





对于一个二分类模型,衡量模型效果的标准指标之一,是log-loss或binary cross entory(后面统一称之为交叉墒【cross entropy】)。给定一个二分类预测任务,模型不直接输出0/1,而是输出一个概率值 y ^ \widehat y y ,模型的交叉墒为:
∑ i − y i l o g y ^ i − ( 1 − y i ) l o g ( 1 − y ^ i ) \sum_{i}-y_ilog\widehat y_i - (1-y_i)log(1-\widehat y_i) i∑−yilogy i−(1−yi)log(1−y i)
其中i表示在训练集的所有样本。
我们将在下一节介绍交叉墒的来历。现在考虑这样一个问题,假设测试集和训练集的正负样本比例不一样。这并非凭空臆想的问题,而是最近新加问题Quora question pair challenge的参与者所面对的实际问题。本文目的是解释为什么这种比例不一致性会对交叉墒造成问题(something I, and other posters pointed out),以及交叉墒如何解决此类问题。当正样本的比例随时间变化时,此问题也会出现。有些文章试图将训练集的预测转化为测试集的预测,但据我了解目前没有这方面的严格的分析。
交叉墒与分类不均衡问题
交叉墒源于信息论。可以把它理解为为了从predicted set推导出label set,需要多少额外的信息,这是维基百科上的解释【注:本人也不是太理解这个解释,predicted set和label set分别表示什么意思】。在我看来,一种更直观的理解方式是,模型对标签取值概率的"诚实度"奖励,越"诚实"交叉墒越低。比如我们的模型相信标签为正的概率为 p p p,模型的输出值为 0 ≤ q ≤ 1 0\le q\le 1 0≤q≤1, 那么 q q q取多少才能最小化交叉墒损失值呢?我们来推导一下,首先交叉墒的定义如下:
l o s s ( q ) = − p l o g ( q ) − ( 1 − p ) l o g ( 1 − q ) loss(q)=-plog(q)-(1-p)log(1-q) loss(q)=−plog(q)−(1−p)log(1−q)
求它的极值,对 q q q求导,再设置导数为零,得到:
1 − p 1 − q = p q \frac{1-p}{1-q} = \frac{p}{q} 1−q1−p=qp
化简得到 q = p q=p q=p,也就是说,模型输出真实的概率 p p p,此时交叉墒最小。
现在我们来考虑训练集与测试集,正负样本比例不一致为什么会造成问题。我们首先考虑这样一个最傻模型,这个傻模型对所有的样本的预测值都相同,也就是忽略输入特征,输出一个常数。通过上文的讨论,我们知道在训练集上,最小化交叉墒的模型输出值为 P ( y ) P(y) P(y),也就是随机选择一个样本标签为正的概率。我们希望这个输出值在测试集上也能最小化交叉墒,但是只有测试集与训练集的正样本概率一样,才能在测试集上最小化交叉墒值。所以这种不一致性,导致模型在测试样本墒并没有达到交叉墒最优化的要求,所以测试集墒交叉墒损失会高于训练集墒的交叉墒损失值。
此外,较复杂的模型,在对预测值不太确定的情况下【注:也就是对于预测值在0.5附近的样本】,也会倾向于受此效应的影响。比如当训练/测试集的正负样本比例不同,并且模型没有从训练集里吸收任何有效信息的,模型如果这么做【注:输出训练集上的概率值】,它将会收到惩罚【注:测试集上的交叉墒会比较大】。
需要注意的是,有些指标对样本不均衡问题敏感度比较低,比如area under the curve(AUV)
基于贝叶斯理论的预测值变换
假设我们的训练集采样自分布 ( X , y ) (X, y) (X,y),测试集采样自分布 ( X ′ , y ′ ) (X',y') (X′,y′)。我们假设,两个分布的唯一差别是正负比例不一样,正样本的分布和负样本的分布是一致的【注:过采样和降采样,不会改变正或负样本自身的分布,因为采样一般采用随机采样】,也就是:
X
∣
(
y
=
0
)
∼
X
′
∣
(
y
′
=
0
)
X|(y=0) \sim X'|(y'=0)
X∣(y=0)∼X′∣(y′=0)
X
∣
(
y
=
1
)
∼
X
′
∣
(
y
′
=
1
)
X|(y=1) \sim X'|(y'=1)
X∣(y=1)∼X′∣(y′=1)
假设我们有样本 x ∈ X x\in X x∈X,我们的模型试图预测样本为正的概率 P ( y ∣ x ) P(y|x) P(y∣x),其中 y y y表示标签为正, ¬ y \neg y ¬y表示负。假设我们模型最优预测值为 p p p。由贝叶斯理论,得到:
p
≈
P
(
y
∣
x
)
=
P
(
x
∣
y
)
P
(
y
)
P
(
x
)
p\approx P(y|x)=\frac{P(x|y)P(y)}{P(x)}
p≈P(y∣x)=P(x)P(x∣y)P(y)
=
P
(
x
∣
y
)
P
(
y
)
P
(
