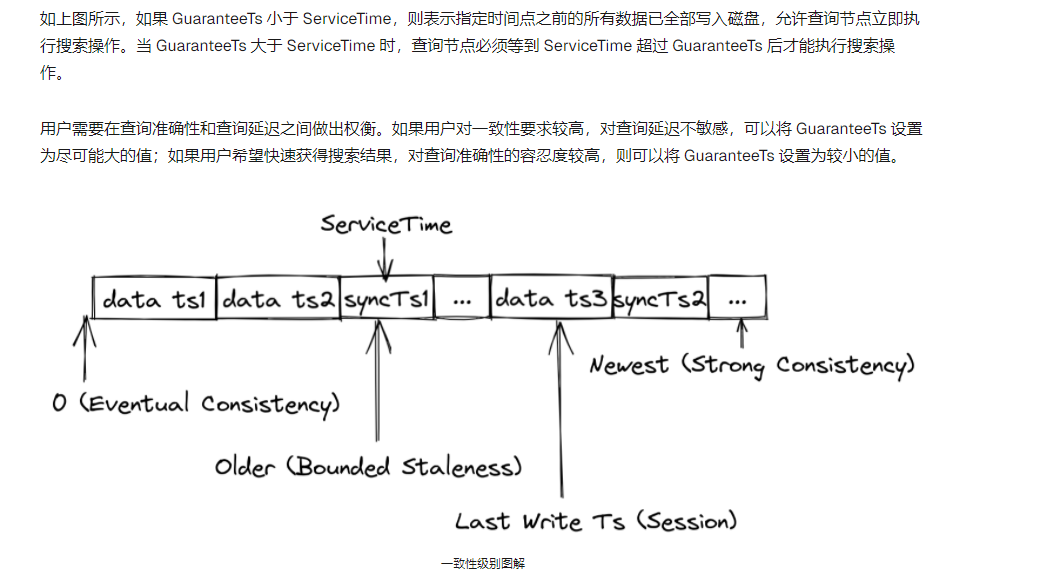
1.按数据结构分类:
哈希: 统一个hash算法时,向量相近的容易发生碰撞,被分到同一个桶中,只需要在同一个桶中快速搜索就行
树:
图:分层导航小世界(HNSW)— 类似跳表
根据一个公式l(v) = floor(-ln(uniform(0, 1)) * mL),mL = 1 / ln(M) ,公式里面会有随机数,每个向量节点通过公式得到一个数,然后取整,得到它应该从第几层开始插入,新节点找到 最近的 参数:efConstruction 个候选节点进行连接,但不能超过最大连接数M,最底层包含所有的向量节点。这个公式中最重要的一个参数是,M为每个节点最大连接数
查询:
从顶层的一个入口点开始,使用贪婪算法找到该层的最近邻
将该点作为下一层的起点,继续搜索
逐层下探,直到最底层,找到最终的近似最近邻. 参数ef 控制近邻检索时的搜索范围,这个参数只适用于底层,最终从ef中找出前k个跟q最近的向量
反转文件:
使用k-means算法,将向量空间聚类为几个区域,比如nlist为4,则分为4个区,每个区都有一个中心点,周围的向量离哪个中心点近,就分到哪个区,然后计算出每个区的平均向量点,把中心点的位置更新为平均的向量点,在重新判断所有向量和哪个中心点近,就分到哪个区,重复这个训练过程,直到中心点趋于稳定。然后用query查询的向量去比较4个中心点中最近的点,找到对应的区,在暴力搜索那个区.
