









一、从压缩说起
提起压缩这个概念,脑海中不禁会跳出这样一个情形:在不改变物体容量的前提下,减少物体的体积,使空间得以更有效的利用。在你外出旅行时,会将许多衣服放入行李 箱,你可以压一压衣服,让它们小到能被行李箱容纳,你压缩了衣服。之后,你打开行李箱,穿上衣服时,这就是所谓的解压。颇感欣慰的是,信息也能以同样的方式压缩,计算机文件和传输在互联网的信息都可以被压缩,以方便存储和传输,然后解压并以原始方式利用。我们日常听到的MP3格式文件常见的视频文件甚至是打电话时都用到了压缩,现下流行的zip压缩文件格式运用了精巧的压缩算法,计算机使用两种不同的压缩:无损压缩和有损压缩。接下来简要谈谈zip文件是怎么压缩和解压缩的。
二、无损压缩
无损压缩顾名思义就是压缩不改变原始文件的体积,在解压后的文件和原始文件一模一样,计算机使用某种高效的算法吧文件压缩的更小,而不改变文件的本来面貌,究竟它是怎么办到的?我们先一起看一串文本数据:
AAAAAAAAABBBBBBBBBOKOKOKOKOKOKOKYESYESYESYES
如果让你来口述这些文本,你怎么描述呢?如果乍一看还不明显,思考一下你会如何通过电话向某人口述这份数据。和说"A A A A....."YESYES YES"不同的是,我肯定你会说9个A 9个B 7个OK 4个YES,在这个例子中,你将这个包含44个字符的串变成了说出9A9B7OK4YES 这11个字符压缩了25% 看起来压缩率还可以但不是绝对的称赞,但44个字符毕竟在实际应用中相比是非常小的甚至忽略不计,在一般的实际应用中压缩率可以高达50%以上! 非常不错,是不是计算机上的压缩文件都是用这种算法的呢?此言差矣! 也许读者会觉得如此轻松简单掌握这样的压缩算法未免太没有挑战性了,是的,简单的东西暴露出很多的缺陷。话说回来,这种办法在计算机科学中称之为前程长度编码(run-length encoding),因为它将重复的“行程”和行程“长度”编码在了一起。所不幸的是,它的价值只在压缩非常特殊的数据上管用,读者已经发现了,上面这个例子就是这么一个特殊的:数据中的重复片段必须相邻,譬如:ABACABAD就不能那这个办法使用了,还有一点,就是这个算法大部分和其他压缩算法结合起来使用。如何另一种也就是本博客的主题赫夫曼编码(Huffman Coding)结合起来使用,于是计算机科学家发明了一系列更成熟的算法:同前压缩(same-as-earlier trick)和更短符号压缩(shorter-symbol trick)。只需要这两个算法就能生成ZIP文件,由于篇幅所限,这里就介绍同前压缩了。
-
同前压缩
加入一下有一串你要处理的可怕任务,通过电话向某人口述如下数据:
VJGDNQMYLH-KW-VJGDNQMYLH-ADXSGF-OVJGDNQMYLH-ADXSGF-VJGDNQMYLH-EW-ADXSGF
总共有63个字母需要口述,“-”表示的是分隔符使更容易区分,假如你要逐个字符的往下念,你能保证不会说错或者说漏么?如果换了一个更长的字符串呢?
前10个字母我们没办法只能照着念:A、J、G、D、……H,然后K、W,接下来,发现到然后10个字母和一开始的10个字母一样,你可能会说:接下来10个字母和开始的10个字母重复,然后A、D、X、S、G、F、O 仔细观察O后面的16个字符又和开始的10个字母一样,于是我们想办法得到一个更简短的描述:往回数17个字母,抄到第16个字母,我们再换一种更加精炼的表达:back17 copy 16(b17c16)然后发现接下俩的10个字母也是重复的部分,因此 b16c10,再接下来两个字母没有重复,需要逐个口述为E、W最后的6个字母是之前的重复,可以b18c6
让我们总结一下这个压缩算法,我们用b代替back c代替copy原本的字符串被说成这样VJGDNQMYLH-KW-b12c10-ADXSGF-O-b17c16-b16c10-EW-b18c6
这个字符串只包含44个字母,节省了将近1/3。
还有许多压缩数据的算法,可参考《 Introduction to Data Compression》Khalid Sayood 数据压缩导论.
