



基于RTL模型的无加法器架构低功耗空时格状码维特比译码器设计
1. 引言
如今,采用多输入多输出(MIMO)天线的空时格状码(STTC)技术已引起无线通信系统领域人士的关注。它通过分集技术提供了更高的质量和频谱效率增益(Tarokh等,1998)。MIMO技术被用于基于IEEE 802.11n标准的无线保真(Wi-Fi)、第三代移动通信(3G)的高速分组接入(HSPA)、第四代移动通信(4G)的WiMax以及长期演进(LTE)。目前,MIMO系统能够通过同一无线电通道同时发送和接收数据。MIMO由两部分组成,即空间复用和分集编码。在该技术中,一个高速数据信号被划分为多个低速数据信号。每条信息通过使用相同频率的多个天线进行发送(Tarokh等,1998)。该技术的缺点是要求在发射端和接收端均具备相同的信道状态信息(CSI)。分集编码技术不需要在发射端具备信道状态信息(CSI)。采用分集编码技术时,仅传输一个数据流,而空间复用技术则传输多个数据流。通过分集编码技术传输的信息采用空时编码(STC)进行编码。空时编码(STC)是一种利用多天线发射端来提高无线通信系统数据传输可靠性的技术。空时编码(STC)包含两个部分:空时网格码(STTC)和空时分组码(STBC)。空时网格码(STTC)通过多个天线和多个时间段来分离格状码,旨在提高编码增益和分集增益,而空时分组码(STBC)
仅使用一个数据块进行操作。STBC 提供了分集增益优势,但与 STTC 相比无法提供编码增益。因此,在本文中选择 STTC 技术作为纠错码。许多已发表的研究型论文提出了为所提出的 STTC 系统构建新码的方法(Shr 等人,2010;Devi 和 Rao, 2012;Pujara 和 Prajapati, 2013;Kavinilavu 等人, 2011;Mathana 等人,2013),并建议对码进行修改。在 Shr 等人(2010)的一篇出版物中,作者讨论了四状态空时网格码解码格图码的设计、实现及测试结果。该系统采用正交相移键控(QPSK)映射,并通过环回测试仿真验证系统性能。在另一篇出版物(Devi 和 Rao, 2012)中,作者提出了一种可配置的空时网格码维特比译码器算法。该算法采用0.18‐μm互补金属氧化物半导体(CMOS)技术进行设计和实现。译码器设计采用了四相相移键控(PSK)调制技术。在 Pujara 和 Prajapati(2013)的研究中,提出使用 Verilog硬件描述语言(HDL)代码实现约束长度为7、码率为1/2的维特比算法卷积码。使用 Xilinx ModelSim PE 10.0 和 12.4 对维特比译码器进行了仿真和综合。关于维特比算法,Kavinilavu 等人(2011)提出使用 Virtex‐6 FPGA 设计卷积码。该设计方法通过采用基‐2和基‐4技术实现了360 Mbps的数据速率。针对空时网格码维特比算法,有研究提出使用 Xilinx Spartan‐3 FPGA Xc3s200E,并记录这些器件的功耗为41毫瓦(Mathana 等人,2013)。该提案展示了适用于快衰落信道和慢衰落信道的硬件架构。进行了复杂度分析,以提供所需信息,使所提出的方法可用于不同的 STTC 配置。Vestias 等人(2012)提出了一种基于 Verilog HDL语言的低功耗设计,用于网格编码调制(TCM)系统的维特比译码。采用机械预计算架构和 T算法 来降低功耗,同时不牺牲维特比译码器性能。该研究使用专用集成电路技术和台积电90纳米CMOS标准单元硬件完成。Chen 等人(2014)研究了三位软判决维特比译码器在解码 TCM译码器 时的星座映射。该研究利用 LabVIEW FPGA 设计了一个 TCM编解码电路,用于仿真加性白高斯噪声信道中的误码率曲线。仿真结果优于 QPSK、8‐PSK 和 IESS‐310 标准的误码率(BER)曲线。已设计出一种使用码率1/2、1/3、2/3、3/4、5/6,约束长度3到9,以及任意长度数据块的维特比译码器卷积码。所提出的译码器使用 ISE软件 进行设计和综合,并在 Xilinx XCV330T 器件上实现(Pradhan 和 Nandy,2014)。Prakash 和 Balamurugan(2015)提出使用卷积码维特比译码器实现 16‐PSK,以支持高速数据传输。本文描述了四位输入数据被编码后得到16种编码数据组合的情况。该论文还描述了在每次传输时计算汉明距离的技术。分支度量计算(BMC)通过将节点值与前一状态值相加来实现。本研究结果表明,在解码部分,输出端可用的数据与发送数据相比无任何错误地被解码。使用卷积码设计了一种可重构维特比解码器。本文中的维特比解码器架构支持约束长度为3、5和7,码率为1/2和1/3,适用于WiMax、无线局域网、3GPP2、全球移动通信系统和长期演进技术等常见标准(Mostafa等,2016年)。该维特比解码器使用Xilinx ISE 14.5外设仿真器进行设计和仿真,并在Xilinx ZedBoard Zynq‐7000 FPGA器件上用VHDL语言实现。此外,对某些部分进行了改进,例如加‐比较‐选择(ACS)单元,成功将功耗有效降低了26%。
本文中,STTC维特比解码器使用Verilog HDL语言设计,并利用Altera Quartus II和PowerPlay 功耗分析器工具进行仿真和综合。该解码器采用CMOS技术以及0.18μm Altera MAX V 复杂可编程逻辑器件(CPLD)硬件实现。据作者所知,这是首个提出并使用CPLD芯片实现的STTC维特比解码器。本文结构如下:引言部分介绍了STTC解码算法;文献综述部分阐述了当前的STTC解码器;提出方法部分解释了用于STTC解码器设计的一种改进型加法器架构;结果与讨论部分说明了改进型加法器维特比解码器的结果;最后,在最后部分给出了本文的结论。