nlist:分区的数量, nprobe:候选区的数量,可以调大着2个参数来解决候选向量可能并不是准确的最近向量问题,但会增加搜索时间
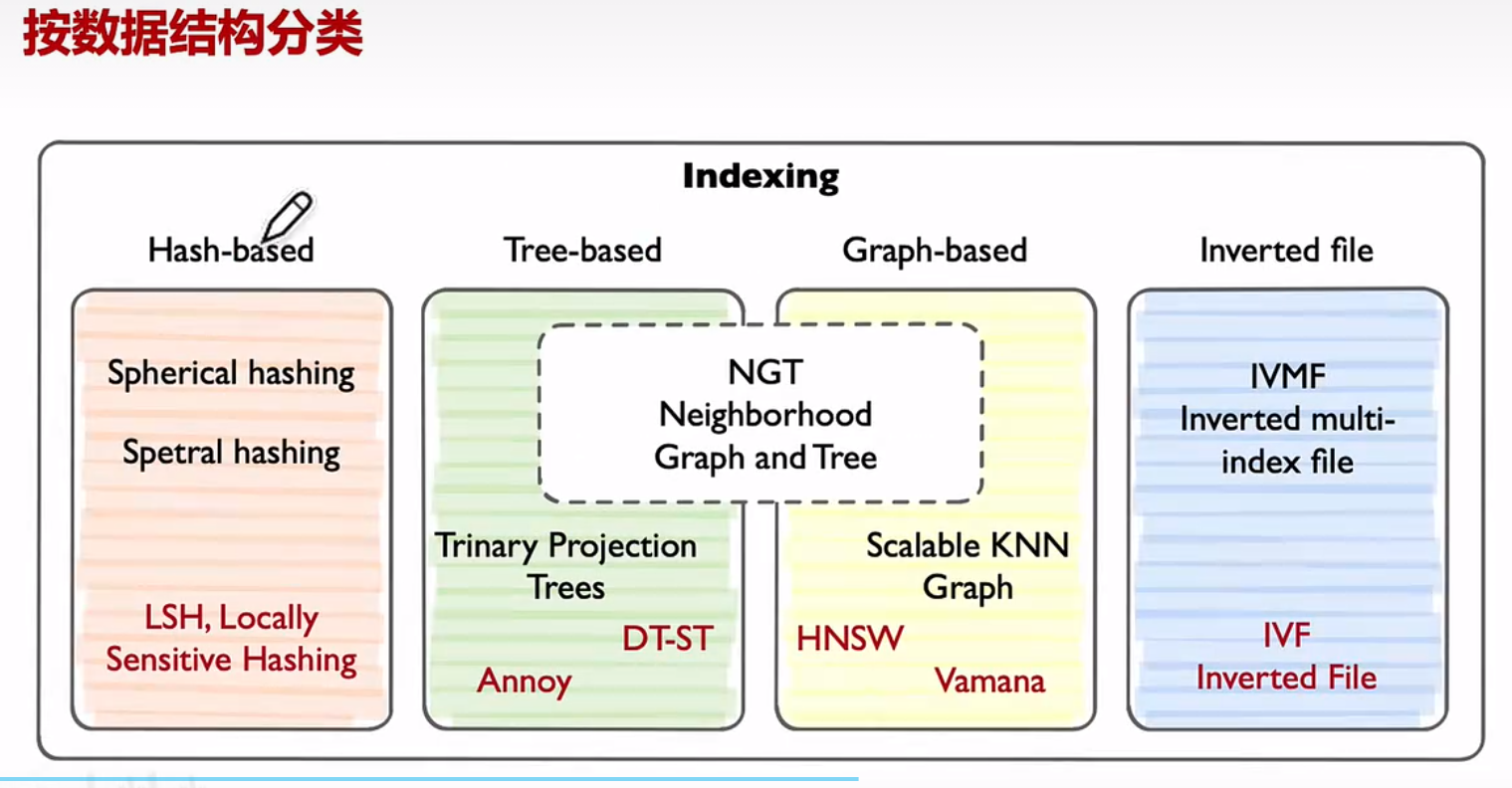
2.按压缩分类:
实现方式:向量被分解为较少字节组成的块,以减少搜索期间内存的消耗和计算成本优点:检索更快
缺点:降低了准确性
扁平化索引:直接计算查询向量和DB中向量的距离
量化索引 : 将索引算法(IVF,HNSW)与量化方法相结合,减少内存的占用,加快索引速度
量化索引分类:SQ(标准量化),PQ(乘积量化)
PQ:为了节约空间,先将高维的向量转换成N(4)个低维的子向量,每个子向量都用k-means算法,子向量的中心点去代表那个区的所有向量,只保留中心点的索引(映射表),这样原始向量量化编码值就约等于4个子向量合并的量化编码值,这样大大的节省的空间
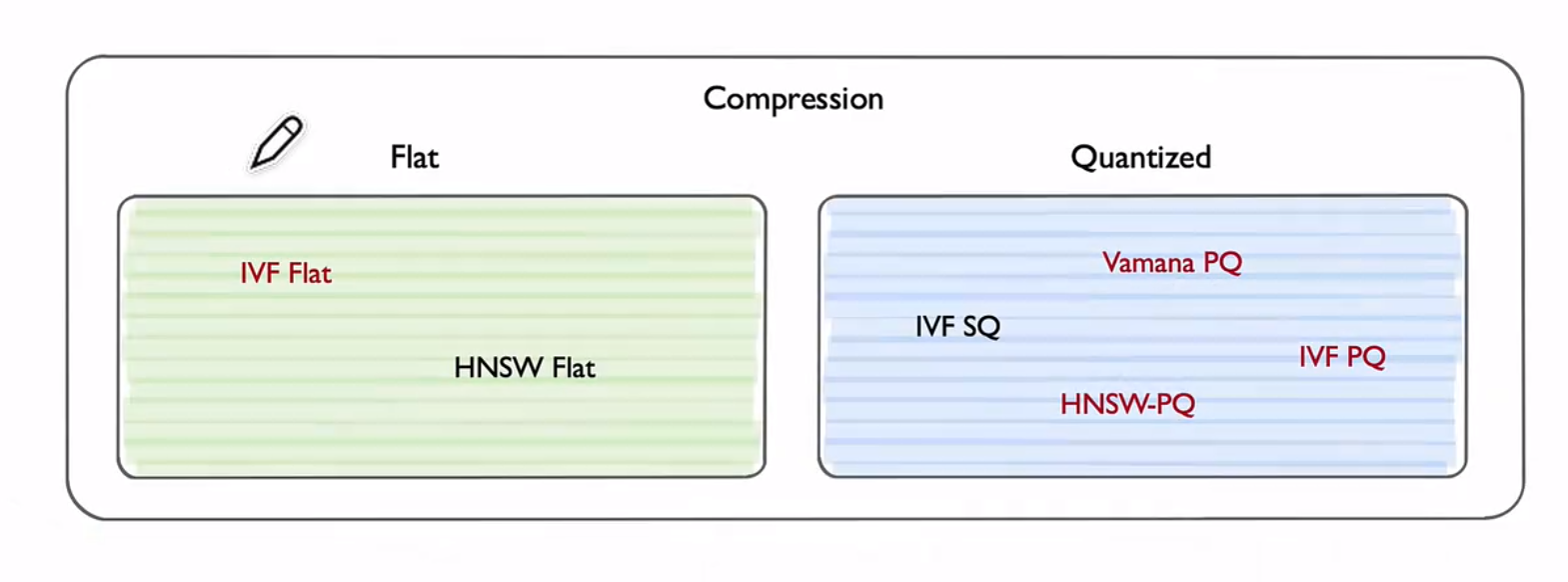
常用的两个IVF_FLAT和HNSW算法比较



六. JSON 索引
地址
Milvus 可以添加Json类型的字段,但是如果没有指定索引的情况下,对 JSON 字段的查询需要全 Collection 扫描,随着数据集的增长,扫描速度也会变慢。
创建json 索引的要求:
1.具有一致、已知键的结构化 Schema
2.特定 JSON 路径上的等价和范围查询
3.需要精确控制索引键的情况
4.对目标查询进行高效存储加速
七. 混合查询
1.两个ANN查询(密集+稀疏BM25)
2.得到结果后进行Rerankers 重排 ,然后得出topK
八. 重排分类
1. 加权排名
对多个结果进行加权后得到最终结果,取topK
2. RRF 排序
RRF Score=1/ (k+rank)
rank 是某个结果在某一路搜索中的排名(第几名)
k 是一个常数,通常设为 60(防止排名=1时分数爆炸)
然后把所有搜索路径的 RRF 分数加起来,得到最终得分。
