








Compiler Validation via Equivalence Modulo Inputs
原文链接: https://www.cs.cornell.edu/courses/cs6120/2019fa/blog/equivalence-modulo-inputs/
想象一下你,一个聪明的人,希望ta的 C 程序运行得更快. TA 坐下来,非常努力地思考,并开发了一种新的编译器优化。 假设您在 LLVM 中将它实现为一个转换过程,以便其他人可以利用您的聪明才智使他们的程序运行得更快。 您在一些基准测试中运行优化传递,并看到它确实使某些程序运行得更快。 但是一个问题困扰着你:你怎么知道你的优化是正确的? 也就是说,你怎么知道你的优化不会改变输入程序的语义?
等效模输入(Equivalence Modulo Inputs, 以下称为 EMI),一种由 Le & al 引入的测试技术。 在 PLDI 2014 论文中,允许我们上面的编译器黑客毫不费力地严格测试TA的优化。 EMI 在查找错误编译错误方面特别有效,其中编译器生成错误代码,这比编译器崩溃(编译器异常终止的错误)危害更大。 这使得 EMI 能够比之前的工作(例如 Csmith)更严格地测试编译器的优化阶段,Csmith 发现的错误编译比编译器崩溃更少。
Background
EMI 是差分测试 (differential testing) 的一种形式,这是一种广泛适用的想法,即如果假设多个系统在同一输入上产生不同的输出,则至少其中一个系统存在错误。
Csmith 还通过生成随机测试用例对编译器进行差异化测试,在 GCC 和 LLVM 发布时产生了 281 个错误报告。 Csmith 在同一个输入程序上比较多个编译器的输出,而 EMI 比较由同一编译器编译的不同程序的输出。
Le & al 明确希望避免 Csmith 通过积极的安全分析来限制随机程序生成的煞费苦心的方法。围绕生成有效种子程序的等效变体来设计他们的 EMI 实现,我们将在下面看到。 EMI 和 Csmith 的方法并不是对立的。事实上,Le & al。将 Csmith 纳入他们的工作流程。 EMI 识别出的绝大多数(除四个之外的)错误都是由 Csmith 生成的随机程序的 EMI 变体发现的。
Some definitions
现在让我们正式定义 EMI,并展示我们如何将其用作确定编译器是否有问题的条件。

很明显,EMI 是语义等价的松弛,其中 P 和 Q 对所有可能的输入具有相同的外延。
例如,以下两个程序在语义上是等价的(因此对于任何输入集都是 EMI):
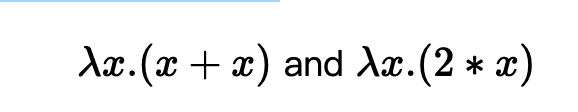
以下两个程序在语义上并不等效,但除了输入集 {0} 上的 EMI:
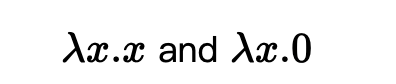
现在我们有了 EMI 的正式定义,我们如何将其用作检查编译器是否有 bug 的条件?

