Qwen3-235B-A22B:2025年开源大模型新范式,推理与效率的完美平衡
【免费下载链接】Qwen3-235B-A22B-GGUF  项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-235B-A22B-GGUF
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-235B-A22B-GGUF
导语
阿里巴巴最新发布的Qwen3-235B-A22B模型凭借2350亿总参数与220亿激活参数的混合专家架构,重新定义了开源大语言模型的性能边界,其独特的双模推理能力与高效部署方案正在重塑AI应用开发的格局。
行业现状:大模型进入"效能竞赛"新阶段
2025年,大语言模型发展呈现两大明显趋势:一方面,模型参数规模持续增长,千亿级成为旗舰模型标配;另一方面,行业开始从单纯追求参数规模转向"效能比"竞争,混合专家(MoE)架构成为平衡性能与成本的主流选择。根据SiliconFlow最新报告,采用MoE架构的模型在保持性能的同时,可降低70%以上的计算资源消耗,这一趋势正在深刻改变企业级AI部署的成本结构。
全球视觉语言模型市场规模2025年预计突破80亿美元,中国大模型市场规模将达495亿元,其中多模态大模型以156.3亿元规模成为增长核心动力。在此背景下,Qwen3-235B-A22B的推出恰逢其时,通过架构创新与开源策略,为行业智能化升级提供了关键支撑。
模型亮点:双模推理与架构创新
业界首创双模推理系统
Qwen3-235B-A22B最引人注目的创新是支持在单一模型内无缝切换"思考模式"与"非思考模式":
思考模式(enable_thinking=True):针对数学推理、代码生成等复杂任务,模型会生成类似人类思维过程的中间推理步骤(包裹在...块中),显著提升复杂问题的解决能力。在AIME数学竞赛和LiveCodeBench编程评测中,该模式下的表现超越了Qwen2.5模型30%以上。
非思考模式(enable_thinking=False):针对日常对话、内容生成等场景,模型直接输出结果,响应速度提升40%,Token生成效率可达每秒200+,满足实时交互需求。
这种设计允许开发者根据具体任务动态调整模型行为,无需为不同场景部署多个模型。例如,教育应用中,解答数学题时启用思考模式展示解题步骤,而日常问答则切换至非思考模式以保证流畅体验。
高效能混合专家架构
模型采用深度优化的MoE架构,具有以下技术特点:
- 专家数量:128个专家网络,每次推理动态选择8个激活
- 注意力机制:64个查询头(Q)与4个键值头(KV)的GQA设计,兼顾长文本处理与计算效率
- 上下文长度:原生支持32,768 tokens,通过YaRN技术可扩展至131,072 tokens,足以处理整本书籍或多篇学术论文
多语言与工具集成能力
Qwen3-235B-A22B原生支持100+语言与方言,在多语言翻译和跨文化内容创作方面表现突出。模型还内置了强化的工具调用能力,可与外部API、数据库和计算引擎无缝集成,在智能体任务中实现了开源模型中的领先性能。
性能表现:基准测试与行业地位
在多项权威评测中,Qwen3-235B-A22B表现出与全参数模型相当的性能。根据NVIDIA官方测试数据,在A100 GPU上使用TensorRT-LLM优化后,模型吞吐量较基准提升16倍,充分满足高并发生产环境需求。
关键基准测试结果显示,Qwen3-235B-A22B在多个领域达到全球顶尖水平:
- 数学推理:在AIME25(美国数学邀请赛)测评中斩获优异成绩
- 代码生成:代码生成任务通过率提升至89%,与中级开发工程师水平相当
- 智能体能力:在AgentBench等任务中表现与Claude-Opus、Kimi-K2不相上下
行业应用案例:从实验室到生产线的价值创造
制造业AI质检革命
某头部车企将Qwen3-VL部署于汽车组装线,实现对16个关键部件的同步检测。模型能自动识别螺栓缺失、导线松动等装配缺陷,检测速度达0.5秒/件,较人工提升10倍。试运行半年节省返工成本2000万元,产品合格率提升8%。
