







转载请注明出处:https://blog.csdn.net/Gamer_gyt/article/details/95014206
博主微博:http://weibo.com/234654758
Github:https://github.com/thinkgamer
公众号:搜索与推荐Wiki
序列推荐模型 TransFM(Translation-based Factorization Machines for Sequential Recommendation)参考:点击阅读
背景
这篇论文是由 Ruining He,Wang-Cheng Kang和Julian McAuley三位大佬提出的,在2017年的ACM推荐系统会议(RecSys’17)上获得了最佳论文奖(在大佬主页可以下载该论文中涉及的代码和数据集,可惜代码是C++写的,不懂C++的童鞋挑战性很大~)
- 第一作者的Ruining He主页为https://sites.google.com/view/ruining-he/
- RecSys历届最佳论文地址:https://recsys.acm.org/best-papers/
- 本论文下载地址:https://arxiv.org/pdf/1707.02410.pdf
论文的两个研究点:
- 用户的序列推荐(用户在浏览了一些items之后给他推荐物品j)
- 物品到物品的推荐(用户购买了一个牛仔裤,给他推荐一个衬衫)
概述
对用户和物品以及物品和物品之间的关系进行建模是设计一个成功推荐系统的核心。一种经典的做法是预测用户行为序列(或者是下一个物品的推荐),其挑战在于对用户,用户历史行为物品和用户接下来有行为的物品之间的三阶交互关系进行建模。现有的方法是对这些高阶的交互分解为成对的关系组合,通过不同的模型去对用户的偏好(用户和物品的交互)和序列匹配(物品和物品的交互)进行建模。