如果编译器不是 EMI 有效的,那么我们认为它有问题。 但反之则不然:如果编译器是 EMI 有效的,它仍然可能有问题! 考虑将所有源程序映射到同一目标程序的退化编译器。 编译器对任何输入集都是 EMI 有效的,但它显然有问题。 因此,EMI 有效性是编译器正确性的保守过度近似。
为什么这很有用? 难道我们不能仅仅通过语义等价来定义编译器的有效性,而不仅仅是它在 EMI 中的宽松对应物吗? (您可以想象定义 EMI 有效性,其中输入集是所有可能的输入。)EMI 解决了编译器差分测试中的两个实际难题:
- 我们如何生成输入程序的“等效”变体?
- 我们如何检查编译器的输出程序是否“等效”?
使用更严格的语义等价条件使得解决这些实际问题变得困难——实际上,在一般情况下 (2) 是不可计算性理论中的著名结果不可判定的。 但 EMI 更宽松的条件使这些更容易处理。 正如我们将在下面的 Orion 实现中看到的,有一个从种子程序生成 EMI 变量的有效程序,从而解决(1)。 我们确定输出程序是“等效的”,如果它们是 EMI,因为我们只检查特定输入集的等效性,这给出了(2)的有效程序。
EMI in Practice: Orion
Le & al. 通过实现 Orion(一种用于 C 编译器的错误查找工具)来实现等效模输入的承诺。 给定一个种子程序和一个输入集,它生成种子程序的 EMI 变量,然后检查编译器配置是否在这些方面是 EMI 有效的。
为了生成 EMI 变体,Orion 使用 gcov 等工具提供的代码覆盖率信息来修改种子程序的未执行部分。 直观地说,此过程生成种子程序的 EMI 变体,因为未执行的语句不应影响已编译程序的输出。
具体来说,Orion 概率性地删除种子程序的未执行语句以生成 EMI 变体。 作者考虑了其他变异策略作为未来工作的一部分,但正如我们将在下面的评估部分看到的,删除语句的简单策略在实践中效果很好。
Orion 的 EMI 变量生成算法在下面的 gen_variant 中进行了概述。
def prune_visit(prog, statement, coverage_set):
# probabilistically delete unexecuted statement
if statement not in coverage_set and flip_coin(statement):
prog.delete(statement)
# otherwise, traverse its children
else:
for child in statement.children:
prune_visit(prog, child, coverage_set)
def gen_variant(prog, coverage_set):
emi_variant = clone(prog)
for statement in emi_variant:
prune_visit(emi_variant, statement, coverage_set)
return emi_variant
gen_variant 将种子程序和覆盖集(为输入集中的某个输入执行的所有语句的集合)作为输入。 它将程序克隆到 emi_variant 中,然后使用 prune_visit 概率性地删除未执行的语句。
概述了其 EMI 变量生成算法后,我们现在可以勾勒出 Orion 验证 C 编译器所用的算法。
def validate(compiler, prog, input_set):
# compile with no optimizations
out_prog = compiler.compile(prog, NO_OPTIMIZATION)
# generate reference output
in_out_set = [(i, out_prog.execute(i)) for i in input_set]
# get coverage info
# a statement is considered covered if it was executed
# by the program on any input
coverage_set = set()
for i in input_set:
coverage_set = union(coverage_set, coverage(prog, i))
for i in range(MAX_ITER):
emi_variant = gen_variant(prog, coverage_set)
for config in compiler.configurations:
out_emi_variant = compiler.compile(emi_variant, config)
# check if compiled EMI variant is equivalent over all inputs
for i, o in in_out_set:
# compiler is not EMI-valid!
emi_o = out_emi_variant.execute(i)
if emi_ o != o:
report_bug(compiler, config, prog, emi_variant, i, o, emi_o)
validate 将编译器(compiler)、种子程序(prog)和输入集(input_set)作为输入。首先,validate 使用不优化的编译器编译 prog,然后使用其输出 (out_prog) 生成 input_set 的参考输出集。接下来,它使用代码覆盖工具(coverage)来确定对 input_set 中所有输入执行的语句集。在其“主循环”中,validate 使用计算的覆盖信息通过调用 gen_variant 生成 prog 的 EMI 变体。对于每个相关的编译器配置,它然后编译 EMI 变体并对 input_set 中的所有输入运行输出程序,以检查它返回的输出是否与参考集中记录的输出相同。如果没有,我们将当前编译器配置标记为存在错误 (report_bug)。 validate 将这个主循环重复一定次数的迭代 (MAX_ITER) 以使用不同的 EMI 变量查找更多错误。