2. 文献综述
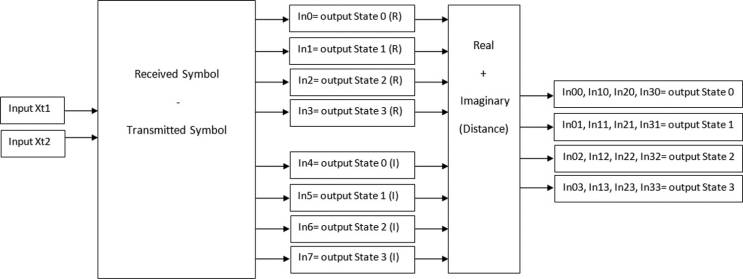
图1显示了一个典型的空时网格码维特比译码器的框图,该译码器包含BMC、ACS单元和路径度量更新器(PMU)。输入比特为Xt1和Xt2,输出比特为Ct1和Ct2。
对于从时间t1的状态0开始的STTC译码器网格图,每个状态都有四种可能的转移。对于该网格译码器,每个分支度量值均被计算根据每个时间间隔内接收符号与来自编码器网格的发送符号之间的欧氏距离。网格图的设计基于状态机,用于计算从前一状态到下一状态的转移。每个节点的标记方式与状态机类似,即 S0= 00、S1= 01、S2= 10、S3= 11。每个状态可以从四个前一状态进入。状态 S0 的输入比特为 00,S1 为 10,S2 为 20,S3 为 30。状态 S1 的输入比特为 01。S1 是 11,S2 是 21,S3 是 31。状态 S2 的输入比特为 02,S1 为 12,S2 为 22,S3 为 33。状态 S3 的输入比特为 03,S1 为 13,S2 为 23,S3 为 33。输入和输出支路的值与格状图分支上显示为 输入/输出 的状态转移相关,如 图2 所示。
3. 提出的方法
3.1 解码器寄存器传输级
图3显示了现有设计的解码器寄存器传输级(RTL)。该图包含一个BMC(u1)、一个ACS(u2)和一个PMU(u3)。BMC包含输入,如时钟(clk)、2位输入Xt1和Xt2以及5位16输出引脚。ACS模块包含输入,如时钟(clk)、5位16输入引脚、复位(res)和一个4位ACSout输出引脚。PMU包含一个4位ACSout输入、时钟(clk)、复位(res)和2位 Ct输出引脚。该模块的总逻辑单元为285,以及一个输出引脚。

3.2 Branch metric computation register transfer level
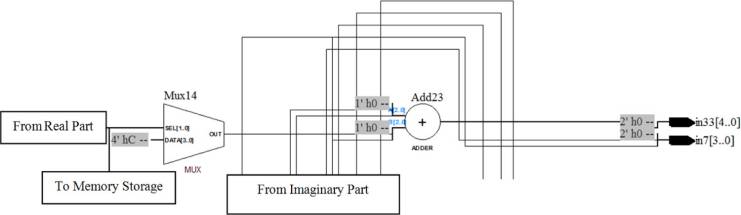
BMC包含24个加法器和16个二选一多路复用器。Add0到 Add7模块的功能是计算接收符号与发送符号之间的差值。加法器模块的输出被存储在存储器中,并发送到比较器中的多路复用器,如图4所示。多路复用器的功能是根据输入位的结果选择输出位,如图5所示。Add8到Add23模块的功能是使用欧几里得距离方法对接收信号和发送信号之间差值的实部和虚部进行相加,如图6所示。该BMC设计的总逻辑单元为40个逻辑元件,如图7所示。
图7显示了BMC的详细实现框图。BMC的输入为Xt1和 Xt2。输入比特将与发送符号相减,产生八个输出,即In0至 In7。其中In0至In3是I平面的输出,In4至In7是Q平面的输出。实际上,In0对应状态0的输出,In1对应状态1的输出,In2对应状态2的输出,In3对应状态3的输出。理论上,In4对应状态0的输出,In5对应状态1的输出,In6对应状态2的输出,In7对应状态3的输出。接下来的模块是将相同状态的 I平面信号和Q平面信号相加以生成BMC模块的总输出。