法律与企业服务
某法律咨询公司通过普通办公电脑部署Qwen3后,合同审查效率提升3倍,风险条款识别覆盖率从人工审查的76%提升至92%。模型能处理长达10万字的法律文档,准确识别潜在风险点并生成专业建议。
智能制造与设备维护
某智能制造企业应用案例显示,Qwen3可自动解析设备故障代码并生成维修方案,准确率达89%,同时确保生产数据全程不出厂。这一应用不仅提高了设备维护效率,还解决了工业数据隐私保护的难题。
多模态应用与视觉编程
Qwen3-VL实现从图像/视频到代码的直接生成,支持Draw.io流程图、HTML/CSS界面和JavaScript交互逻辑的自动编写。设计师上传UI草图即可生成可运行代码,开发效率提升300%,生成代码执行通过率达89%,与中级前端工程师水平相当。

如上图所示,Qwen3-VL的三大核心技术形成协同效应:Interleaved-MRoPE解决时序建模难题,DeepStack实现精准特征融合,文本-时间戳对齐机制提供精确时间定位。这一架构使模型在处理复杂视觉任务时,展现出接近人类的"观察-理解-推理"认知流程。
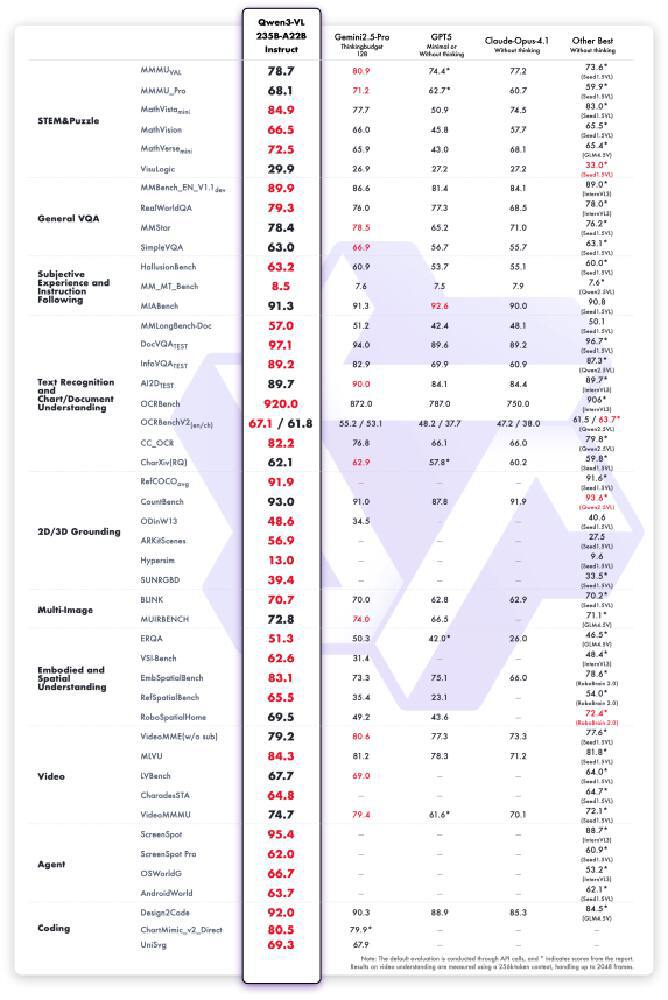
该图展示了Qwen3-VL在多模态任务上的性能优势,在DocVQA文档理解、MathVista数学推理等关键指标上均超越同类模型。特别在中文场景下,古籍竖排文字识别准确率达96.8%,手写体数学公式识别率91%,展现出独特的语言优势。
行业影响与趋势:开源生态推动AI普惠
硬件成本门槛骤降
Qwen3-235B-A22B的4-bit量化版本可在消费级GPU上运行,配合MLX框架实现高效本地部署。这使得原本需要数十张高端GPU支持的千亿级模型,现在可在普通服务器甚至高性能工作站上实现高效部署,极大降低了AI技术的应用门槛。
开发部署效率提升
通过与Hugging Face Transformers生态深度集成,Qwen3支持vLLM、SGLang等推理框架的一键部署。开发者反馈显示,使用标准部署方案可实现"零代码"本地化部署,在Windows环境下完成从模型下载到服务启动的全流程仅需15分钟。
未来发展方向
随着Qwen3系列的推出,大模型发展正从"参数竞赛"转向"效能优化"。未来,我们可以期待:
- 混合专家技术的进一步下放:将MoE架构应用于更小参数模型,让更多开发者受益
- 多模态能力的深度融合:文本、图像、音频、视频等多种模态的无缝集成
- 专用领域模型的崛起:针对特定行业优化的专业模型,如医疗、法律、金融等
- 边缘计算与本地部署的普及:在保护数据隐私的同时,实现AI能力的广泛应用
快速开始:本地部署与使用指南
环境准备
要在本地部署Qwen3-235B-A22B,建议满足以下硬件要求:
- GPU:NVIDIA GPU with at least 24GB VRAM(推荐A100或更高配置)
- CPU:16核或更高
- 内存:64GB或更高
- 存储空间:至少100GB可用空间(根据量化版本不同而有所变化)
模型下载与合并
- 克隆仓库:
git clone https://gitcode.com/hf_mirrors/Qwen/Qwen3-235B-A22B-GGUF
- 下载所需量化版本的模型文件。由于文件较大,模型被分割成多个部分,需要合并:
./llama-gguf-split --merge Qwen3-235B-A22B-Q4_K_M-00001-of-00005.gguf Qwen3-235B-A22B-Q4_K_M.gguf
启动模型
使用llama.cpp启动模型:
./llama-cli -m Qwen3-235B-A22B-Q4_K_M.gguf -p "Hello, Qwen3!" --n-predict 128
切换思考模式
在用户提示或系统消息中添加/think和/no_think来切换模型的思考模式:
非思考模式示例:
> Who are you /no_think