作者指出,Orion 的实现工作比 Csmith 等其他错误查找工具的负担要轻得多:Csmith 大约有 30K-40K 行 C++,而 Orion 只有大约 500 行 shell 脚本和 1K 行 C++。
Evaluation
为了评估 EMI——即使是在 Orion 的具体实施中——必须回答几个问题:
-
将测试哪些编译器(和编译器配置)?
作者测试了 GCC 和 LLVM,这些流行的开源编译器具有透明的错误跟踪功能。编译器的最新开发版本在 x86_64 机器上进行了测试,针对 32 位和 64 位机器。因为目标是找到优化产生的错误编译,所以测试了常见的优化配置:-O0、-O1、-Os、-O2、-O3。 -
将分析和修剪哪些种子程序?
一些种子程序取自 GCC、LLVM 和 KCC 回归测试套件。作者报告尝试使用来自开源项目的测试,但无法减少和解释由此产生的错误。
大部分错误是从随机生成的 Csmith 程序开始发现的,这可能是因为每个程序平均由数千行代码组成,其中未执行行的比例很高。
虽然编译器测试程序被专家验证是正确的,但没有人验证随机 Csmith 程序产生正确的输出。只有等价(由修剪过程保留)才能确保 EMI 变体能够检测到错误,从而大大增加了种子程序的池。
-
哪些参数将指导修剪过程?
每个种子程序都生成了随机数量的变体,预计有八个变体。控制给定语句被修剪的可能性的两个随机参数在每次修剪后独立地重置为 0 到 1 之间的统一新值。
-
一旦发现错误,将如何处理错误?
作者使用 C-reduce 和 Berkeley Delta 的组合来缩小产生不同输出的 EMI 程序的大小。他们试图通过使用编译器警告、静态分析和 CompCert 来拒绝触发未定义行为的程序。最后一步是使用编译器的透明错误跟踪工具报告错误。
在这种情况下,进入标题结果:
Orion 在 2013 年的 11 个月内在 GCC 和 LLVM 中发现了 147 个已确认的独特错误。
作者 以双重方式评估这些错误:1) 受错误影响的组件的定量描述,以及 2) 对大约十个生成的程序的定性评估。
Quantitative description
评估的一个主要优势是它与 GCC 和 LLVM 的错误报告工作流的集成。尽管作者断言“首先,我们报告的大多数错误已由开发人员确认并修复,这说明了它们的相关性和重要性(因为修复错误编译通常需要付出大量努力)”,但事实是 182外部专家确认报告的 195 个错误(其中 35 个被标记为重复)确实存在,这证明 EMI 是一种可行的错误发现策略。
95 个已确认的错误是错误编译,这证实了作者最初的说法,即 Orion 能够比单独的 Csmith 更容易地针对错误编译。在 GCC 和 LLVM 的开发主干中发现了最多的错误。在不断提高的优化级别中也发现了更多错误,其中最多的是 -O3。
在类似于 Csmith 使用的差异测试场景中,作者还通过相互比较编译器发现了性能错误。 147 个已确认的错误中有 19 个是性能问题。
需要注意的是,这些只是 Orion 发现的错误。由于 Orion 专门针对优化阶段,因此可以理解 GCC 树优化和 RTL 优化是发现错误最多的组件(LLVM 开发人员没有对报告的错误进行分类)。这些组件不一定有比其他组件更多的错误,也不是唯一可能的错误。
作者并未尝试评估 Orion 在产生这些报告的错误时所探索的搜索空间。他们也没有明确确定导致已识别错误的生成变体的比例。他们只是报告说他们没有记录他们开始使用多少种子程序或他们产生了多少变种(只是估计“数百万到数千万”)。他们也没有报告(并且可能没有记录)Csmith 配置或 Orion 的动态修剪参数。
Qualitative examples
据说已确认的错误涵盖编译器段错误、内部编译器错误、性能问题和错误的代码生成。 作者展示并解释了一些由编译器开发人员确认和修复的错误。 我们只强调其中的两个来体验生成的程序。 请注意,作者仅展示了他们向编译器开发人员报告的精简代码; 它们既没有显示非简化版本,也没有显示 EMI 变体。
以下示例在使用 GCC 编译时导致段错误,因为在称为“预测公共”的优化过程中偏移计算错误,这是一种公共子表达式消除形式:
int b, f, d[5][2];
unsigned int c;
int main() {
for (c = 0; c < 2; c++)
if (d[b + 3][c] & d[b + 4][c])
if (f)
break;
return 0;
}
Clang incorrectly vectorized the following code:
int main() {
int a = 1;
char b = 0;
lbl:
a &= 4;
b--;
if (b) goto lbl;
return a;
}
Current statistics
EMI 项目的网站显示了使用 EMI 方法的工具发现和修复的错误数量。 它显示了在 GCC 和 LLVM 中发现的大量错误,以及该技术对其他语言(如 Scala)的编译器的有用性。

Discussion
论文中的其余示例涵盖跳转线程逻辑、全局值编号、内联、矢量化和性能方面的问题。因为作者只分析了几个精选的例子,所以仍然存在一个问题:这八个例子是否代表了所有其他错误?
此外,作者声称:“从现有代码生成的 EMI 变体,比如通过 Orion,很可能是人们实际编写的程序。”这是真的吗,尤其是当随机程序被用作种子时?上面讨论的两个例子也是如此吗?
结果表明,种子程序的类型对发现的错误数量有很大影响。与从编译器测试套件和开源项目测试中提取的程序相比,随机生成的 Csmith 种子程序显示的错误要多得多。这表明 EMI 应该与现有的模糊器结合使用。其他模糊器是否提供适用的种子程序?
最后,作者将 EMI 吹捧为一种通用验证技术,可用于差异化测试应用程序,例如其他语言的编译器。您认为这种方法对其他应用程序和测试 C 编译器一样有用吗?















 148
148











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