比如MF(Matrix Factorization,矩阵分解)只对用户和物品之间的交互行为进行建模;MC(Markov Chain,马尔可夫链)只对用交互过程中的物品对进行建模,通常通过对转移矩阵进行分解提高其泛化能力。
对于序列推荐,研究者提出了可扩展的张量分解方法,比如FPMC(Factorized Personalized Markov Chains),FPMC通过两个成对的交互关系来模拟u,i,j之间的三阶交互关系,其实这就是MF和MC的结合。对于提升FPMC有两个方向的研究思路,一个思路是在个性化度量嵌入方法用欧几里德距离替换FPMC中的内积,其中度量假设尤其是三角不等式使模型的泛化性更好,然而,这些研究工作采用的仍然是对用户偏好和序列的连续性分别建模的框架,由于这两部分本身存在关系,因此这样做是存在一定的问题的。另一个思路是利用平均/最大池化等操作去聚合用户u和前一项i的向量表示,然后再测量它们与下一个项j的相似度,这种思路虽然部分解决了两个组件之间的相互依赖问题,但很难解释而且不能从度量embedding向量中获得收益。
为了解决上述存在的问题,提出了Translation-based Recommendation模型,具体解释往下看。
模型介绍
问题定义
涉及的相关字符含义如下图所示:

模型结构
TransRec的主要思路如下图:
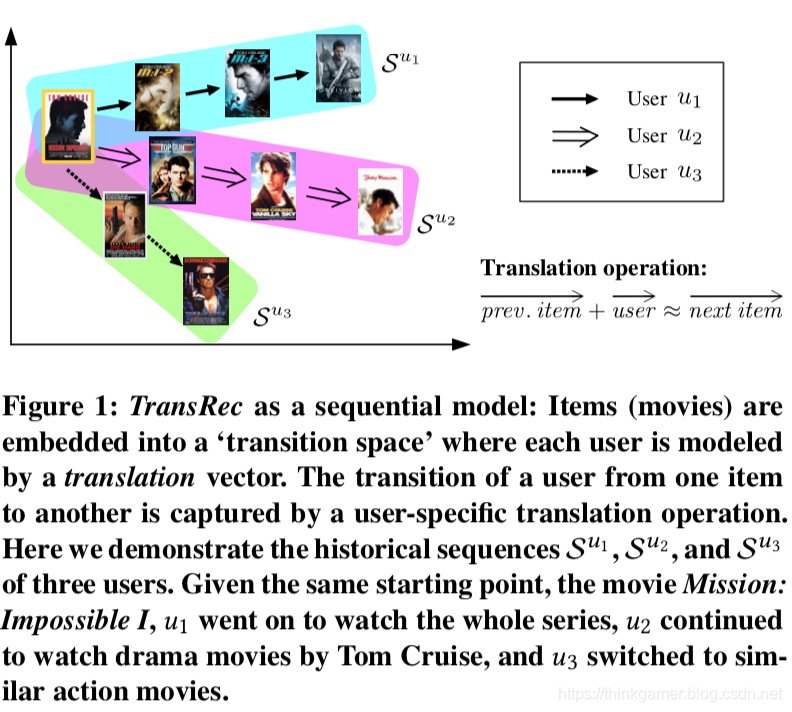
物品作为一个点被嵌入到翻译空间内,用户的序列行为则作为一个翻译向量存在于该空间,然后,通过个性化翻译操作捕获前面提到的三阶交互,其基本思路就是用户的翻译向量和上一个行为物品的翻译向量之和,确定下一个有行为的物品j,如下所示
→
γ
i
+
→
t
u
≈
→
γ
j
\underset{ \gamma _i }{\rightarrow} + \underset{t_u}{\rightarrow} \approx \underset{ \gamma _j }{\rightarrow}