三、赫夫曼编码
好了,该进入正题了,赫夫曼编码(Huffman coding) 从应用来说是一种数据压缩算法,从算法理论角度来说是一种贪心算法。所谓贪心算法就是分阶段的工作,在每一个阶段,可以认为所选择的决定是最优的,这种从当下得到最优的就决定而不考虑将来的后果的策略就是这种算法的来源。当算法结束时我们希望局部最优就是全局最优,如果是这样的话,那么算法就是正确的,否则就是一个次最优解。
一、编码
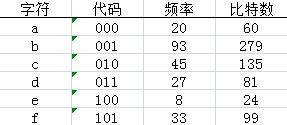
假如有一个文件,文件中包括了以上图所示的字符和出现的频率,当然每个字符需要编码姑且已上图为准吧,可以看到每个字符的编码为3位的定长编码,大小为678个比特位,在这里只表现了一般情况下的文件存储方式将每个数据编码为二进制的表示,根据每个数据出现的频率计算出总的二进制比特位长,这种方式有一个特点,即每个字符的编码都是随机给的比如a:000 ,b:001 从上到下依次有规律的递增,但这体现不出压缩的概念。
1、前缀编码
在电报传输中,电文的传送是被压缩成二进制串的,且尽可能的短,比如 a:0 ,b:01, c:11, d:001, e:010.假入要传送eaacdb一串数据,对应的二进制串为:010001100101 ,于是对方在接受时完全可能将开头的01译成b,接下来三个零译成a,然后两个一译成c然后为db于是整个译码就变成了baaacdb,与传送放发送的本意完全不对,信息接受错误。在这个例子中,最突出的问题是二进制码的前缀可能是别的字符二进制码的前缀,这样在译码的过程中完全可能出现混淆。为了避免这种混淆,出现了一种叫做前缀编码(prefix code)的技术,既没有任何二进制码是其他码字的前缀,前缀码的作用是简化解码的过程,由于没有码字是其他任何码字的前缀,编码文件的开始码字是无歧义的。我们可以简单的识别出开始码字,将其转换回原字符,然后对剩下的重复这种解码过程。但怎么构造这种前缀码?
一种二叉树可以解决问题。
在上面的电文传输例子中,我们让freq表示每个字符出现的频率,假定a.frea=20,b.freq=15,c.freq=40,d.freq=90,e.freq=55,于是我们可构造如下图所示的二叉树:
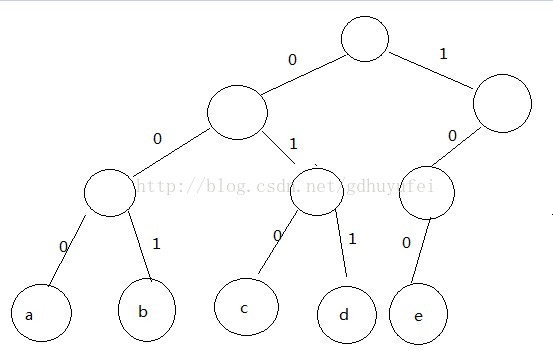
我们把字符放在叶子节点上,一个字符的码字可以从根节点到字符节点开始的简单路径表示,其中0表示向左,1表示向右。
那么a:000,b:001,c:010,d:011,e:100可以证明每个字符的码字不是其他任何码字的前缀,实际上这也是开头对应的哪一张表用相同的方法组成的前缀码。所以来说,可构造这种将所有的字符节点放在叶子节点上,左分支为0,右分支为1的二叉树就是唯一的可表示成字符的前缀编码树。
解决了前缀码的问题但是这种编码还不是最优的,因为发现所有的字符编码为定长编码,达不到压缩的概念。为此我们定义树的代价:
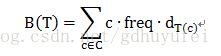
其中,T表示一颗前缀码的树T,对于字母表C中每个字符c,令属性c.freq表示c在文件出现的频率,dT表示c在叶节点中的深度,则B(T)为编码文件需要的二进制位,
也称为B(T)为数的代价。
2、构造赫夫曼编码
赫夫曼设计了一个贪新算法来构造最优前缀编码,称为赫夫曼编码(Huffman code),赫夫曼算法的过程可描述如下:
(1)、根据给定的n个频率值集合{f1,f2,f3,4,……,fn} 构成二叉树集合T={T1,T2,T3,T4,……,Tn};每颗二叉树都为根节点且左右子树为空
(2)、在T中选择两颗根节点频率值最小的树作为左右子树构造一颗新的二叉树,且新置的二叉树的根节点的频率值为左右孩子频率值之和
(3)、在T中删除这两颗树,同时将新得到的二叉树插入到T中。
(4)、重复步骤(2)和(3),直到T中只含一颗树为止。这棵树便是赫夫曼树。
以开头的文件的编码制作成的表作为例子,频率集合{a:20,b:93,c:45,d:27,e:8,f:33}按上面的步骤构造赫夫曼树的一个解如下图所示:
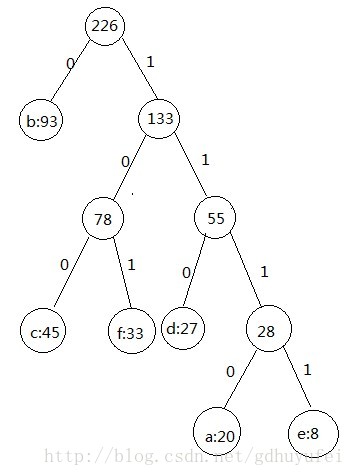
