







Kafka 属于分布式的消息引擎系统,它的主要功能是提供一套完备的消息发布与订阅解决方案。
Topic
本质上一个Topic是命名的记录流。Kafka用log的方式记录这些主题数据。一个主题Log会分成若干个分区(Partition),而这些分区可以分布在不同的Kafka Server上或者不同的磁盘上。换句话说,我们可以认为一个主题是一个分类目录,是一个消息流名称,或者是一个订阅源。
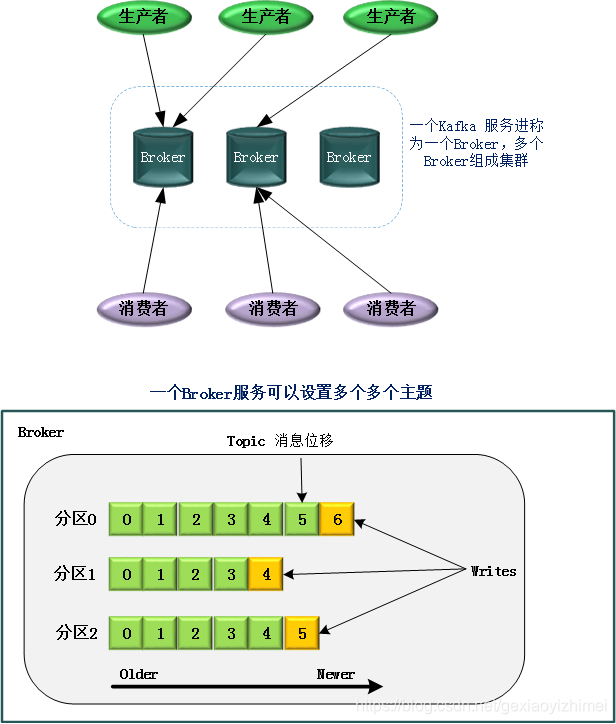
Partition
Topic被分为多个Partition,Producer产生的消息会被送到其中的某个分区。分区的编号从0开始。消息进入kafka后,会被送入某个主题的某个分区。具体进入哪个分区取决于:
- Partition id:如果消息中指定了该值
- key % num partitions:如果指定了key
- Round robin :消息既没有partition id 也没有message key ,就会轮询进入各个partition
每个分区中的消息按照顺序排列,kafka通过消息偏移(offset)可以确定消息在分区中的位置。值得注意的是,发送的消息如果是在固定的分区,消息序列是有序的,而如果是不同的分区则无法保证顺序。
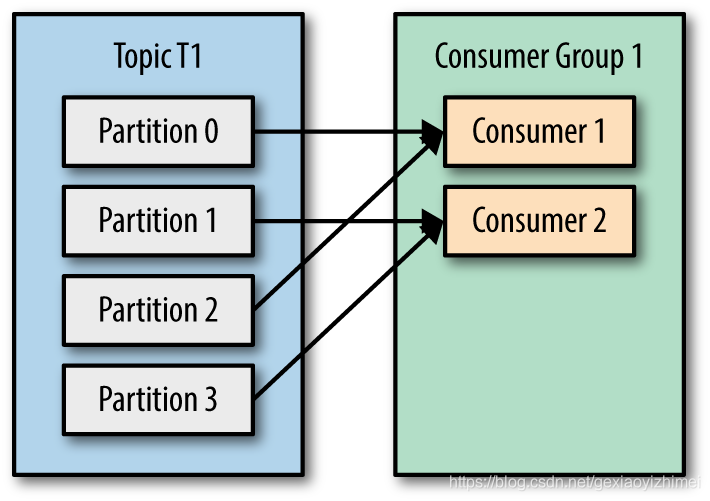
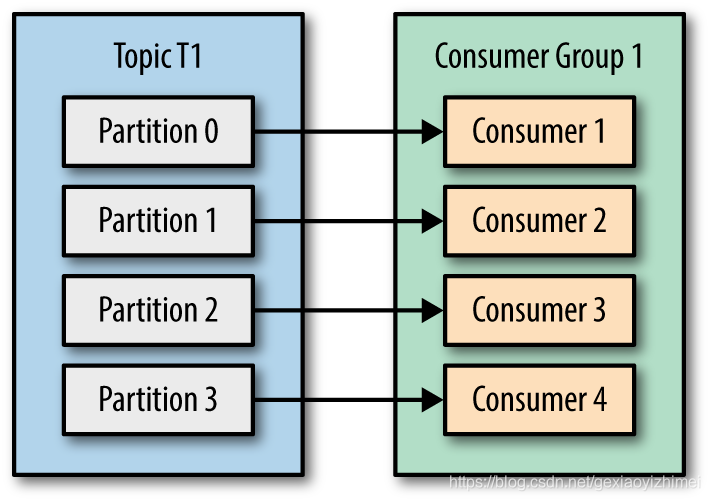