γi→+tu→≈γj→
其中距离的计算可以采用L1-distance或者L2-distance。
由于生产环境中数据的稀疏性,很难为每个用户学习到一个向量,因此添加了一个全局翻译向量来初始化所有的用户,这样也能够有效的缓解用户冷启动。如下所示
→
T
u
=
→
t
+
→
t
u
\underset{ T_u }{\rightarrow} = \underset{t}{\rightarrow} + \underset{ t_u }{\rightarrow}
Tu→=t→+tu→
在一个生产系统中,往往会存在头部物品(即热门物品),这些物品的流行度很高,那么如果仅仅采用简单的距离计算的话,那些头部物品就很可能出现在每个用户的推荐结果中。因此在计算时增加了一个偏置项beta_j来对热门物品进行降权。最终对于给定的用户u和之前的行为物品i可以由以下的计算公式为其推荐物品j。
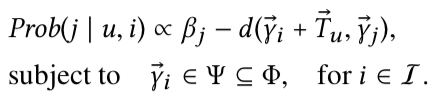
这里有一点需要注意的是:为了避免“维度诅咒”问题,将r_j限定在整个翻译空间的一个子集上,例如一个单位球体的空间范围。
对于给定过的用户和历史行为序列,模型的目标是对集合中的物品进行排序,这里采用的是pairwise方法的S-BPR(Sequential Bayesian Personalized Ranking)。其优化的公式如下:
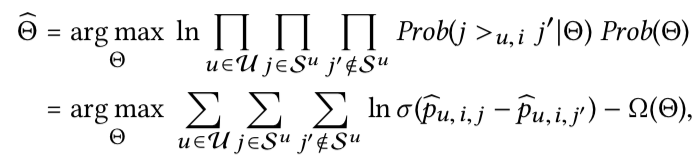
参数学习
物品i和用户对应的全局翻译向量随机初始化为单元向量,每个物品的偏置向量和每个用户的翻译向量初始化为0。
目标函数通过随机梯度上升进行优化,随机从集合中抽取用户u,正例j和负例j’,通过下面的计算公式进行迭代:
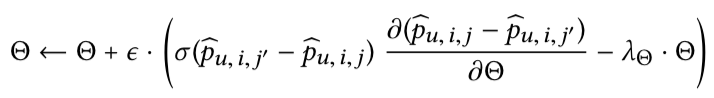
最近邻查找
在测试时,可以通过最近邻搜索进行推荐,一个小的挑战就是物品的偏差。这里分为两部分去解决这个问题。