构造的赫夫曼树不是唯一的,每个字符的编码形式也不是唯一的,但每个字符的长度都是相同的,且是最优前缀编码。
3、赫夫曼变编码的实现
要实现赫夫曼编码需要合适的数据结构,一种叫做静态三叉链表的二叉树结构可以方便的实现这种算法,赫夫曼节点的结构包括频率值双亲节点值,左右孩子值,双亲节点为0的是根节点,左右孩子值为0的是叶子节点,当叶子节点数确定时,赫夫曼树的节点数也就确定了。具体代码和注释如下:
<pre class="cpp" name="huyufei">#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#pragma warning(disable:4996)
typedef struct HTNode{
unsigned int freq;
unsigned int parent, left, right;
}*HuffmanTree;//动态顺序生成的赫夫曼树
typedef char** HuffmanCode;//动态顺序生成的赫夫曼编码
//在前k个二叉树根节点中选择一个频率值最小的,并返回这个根节点的序号。
int extract_min(HuffmanTree T, int k){
int index;
unsigned int m = UINT_MAX;//保存频率的最小值,初值为不小于所有的可能值
for (int i = 1; i <= k; i++){
if (T[i].freq < m&&T[i].parent == 0){
m = T[i].freq;//保存频率小的值
index = i;//保存频率小的序号
}
}
T[index].parent = 1;//给选中的根节点的双亲赋非零值,以免重复查找这个节点。
return index;//返回这个根节点频率最小的序号
}
/*
根据频率节点freq生成赫夫曼树T,每个频率节点都有对应的编码HC;
*/
void HuffmanCoding(HuffmanTree&T, HuffmanCode&HC, int *freq, int n){
int i;
HuffmanTree t;
int total = 2 * n - 1;//n个叶子节点共需要2*n-1个节点构成赫夫曼树
if ((T = (HuffmanTree)malloc(sizeof(HTNode)*(total + 1))) == NULL){//动态生成未赋值的赫夫曼树,0号空间未用
printf("分配节点失败\n");
exit(EXIT_FAILURE);
}//如果节点分配失败,怎退出程序
for (i = 1, t = T + 1; i <= n; t++, freq++, i++){//从1号单元开始给赫夫曼树的叶子节点初始化
(*t).freq = *freq;
(*t).left = 0;
(*t).right = 0;
(*t).parent = 0;
}
for (; i <= total; i++, t++){//剩下的内部节点将双亲域初始化为0
(*t).parent = 0;
}
for (i = n + 1; i <= total; i++){//构造赫夫曼树
int l = extract_min(T, i - 1);//从i-1个单元取最小的频率值
int r = extract_min(T, i - 1);//从i-1个单元取最小的频率值
T[i].left = l;
T[i].right = r;
T[l].parent = T[r].parent = i;
T[i].freq = T[l].freq + T[r].freq;
}
HC = (HuffmanCode)malloc(sizeof(char*)*(n + 1));//分配n个叶子节点的编码空间,0号单元未用
char*temp = (char*)malloc(sizeof(char)*n);//分配求一个字符编码的工作空间
temp[n - 1] = '\0';//编码结束符
int f = 0;//父节点序号
for (i = 1; i <= n; i++){