举例:
密集向量查询结果排名:2 → RRF 分数 = 1/(60+2) = 1/62 ≈ 0.0161
稀疏BM25查询结果排名:1 → RRF 分数 = 1/(60+1) = 1/61 ≈ 0.0164
总分 = 0.0161 + 0.0164 = 0.0325
3. Boost 关键词加权(单次搜索用)
在搜索结果候选项中查找匹配项,并通过指定权重来提升这些 匹配项的得分。
举例:搜索水果,结果为 苹果,香蕉,哈密瓜 等。我想对 提高香蕉的得分,
我就用这个Boost 排序,所有等于香蕉的会乘以权重
4. 衰减排名
在传统的向量搜索中,搜索结果的排名纯粹取决于向量的相似性–向量在数学空间中的匹配程度
考虑一下这些日常场景:
在新闻搜索中,昨天的文章应该比三年前的类似文章排名靠前
搜索餐厅时,优先考虑 5 分钟车程内的餐厅,而不是需要 30 分钟车程的餐厅
这些场景都有一个共同的需求:平衡向量相似性与时间、距离或流行度等其他数字因素。
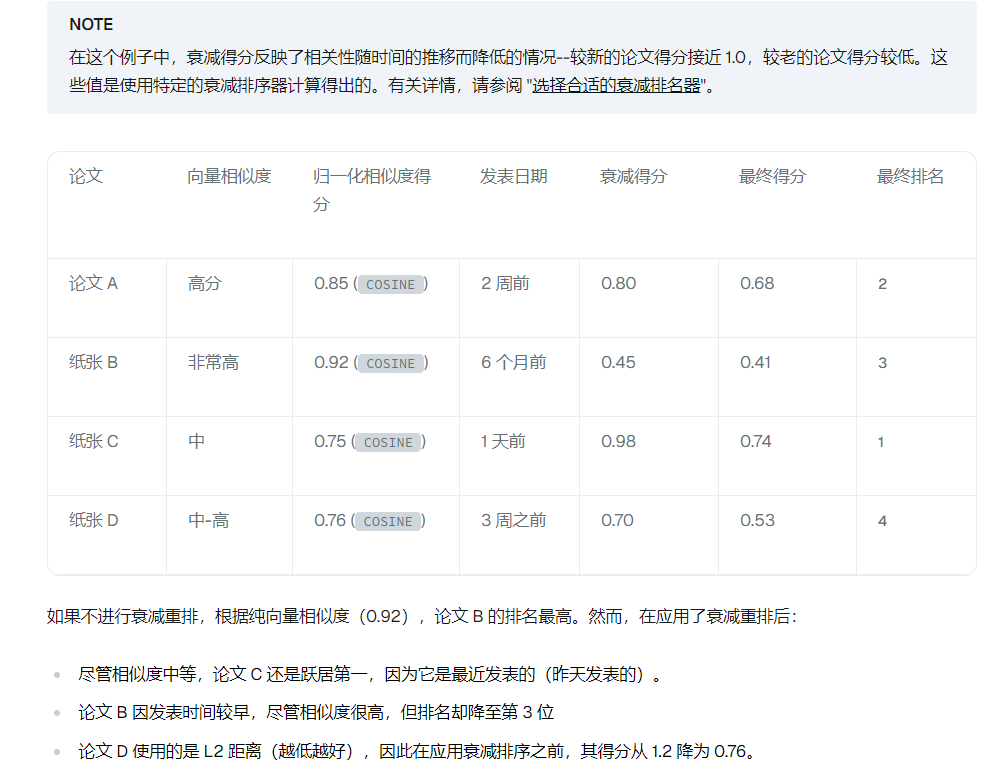
衰减排名器:
高斯:
是一种根据距离或时间等因素,对评分进行非线性衰减的加权方法,
常用于搜索排序、推荐系统和向量检索中,用来表达“越接近越好”的优先级思想
举例:用户搜“附近的咖啡馆” ,你有向量相似度(语义匹配),也有地理距离。
你想让“离用户近”的咖啡馆优先展示,哪怕它的语义匹配稍低。对“距离”做高斯衰减
指数:
1.用户希望最近或附近的项目在搜索结果中占主导地位
2.较旧或较远的项目如果特别相关,仍应可被发现
3.相关性下降应该是前负荷的(开始时较陡峭,之后较缓慢)
比如:超过 24 小时的新闻文章相关性持续下降,但从未达到零。
即使是几天前的新闻也能保持最低的相关性,使重要但较旧的新闻仍能出现在结果 中(尽管排名较低)
线性:
线性衰减能独特地创建一个确定的终点,因此对于有自然边界或截止日期的应用特别有效。
比如确切时间的优惠活动,送货半径,限制年龄的内容
九. Rag 查询优化
