






Spring batch整体的架构设计使用如下关系图来进行表示:
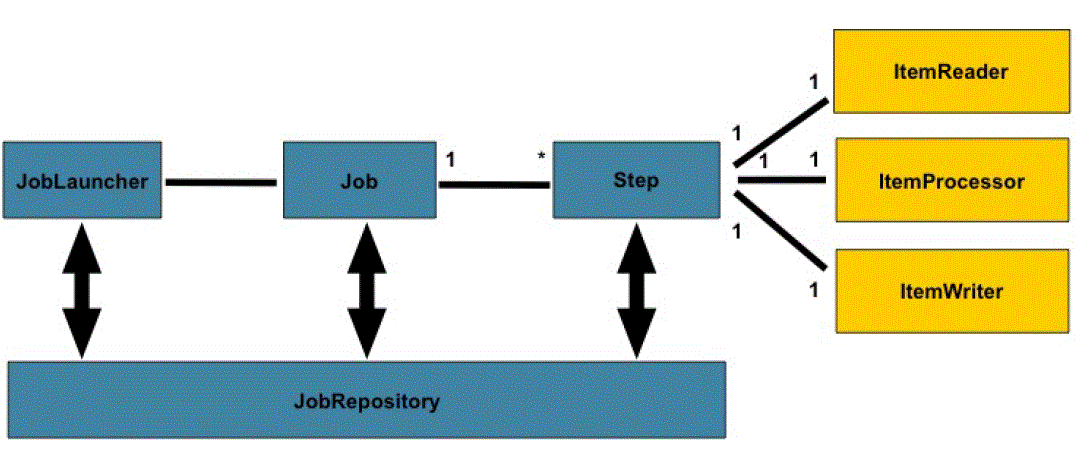
虽然Job对象看上去像是对于多个Step的一个简单容器,但是开发者必须要注意许多配置项。此外,Job的运行以及Job运行过程中元数据如何被保存也是需要考虑的。本章将会介绍Job在运行时所需要注意的各种配置项。
1.1 Configuring a Job
Job接口 的实现有多个,但是在配置上命名空间存在着不同。必须依赖的只有三项:名称 name,JobRespository 和 Step的列表:
<job id="footballJob">
<step id="playerload" parent="s1" next="gameLoad"/>
<step id="gameLoad" parent="s2" next="playerSummarization"/>
<step id="playerSummarization" parent="s3"/>
</job>在这个例子中使用了父类的bean定义来创建step,更多描述step配置的信息可以参考step configuration这一节。XML命名空间默认会使用id为'jobRepository'的引用来作为repository的定义。然而可以向如下显式的覆盖:
<job id="footballJob" job-repository="specialRepository">
<step id="playerload" parent="s1" next="gameLoad"/>
<step id="gameLoad" parent="s3" next="playerSummarization"/>
<step id="playerSummarization" parent="s3"/>
</job>
1.1.1 Restartablity
执行批处理任务的一个关键问题是要考虑job被重启后的行为。如果一个 JobExecution 已经存在一个特定的 JobInstance,那么这个job启动时可以认为是“重启”。 理想情况下,所有任务都能够在他们中止的地方启动,但是有许多场景这是不可能的。在这种场景中就要有开发者来决定创建一个新的 JobInstance ,Spring对此也提供了一些帮助。如果job不需要重启,而是总是作为新的 JobInstance 来运行,那么可重启属性可以设置为'false':
<job id="footballJob" restartable="false">
...