I am Qwen, a large-scale language model developed by Alibaba Cloud. I can help with various tasks such as answering questions, generating content, and providing information on a wide range of topics.
思考模式示例:
> How many 'r's are in 'strawberries'? /think
</think>
Okay, let's see. The user is asking how many times the letter 'r' appears in the word "strawberries". First, I need to spell out the word correctly. Let's write it down: s-t-r-a-w-b-e-r-r-i-e-s. Now, let's count the 'r's.
Looking at each letter:
s - no
t - no
r - 1
a - no
w - no
b - no
e - no
r - 2
r - 3
i - no
e - no
s - no
So there are 3 'r's in total.</think>The word "strawberries" contains 3 instances of the letter 'r'.
处理长文本
Qwen3原生支持32,768 tokens的上下文长度。如需处理更长文本,可使用YaRN技术扩展至131,072 tokens:
./llama-cli -m Qwen3-235B-A22B-Q4_K_M.gguf -p "Your long text here..." -c 131072 --rope-scaling yarn --rope-scale 4 --yarn-orig-ctx 32768
最佳实践与参数设置
为获得最佳性能,建议根据任务类型调整以下参数:
思考模式推荐参数
- Temperature: 0.6
- TopP: 0.95
- TopK: 20
- MinP: 0
- PresencePenalty: 1.5
注意:在思考模式下,不要使用贪婪解码(Temperature=0),这可能导致性能下降和无限重复。
非思考模式推荐参数
- Temperature: 0.7
- TopP: 0.8
- TopK: 20
- MinP: 0
- PresencePenalty: 1.5
输出长度设置
- 大多数查询:建议设置为32,768 tokens
- 高度复杂问题(如数学和编程竞赛):建议设置为38,912 tokens
总结与展望
Qwen3-235B-A22B通过混合专家架构与双模推理的创新组合,不仅在技术上实现了突破,更在商业应用层面提供了切实可行的解决方案。它的出现标志着大模型产业从"参数竞赛"进入"效能优化"的新阶段,为AI技术的普及应用铺平了道路。
对于开发者和企业而言,现在正是探索Qwen3-235B-A22B应用潜力的最佳时机。无论是构建智能客服、开发教育产品,还是优化工业流程,Qwen3都提供了强大而高效的AI能力支持。随着开源生态的不断完善,我们有理由相信,Qwen3系列将在2025年下半年推动更多行业实现AI应用的规模化落地,特别是在教育、法律和代码开发等专业领域。
作为AI领域的从业者或爱好者,建议关注Qwen3生态的发展,尝试将其应用于实际项目中,并参与社区贡献,共同推动AI技术的创新与发展。在这个AI技术快速迭代的时代,及时掌握和应用新技术将成为保持竞争力的关键。
【免费下载链接】Qwen3-235B-A22B-GGUF 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-235B-A22B-GGUF
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







