



Ploomber项目实战:如何将传统Jupyter Notebook重构为可维护的数据流水线
 项目地址: https://gitcode.com/gh_mirrors/pl/ploomber
项目地址: https://gitcode.com/gh_mirrors/pl/ploomber 前言
在数据科学和机器学习项目中,Jupyter Notebook因其交互性和可视化优势广受欢迎。然而随着项目规模扩大,传统Notebook往往变得难以维护和扩展。Ploomber项目提供了一套优雅的解决方案,可以将这些"遗留"Notebook重构为模块化、可复用的数据流水线。
准备工作
示例Notebook获取
为了演示重构过程,我们需要一个示例Notebook。你可以使用自己现有的Notebook,或者通过以下方式获取一个标准示例:
curl -O https://raw.githubusercontent.com/ploomber/soorgeon/main/examples/machine-learning/nb.ipynb
Notebook结构要求
Ploomber重构工具对Notebook有一个关键要求:必须使用H2标题(Markdown中的##)来划分不同的代码段。这种结构化的组织方式使得工具能够识别Notebook中的逻辑模块。
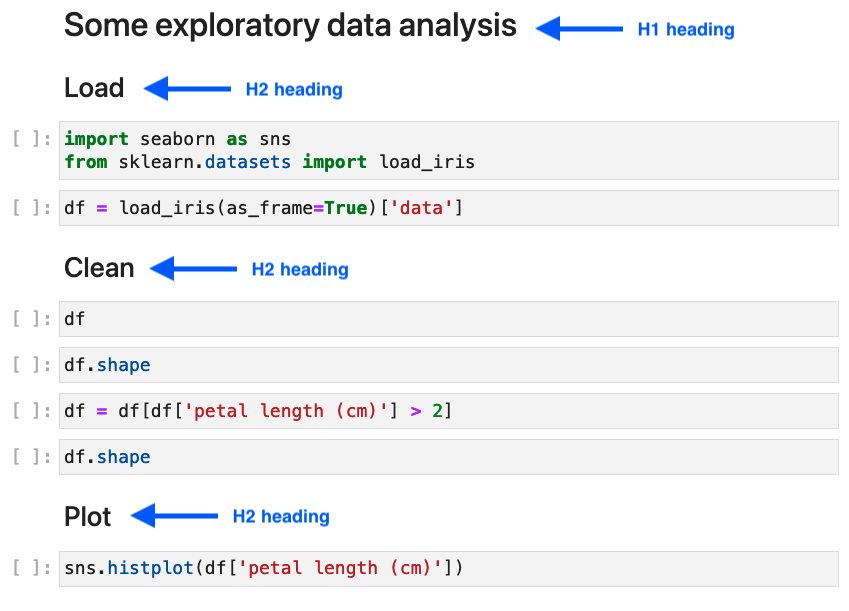
一个典型的可重构Notebook可能包含以下结构:
- 数据加载(## Load data)
- 数据清洗(## Clean data)
- 特征工程(## Feature engineering)
- 模型训练(## Train model)
重构过程详解
安装必要工具
首先需要安装Soorgeon工具包,这是Ploomber生态中专门用于Notebook重构的工具:
pip install soorgeon
基础重构命令
执行以下命令开始重构过程:
soorgeon refactor nb.ipynb
这个命令会执行以下操作:
- 分析Notebook结构
- 根据H2标题将Notebook拆分为多个独立文件
- 生成pipeline.yaml文件描述整个流水线结构
高级选项
输出Python文件格式
默认情况下,工具会生成.ipynb格式的任务文件。如果你更喜欢.py格式(同样可以在Jupyter中作为Notebook打开),可以使用:
soorgeon refactor nb.ipynb --file-format py
单任务模式
如果工具无法自动拆分你的Notebook(可能因为结构不够清晰),可以使用单任务模式:
soorgeon refactor nb.ipynb --single-task
这会生成一个只包含单个任务的流水线,作为重构的起点。
运行重构后的流水线
重构完成后,按照以下步骤运行流水线:
- 安装依赖:
pip install -r requirements.txt
- 执行流水线:
ploomber build
重构后的优势
将传统Notebook重构为Ploomber流水线后,你将获得以下好处:
- 模块化:每个逻辑单元成为独立任务,便于维护和重用
- 依赖管理:明确的任务依赖关系,确保执行顺序正确
- 可扩展性:轻松添加新任务或修改现有任务
- 可复现性:完整的流水线定义,确保结果一致
- 团队协作:更适合多人协作开发的代码结构
常见问题解答
Q:我的Notebook没有使用H2标题,还能重构吗? A:可以,但建议先添加H2标题划分逻辑块。如果实在无法修改,可以使用--single-task模式先创建单任务流水线。
Q:.py文件和.ipynb文件在Ploomber中有何区别? A:功能上几乎没有区别,Ploomber完美支持两种格式,且.py文件可以通过Jupyter直接作为Notebook打开。选择哪种格式主要取决于团队偏好。
Q:重构后会丢失Notebook原有的输出和图表吗? A:会,重构过程只保留代码和Markdown内容。这是有意为之,因为流水线应该从干净状态开始执行。
进阶建议
- 版本控制:重构后的流水线更适合使用Git等版本控制系统管理
- 参数化:考虑将硬编码值提取为参数,提高代码灵活性
- 测试:为关键任务添加单元测试
- 文档:利用pipeline.yaml文件作为项目文档的一部分
通过Ploomber的重构工具,数据科学家可以轻松地将探索性Notebook转化为生产就绪的数据流水线,实现从原型到产品的平滑过渡。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考




















 3304
3304

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