- 创建假设问题
每个文档块中的内容提出的多个问题
-
创建关键词等元数据信息
过滤关键词等元数据来加快搜索,提高准确性 -
复杂问题使用llm分解为子问题
-
复杂问题进行改写查询
原始用户查询:"我有一个包含 100 亿条记录的数据集,想把它存储到 Milvus 中进行查询。可以吗?
回退问题:“Milvus 可以处理的数据集大小限制是多少?” -
增加索引
-
合并文档块
合并策略:如果前k 个子块中有特定数量(n)的子块属于同一个父块,系统会判定这个父块所代表的,更完整的上下文可能对回答问题至关重要,于是用这个父块的完整内容,替代被召回的子块 -
分层索引
以建立两级索引:一级是文档摘要索引,另一级是文档块索引。向量搜索过程包括两个阶段:首先,我们根据摘要过滤相关文档,随后,我们在这些相关文档中专门检索相应的文档块。 -
利用Rerank重排
-
调整提示中的块顺序
LLMs 在推理过程中经常会忽略给定文档中间的信息。相反,他们往往更依赖于文档开头和结尾的信息。
在检索多个知识块时,将置信度相对较低的知识块放在中间,而将置信度相对较高的知识块放在两端。 -
使用LangGraph Agents 的自我反思
一些最初检索到的 Top-K 文档块是模棱两可的,可能无法直接回答用户的问题。
在这种情况下,我们可以进行第二轮反思,以验证这些文档块是否能真正解决查询问题 -
搜集用户常用的问题分析,创建规则或者对应的信息快
-
生成伪答案去查询
不直接使用用户简短的查询去匹配冗长的问答,先使用LLM生成一个“理想的答案”,然后用这个内容更加丰富的伪答案向量化后去进行真实的检索。因为两种在形式,长度和语义丰富度上更加的对等,从而显著的提高在零样本场景下的检索精度 -
多路召回混合检索
稀疏和密集向量一起检索

















 1444
1444

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