3.3 ACS RTL(现有设计)
ACS RTL 部分包含 16 个加法器、15 个寄存器、179 个比较器、12 个与门和 11 个二选一多路复用器。add 模块的功能是将分支度量和状态度量值相加。寄存器的功能是在如图8所示的 RTL 图中存储当前状态度量值。比较器的功能是比较每个状态的分支度量的最小数量,以及 AND
门电路在RTL图中比较来自其他状态的分支度量,如图9所示。多路复用器选择最小分支度量,并将其作为状态度量存储在RTL图中,如图10所示。该设计的逻辑元件总数为233,如图11所示,为现有ACS设计的详细实现。



3.4 ACS RTL(提出的设计)
改进的ACS RTL部分包含179个比较器、12个与门和11个多路复用器。比较器的作用是比较每个状态的最小分支度量数量,与门的作用是比较来自其他状态的分支度量,如图12所示。多路复用器的作用是选择最小分支度量值并将其存储为状态度量值,如图13所示。该设计的逻辑元件总数为196个逻辑元件,如图14所示。与现有设计相比,该提出的设计使逻辑元件总数减少了15.8%。



3.5 PMU RTL
PMU RTL 包含七个寄存器,标记为 T1 到 T7;三个多路复用器,标记为 Mux0 到 Mux2;以及两个锁存器,标记为 Ct[0]$latch 和 Ct[1]$latch。寄存器的功能是在回溯过程开始之前存储最小分支度量和路径度量的计算值。多路复用器的功能是根据解码查找表将回溯结果解码为正确的值。此设计的总逻辑单元为 12 个逻辑元件。图15 显示了 PMU RTL 的框图。

4. 结果与讨论
参考表I,已有四项先前的研究针对三个因素的差异进行了探讨,这三个因素分别是功耗、改进百分比和器件使用数量。功耗数据来自各项先前研究,并采用相同技术在0.18μm下进行,以确保技术因素不会影响本研究所提出的结果。通过与先前研究建议的比较,本文提出的研究具有最低的功耗和最少的器件与之前四项研究相比的资源利用率。基于表I,本研究所用器件最多为967个单元,而本研究提出的器件仅使用30个单元。改进百分比是根据最高功耗213毫瓦与其他参考文献(包括本研究产生的功耗)之间的差值计算得出。参照表I,本文提出的研究实现了最高的改进百分比,达到96%。这表明加法器模块比BMC和PMU消耗更多功率,因为加法器模块涉及复杂的算术处理。在对STTC维特比译码器的五项研究中,第一项研究由Shr等(2010)进行,仅关注BMC的优化,而其他研究(Devi 和 Rao, 2012;Pujara 和 Prajapati, 2013;Kavinilavu等,2011)则专注于PMU中回溯单元的优化。本文提出的研究聚焦于加法器模块中的优化方法,据先前研究报道,加法器模块被认为是最复杂且最难优化的部分。
| 作者 | 优化部分/技术 | 功率(mW) | 设备利用率 | % 改进 |
|---|---|---|---|---|
| Shr 等人 | (BMC)/0.18 μm CMOS | 0.43 | 850 | 12 |
| Uma Devi 等人 | (回溯单元)/0.18 μm CMOS | 213 | 967 | 0 |
| Pujara 等人 | (回溯单元)/Spartan FPGA | 49 | 351 | 67 |
| Manthana 等人 | (回溯单元)/Xilinx FPGA | 20 | 181 | 81 |
| 本研究 | (ACS)/0.18 μm CMOS | 0.07 | 30 | 96 |
5. 结论
本文提出了一种优化的ACS RTL架构维特比译码器作为其主要贡献。使用Verilog代码设计了提出的维特比译码器。所设计的空时网格码维特比译码器通过Quartus II仿真器进行了仿真,并利用PowerPlay功率分析工具完成了综合。仿真与综合结果表明,该提出的设计在目标Max V CPLD器件上能够以50兆赫兹的预估频率运行,并且占用较少的资源。本文还对以往CPLD器件在空时网格码维特比译码器设计中的应用进行了对比分析。结果表明,与以往文献报道的结果相比,该提出的设计在目标Max V CPLD板上的功耗降低了96%。

















 818
818

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