第一使用:
β
j
′
←
β
j
−
m
a
x
k
∈
I
β
k
\beta _j ' \leftarrow \beta _j - max_{k\in I}\beta _k
βj′←βj−maxk∈Iβk 表示
β
j
\beta _j
βj
对偏置项进行转换,不会改变计算结果的排序。
第二使用L2范数计算
γ
j
→
′
=
(
γ
j
→
′
;
−
β
j
′
)
\overrightarrow{\gamma _j}' = (\overrightarrow{\gamma _j}';\sqrt{-\beta _j'})
γj′=(γj′;−βj′)
或者使用L1范数计算
γ
j
→
′
=
(
γ
j
→
′
;
−
β
j
′
)
\overrightarrow{\gamma _j}' = (\overrightarrow{\gamma _j}';-\beta _j')
γj′=(γj′;−βj′)
实验证明L2范数效果更好。对于给定的用户u和物品i,在整个向量空间内为其计算寻找最近的
γ
j
→
′
\overrightarrow{\gamma _j}'
γj′
实验
为了充分验证TransRec的优势,使用了大量的公开数据集,如下图所示:
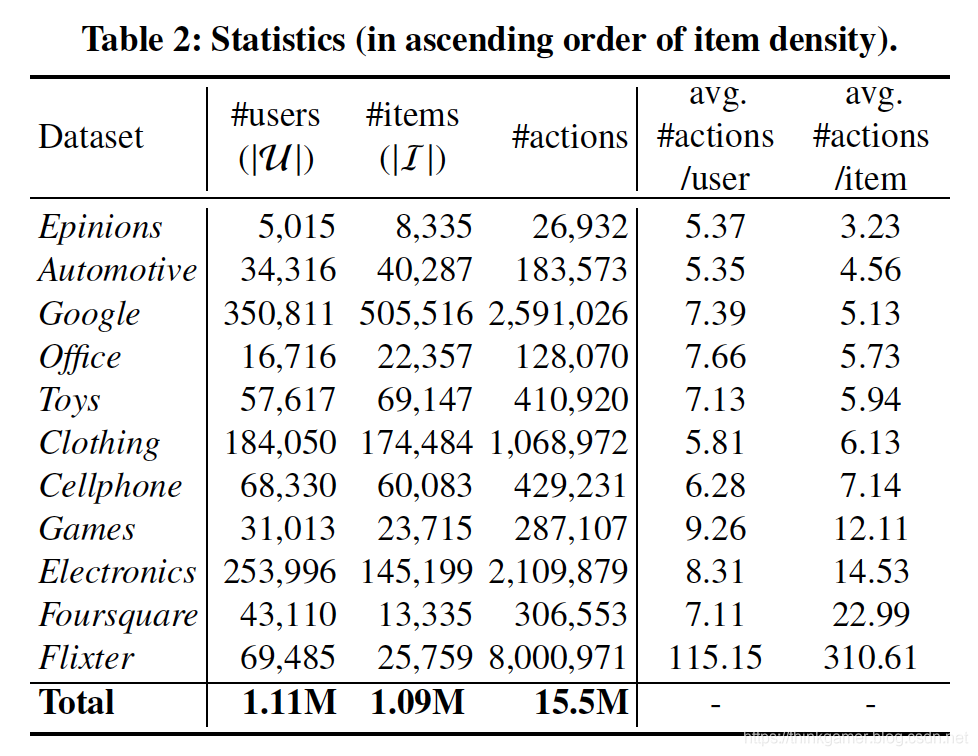
在算法选择上以PopRec为baseline,BPR-MF,FMC,FPMC,PRME,HRM作为对比算法模型,在上表中的数据集上对比实验如下:
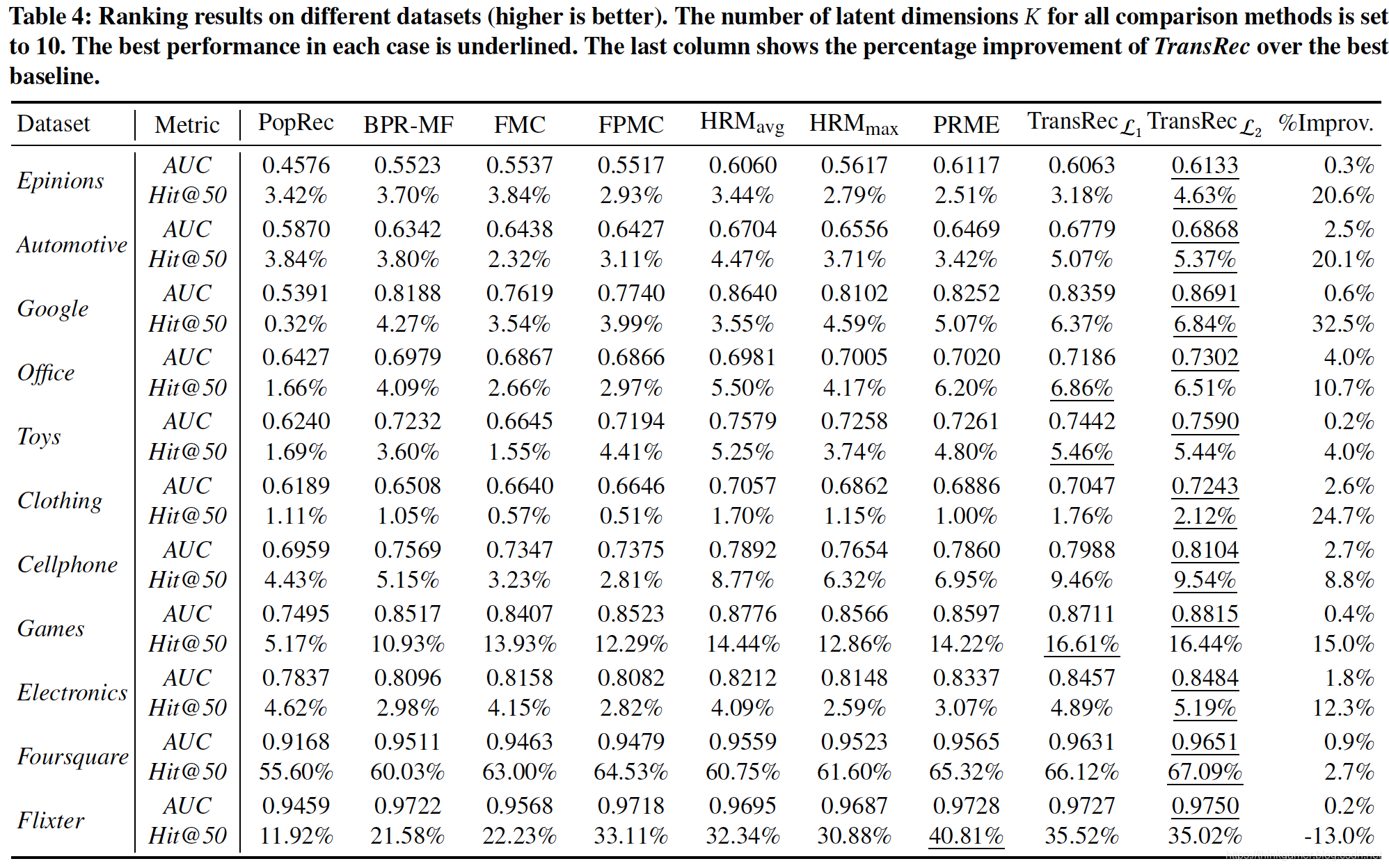
在进行实验寻找最佳参数时,使用的是网格搜索法,使用随机提督上升优化模型的学习率为0.05,正则项参数的测试范围是:{0, 0.001, 0.01, 0.1, 1}。在TransRec中尝试了L2-ball 和 L2-sphere计算距离,L2-ball的效果更好一些。