int start = n - 1;//编码结束符的位置
for (int c = i, f = T[i].parent; f != 0; c = f, f = T[f].parent){
if (T[f].left == c){
temp[--start] = '0';//如果是左孩子则赋0
}
else{
temp[--start] = '1';//如果是右孩子则赋1
}
}
HC[i] = (char*)malloc(sizeof(char)*(n - start));//分配第i个字符空间
strcpy(HC[i], &temp[start]);//将求得的编码赋给第i个字符空间
}
free(temp);//释放资源
}
int main(){
int n;
printf("请输入要构造的频率节点:\n");
scanf_s("%d", &n);
int *freq = (int *)malloc(sizeof(int)*n);
printf("请依次给%d个节点赋值:\n", n);
for (int i = 0; i < n; i++){
scanf_s("%d", freq + i);
}
HuffmanTree T;
HuffmanCode HC;
HuffmanCoding(T, HC, freq, n);
printf("以下是赫夫曼树节点之间的关系:\n");
printf("freq\tparent\tleft\tright\n");
for (int i = 1; i <= 2 * n - 1; i++){
printf("%d\t%d\t%d\t%d", T[i].freq, T[i].parent, T[i].left, T[i].right);
printf("\n");
}
printf("--------------------------------------------\n");
for (int i = 1; i <= n; i++){
printf("频率为%d的编码为%s\n", T[i].freq, HC[i]);
}
}以上图构造的赫夫曼树为例,我们利用这个程序构造赫夫曼编码,运行结果如下所示:
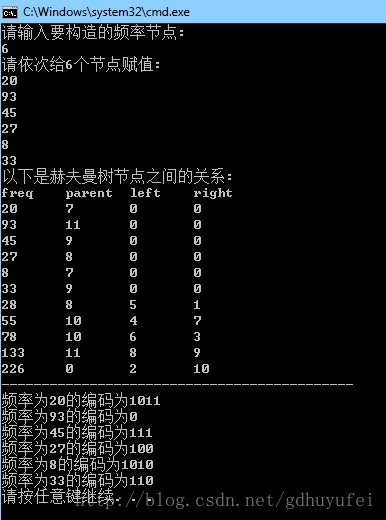
到此为止,我们根据赫夫曼算法构造的编码为变长编码,定长编码不同的是,每个字符的编码不仅是前缀码而且是最短的编码,我们可以计算这课树的代价为520与原先678个比特位的代价相比确实压缩了,实际上,这是数据较少的情况,在大量数据前,赫夫曼编码表现出更加可观的压缩效率。
关于赫夫曼编码算法的正确性,这里我不打算赘述,有兴趣的读者可以参考《算法导论》一书。
四、压缩算法的起源
要追溯压缩算法的起源,我们要把科学史向前推进30年。我们已经了解了香农,那位以其1948年论文创建信息理论领域的贝尔实验室科学家。香农在就错码故事中的两位主要的英雄之一,他与1948年发明的总要论文除了许多卓越贡献之外,好包含对压缩技术之一的的描述。麻省理工学院教授罗伯特法诺大约在同时发明了这一技术,事实上,香农-法诺编码是一种实施更短符号编码的特殊方法,我们在前面描述了更短符号编码。我们很快会知道,香农-法诺编码很快就被另一种算法所取代,但这一方法非常有效,并存活到了今天,称为ZIP格式的可选压缩方法之一。
香农和法诺都意识到,尽管他们的方法都既实用又高效,但却不是最好的算法:香农通过算术证明了肯定有更好的压缩技术存在,但还未找到。同时,法诺在麻省理工学院教授一门信息理论的研究生课程,他将实现优化压缩的问题作为该课程学期论文的可选项之一。出人意料的是,法诺的以为学生解决了这个问题,得到了针对每个符号取得最佳可能压缩的方法。这名学生就是大卫-赫夫曼,他的技术———现在以赫夫曼编码来命名,——则是更短符号编码的另一个例子。赫夫曼编码仍是一种基础压缩算法,被广泛用于通信和数据存储系统。














 138
138











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