消费者消费消息时,为了提高消息者端的吞吐量,kafka引入了消费者组。多个用户组成一个消费者组,共同消费一个主题各个分区的消息。并且一个分区只能由一个消费者去消费,但是一个消费者可以消费多个分区:
- 当分区多于消费者时:
- 当分区和消费者相等时:
- 当分区小于消费者时:
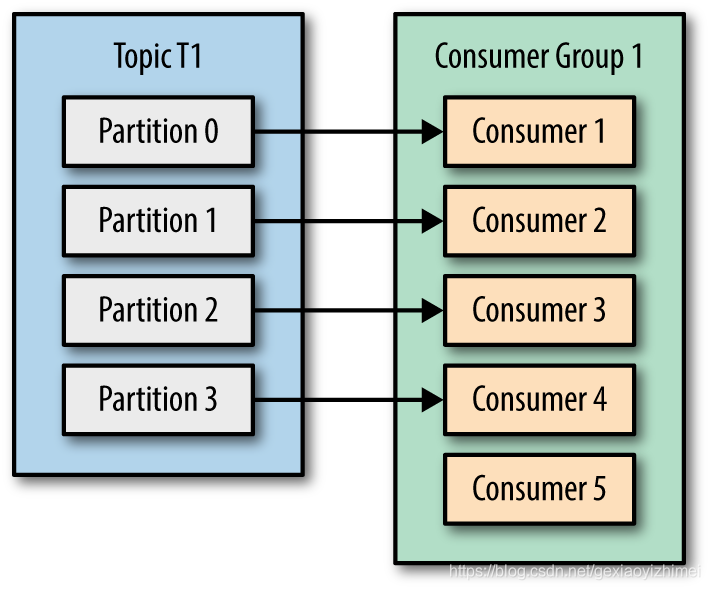
如果某个消费者挂掉,其持有的分区会重新分配其他消费者,这就是Kafka的重平衡(Rebalance)。
分区的副本,kafka为了保证数据的高可用,会在配置数量的broker上复制分区的副本,这些副本中只有一个Leader,其他的称为Follower。Leader分区负责对外提供读写服务,其他Follower会同步数据,只做数据冗余备份。这些副本Kafka用Zookeeper管理,一旦Leader挂掉,会重新再副本中选举新的Leader. 这些只做数据同步备份的分区我们称为 ISR (in-sync replica)
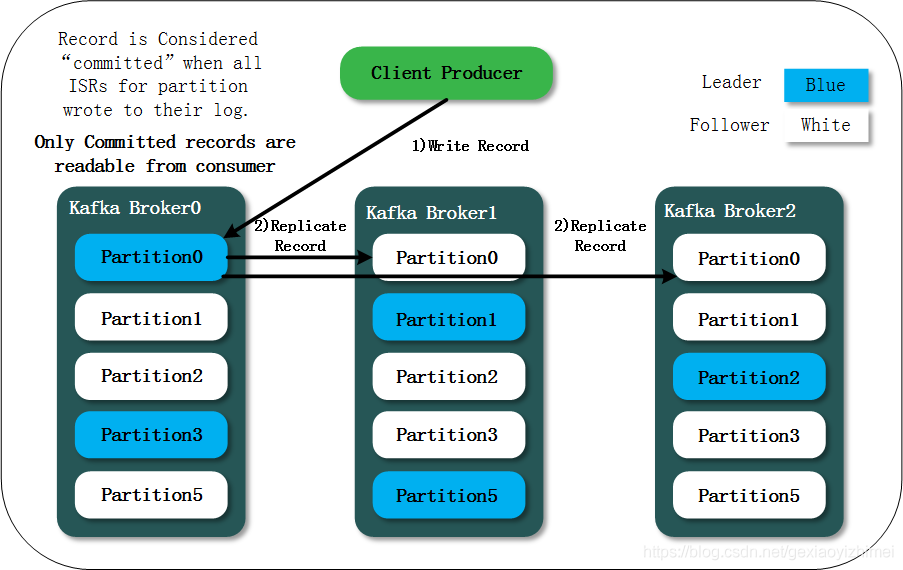
只有当所有备份副本都将消息写入自己的Log,这条消息的状态才会变为“commited”,此时它才可以被消费。
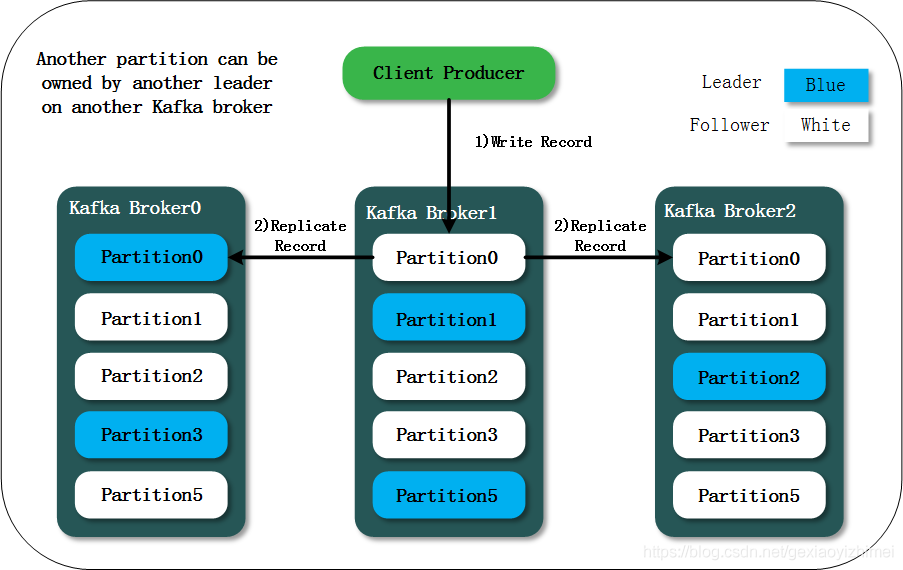
Record
Record(消息)是Producer和Consumer处理的对象和Kafka要处理的具体对象。














 295
295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