在最开始我们提到本论文主要有两点
用户的序列推荐(用户在浏览了一些items之后给他推荐物品j)
物品到物品的推荐(用户购买了一个牛仔裤,给他推荐一个衬衫)
在TransRec中,通过删除个性化向量部分,TransRec可以直接进行物品到物品的推荐,这和知识图谱中的推荐有点相似,因为需要对不同项之间的关系进行建模。其中实现的结果类似于下图这样。

同样也对该部分进行了单独的实验,采用的数据集,对比的算法和实验的结论如下:
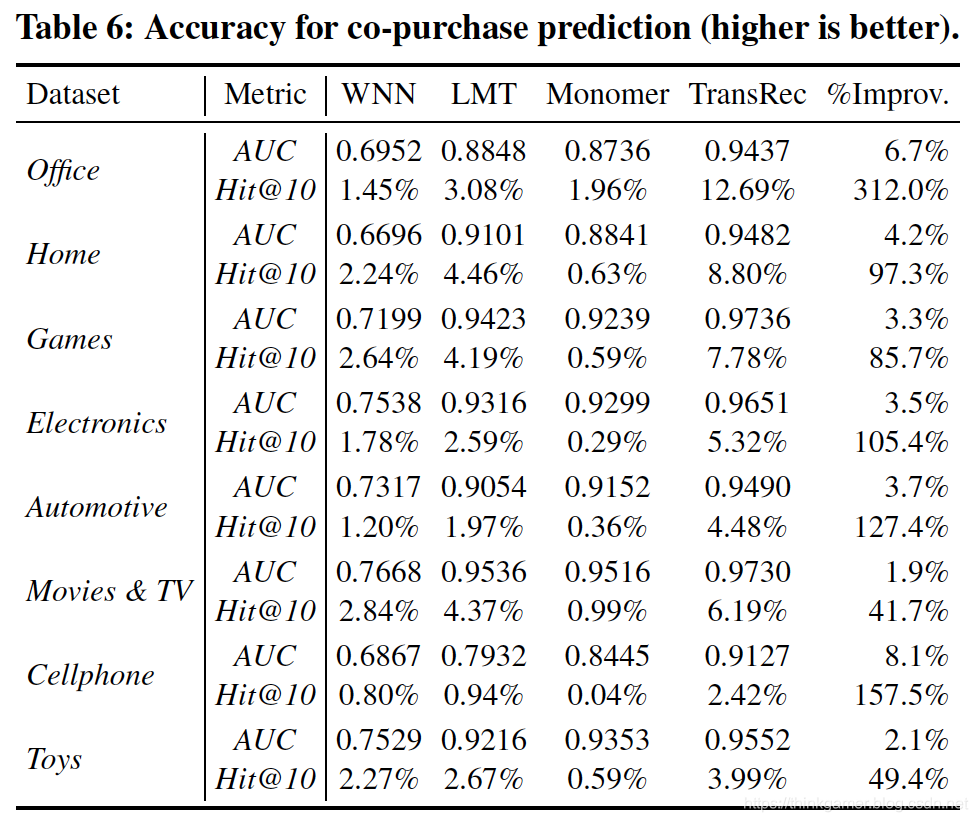
我的总结
- 文章中介绍了TransRec的优势
(1)只用一个模型来模拟用户,物品之间的三阶交互
(2)可以从隐式假设度量中获益
(3)轻易的解决数据量大的问题 - 论文中不仅提出了使用一个模型来对用户物品之间的三阶关系进行建模,还借鉴知识图谱中的思想提出了物品道物品之间的推荐。
- 文中实验时将数据集拆分成了三部分,训练集,验证集,和测试集。其比例为8:1:1。
- 数据集拆分时避免了从整体数据集中的随机拆分,而是按照时间先后的顺序进行拆分。保证了一定的时间连续性,这一点值得借鉴。
- 在寻找最佳参数时使用的是网格搜索法。
- 用户的翻译向量采用了全局翻译向量和个性化的翻译向量之和。一定程度上解决了用户的冷启动。
- 样本偏置项,减小物品本身热度对模型的影响。
- 为了避免“维度诅咒”问题,将样本限定在整体样本空间的一个子集上。
- 基于TransRec的思路,作者又提出了和FM的结合,其论文是Translation-based Factorization Machines for Sequential Recommendation,接下来会对其进行介绍。
















 215
215











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