x
∣
y
)
P
(
y
)
+
P
(
x
∣
¬
y
)
P
(
¬
y
)
=\frac{P(x|y)P(y)}{P(x|y)P(y)+P(x|\neg y)P(\neg y)}
=P(x∣y)P(y)+P(x∣¬y)P(¬y)P(x∣y)P(y)
=
u
u
+
v
=\frac{u}{u+v}
=u+vu
现在假设,同样的样本x采样自 X ′ X' X′,我们模型需要预测样本为正的概率 P ( y ′ ∣ x ) P(y'|x) P(y′∣x)。假设 X ′ X' X′与 X X X的差别在于,正样本采用率为 α \alpha α, 负样本采样率为 β \beta β,则得到:
P
(
y
′
)
=
α
P
(
y
)
P(y')=\alpha P(y)
P(y′)=αP(y)
P
(
¬
y
′
)
=
β
P
(
¬
y
)
P(\neg y') = \beta P(\neg y)
P(¬y′)=βP(¬y)
并且按照前文的假设,两个分布是唯一差别是正负样本比例,而正或负样本的分布是一致的,又得到:
P
(
x
∣
y
)
=
P
(
x
∣
y
′
)
P(x|y)=P(x|y')
P(x∣y)=P(x∣y′)
P
(
x
∣
¬
y
)
=
P
(
x
∣
¬
y
′
)
P(x|\neg y)=P(x|\neg y')
P(x∣¬y)=P(x∣¬y′)
我们来看一下在X’上样本x最优预测值:
P ( y ′ ∣ x ) = P ( x ∣ y ′ ) P ( y ′ ) P ( x ∣ y ′ ) P ( y ′ ) + P ( x ∣ ¬ y ′ ) P ( ¬ y ′ ) P(y'|x)=\frac{P(x|y')P(y')}{P(x|y')P(y')+P(x|\neg y')P(\neg y')} P(y′∣x)=P(x∣y′)P(y′)+P(x∣¬y′)P(¬y′)P(x∣y′)P(y′)
= α u α u + β v =\frac{\alpha u}{\alpha u + \beta v} =αu+βvαu
由 p ≈ u u + v p\approx\frac{u}{u+v} p≈u+vu,可以得出 v ≈ u ( 1 − p ) / p v\approx u(1-p)/p v≈u(1−p)/p,于是得到:
P
(
y
′
∣
x
)
≈
α
u
α
u
+
β
v
P(y'|x)\approx \frac{\alpha u}{\alpha u + \beta v}
P(y′∣x)≈αu+βvαu
=
α
u
α
u
+
β
u
(
1
−
p
)
/
p
=\frac{\alpha u}{\alpha u+\beta u(1-p)/p}
=αu+βu(1−p)/pαu
=
α
p
α
+
β
(
1
−
p
)
=\frac{\alpha p}{\alpha + \beta (1-p)}
=α+β(1−p)αp
因此,从训练集X到测试集X’的概率映射函数为:
f ( x ) = α x α x + β ( 1 − x ) f(x)=\frac{\alpha x}{\alpha x + \beta (1-x)} f(x)=αx+β(1−x)αx
可以由此推导出x的不确定性是如何影响f(x)的不确定性,但本文就不推导了。
需要注意的是,通过对q最优化以下损失函数:
α p l o g ( q ) + β ( 1 − p ) l o g ( 1 − q ) \alpha p log(q)+\beta(1-p)log(1-q) αplog(q)+β(1−p)log(1−q)
也可以推导出此概率映射函数。我们可以在X上最优化以下交叉墒:
α y l o g ( y ^ ) + β ( 1 − y ) l o g ( 1 − y ^ ) \alpha ylog(\widehat y) + \beta(1-y)log(1-\widehat y) αylog(y )+β(1−y)log(1−y )
达到优化X’上的交叉墒的目的,这个方法也可以推导出函数f。
举个例子,假设训练集的正样本率为37%,测试集的负样本率为16.5%。我们设置正样本采样率
α
=
16.5
/
37
\alpha=16.5/37
α=16.5/37, 负样本采样率
β
=
83.5
/
63
\beta=83.5/63
β=83.5/63,则f函数图像为:
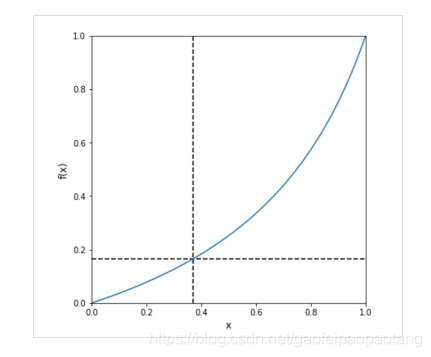
图中已经标出 f ( 0.37 ) = 0.165 f(0.37)=0.165 f(0.37)=0.165,并且当x靠近0或1是,f(x)也是【注:也就说,当模型十分确认样本的正负的时候,预测值的修正力度不会很大,当模型不太确认样本的正负的时候,预测值的修正粒度会比较大】。
综上所述,X和X’的正负比例一致非常重要。














 457
457











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









