






VGG16作为很入门的CNN网络,同时也有很多基于VGG16的改进网络,比如用于语义分割的Segnet等。
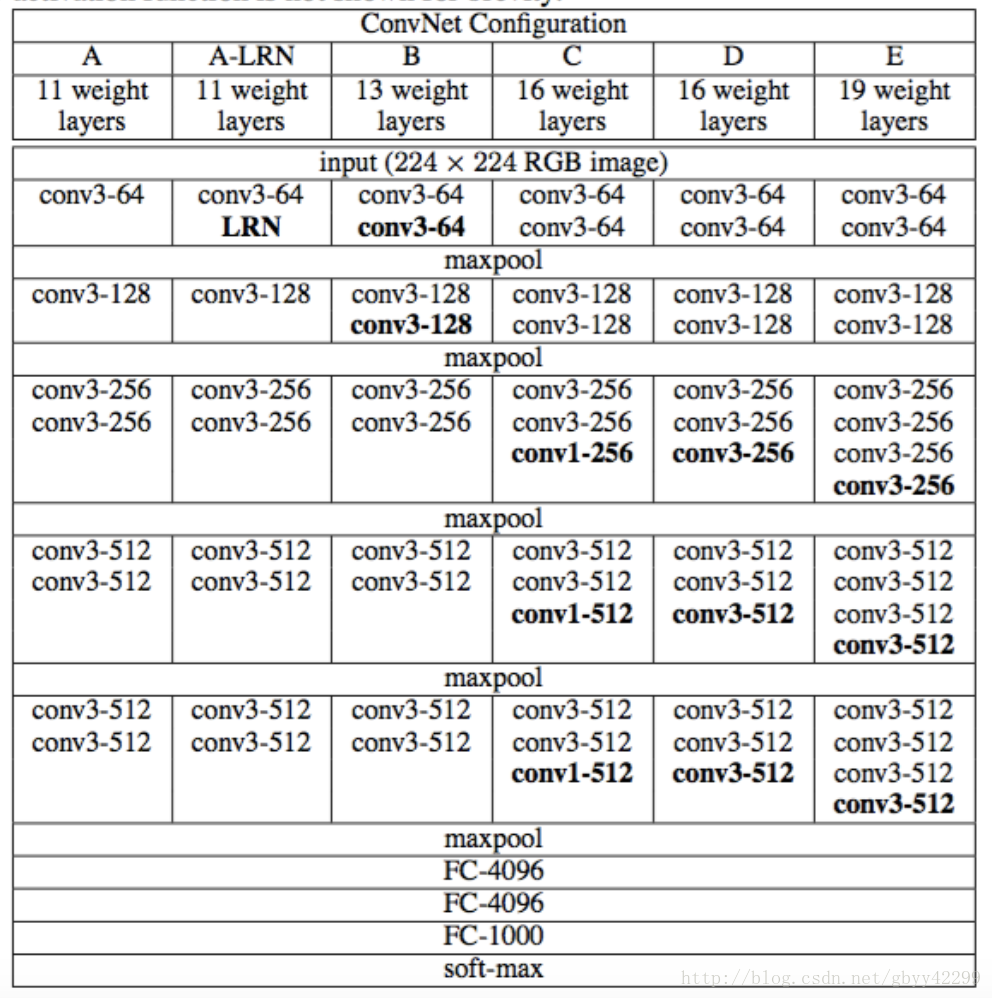
VGG16输入224*224*3的图片,经过的卷积核大小为3x3x3,stride=1,padding=1,pooling为采用2x2的max pooling方式:
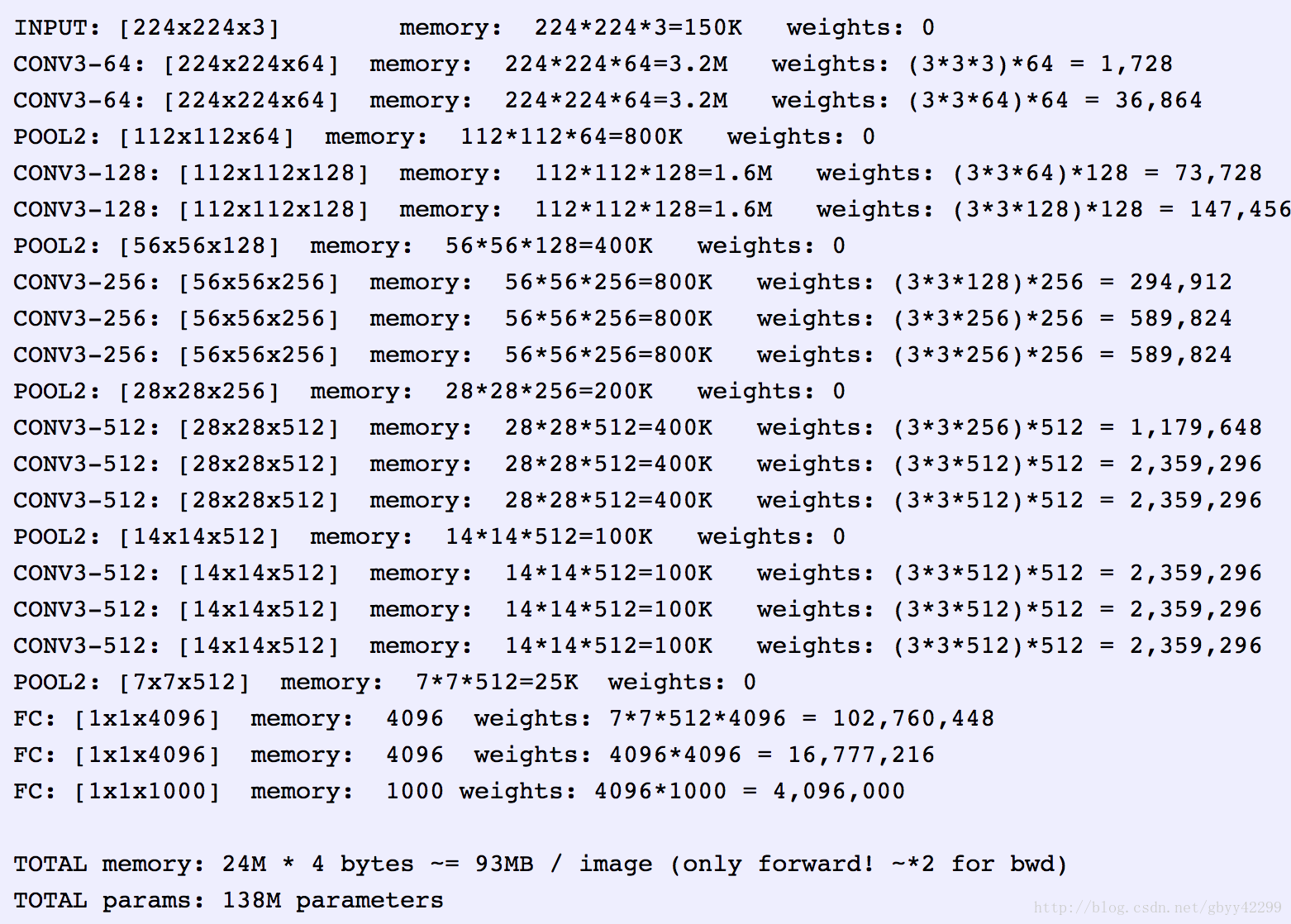
1、输入224x224x3的图片,经过64个卷积核的两次卷积后,采用一次pooling。经过第一次卷积后,c1有(3x3x3)个可训练参数
2、之后又经过两次128的卷积核卷积之后,采用一次pooling
3、再经过三次256的卷积核的卷积之后,采用pooling
4、重复两次三个512的卷积核卷积之后再pooling。
5、三次Fc














 1445
1445











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