</job>
设置重启属性restartable为‘false’表示‘这个job不支持再次启动’,重启一个不可重启的job会抛出JobRestartExceptio的异常:
Job job = new SimpleJob();
job.setRestartable(false);
JobParameters jobParameters = new JobParameters();
JobExecution firstExecution = jobRepository.createJobExecution(job, jobParameters);
jobRepository.saveOrUpdate(firstExecution);
try {
jobRepository.createJobExecution(job, jobParameters);
fail();
} catch (JobRestartException e) {
//预计抛出JobRestartException异常
}
这个JUnit代码展示了创建一个不可重启的Job后,第一次能够创建 JobExecution ,第二次再创建相同的JobExcution会抛出一个 JobRestartException。
1.1.2 Intercepting Job Execution
在job执行过程中,自定义代码能够在生命周期中通过事件通知执行会是很有用的。SimpleJob能够在适当的时机调用JobListener:
public interface JobExecutionListener {
void beforeJob(JobExecution jobExecution);
void afterJob(JobExecution jobExecution);
}
<job id="footballJob">
<step id="playerload" parent="s1" next="gameLoad"/>
<step id="gameLoad" parent="s2" next="playerSummarization"/>
<step id="playerSummarization" parent="s3"/>
<listeners>
<listener ref="sampleListener"/>
</listeners>
</job>
无论job执行成功或是失败都会调用afterJob,都可以从 JobExecution 中获取运行结果后,根据结果来进行不同的处理:
public void afterJob(JobExecution jobExecution){
if( jobExecution.getStatus() == BatchStatus.COMPLETED ){
//job执行成功 }
else if(jobExecution.getStatus() == BatchStatus.FAILED){
//job执行失败 }
}
- @BeforeJob
- @AfterJob
1.1.3 Inheriting from a parent Job
下面的例子中,“baseJob”是一个抽象的job定义,只定义了一个监听器列表。名为“job1”的job是一个具体定义,它继承了“baseJob"的监听器,并且与自己的监听器合并,最终生成的job带有两个监听器,以及一个名为”step1“的step。
<job id="baseJob" abstract="true">
<listeners>
<listener ref="listenerOne"/>
</listeners>
</job>
<job id="job1" parent="baseJob">
<step id="step1" parent="standaloneStep"/>
<listeners merge="true">
<listener ref="listenerTwo"/>
</listeners>
</job>1.1.4 JobParametersValidator
<job id="job1" parent="baseJob3">
<step id="step1" parent="standaloneStep"/>
<validator ref="paremetersValidator"/>
</job>
1.2 Java Config
下, @EnableBatchProcessing 提供了构建批处理任务的基本配置。在这个基本的配置中,除了创建了一个 StepScope 的实例,还可以将一系列可用的bean进行自动装配:
- JobRepository bean 名称 "jobRepository"
- JobLauncher bean名称"jobLauncher"
- JobRegistry bean名称"jobRegistry"
- PlatformTransactionManager bean名称 "transactionManager"
- JobBuilderFactory bean名称"jobBuilders"
- StepBuilderFactory bean名称"stepBuilders"
注意 只有一个配置类需要有@ enablebatchprocessing注释。只要有一个类添加了这个注释,则以上所有的bean都是可以使用的。
在基本配置中,用户可以使用所提供的builder factory来配置一个job。下面的例子是通过 JobBuilderFactory 和
StepBuilderFactory 配置的两个step job 。
@Configuration
@EnableBatchProcessing
@Import(DataSourceCnfiguration.class)
public class AppConfig {
@Autowired
private JobBuilderFactory jobs;
@Autowired
private StepBuilderFactory steps;
@Bean
public Job job() {
return jobs.get("myJob").start(step1()).next(step2()).build();
}
@Bean
protected Step step1(ItemReader<Person> reader, ItemProcessor<Person, Person> processor, ItemWriter<Person> writer) {
return steps.get("step1")
.<Person, Person> chunk(10)
.reader(reader)
.processor(processor)
.writer(writer)
.build();
}
@Bean
protected Step step2(Tasklet tasklet) {
return steps.get("step2")
.tasklet(tasklet)
.build();
}
}1.3 Configuring a JobRepository
<job-repository id="jobRepository" data-source="dataSource"
transaction-manager="transactionManager"
isolation-level-for-create="SERIALIZABLE"
table-prefix="BATCH_"
max-varchar-length="1000"/>1.3.1 JobRepository 的事物配置
<job-repository id="jobRepository" isolation-level-for-create="REPEATABLE_READ" /><aop:config>
<aop:advisor pointcut="execution(* org.springframework.batch.core..*Repository+.*(..))"/>
<advice-ref="txAdvice" />
</aop:config>
<tx:advice id="txAdvice" transaction-manager="transactionManager">
<tx:attributes>
<tx:method name="*" />
</tx:attributes>
</tx:advice>
1.3.2 修改 Table 前缀
BATCH_STEP_EXECUTION 就是两个例子。但是,有一些潜在的原因可能需要修改这个前缀。例如schema的名字需要被预置到表名中,或是不止一组的元数据表需要放在同一个schema中,那么表前缀就需要改变:
<job-repository id="jobRepository" table-prefix="SYSTEM.TEST_" />注意:表名前缀是可配置的,表名和列名是不可配置的。
1.3.3 In-Memory Repository
<bean id="jobRepository"
class="org.springframework.batch.core.repository.support.MapJobRepositoryFactoryBean">
<property name="transactionManager" ref="transactionManager"/>
</bean>但是也需要定义一个事务管理器,因为仓库需要回滚语义,也因为商业逻辑要求事务性(例如RDBMS访问)。经过测试许多人觉得 ResourcelessTransactionManager 是很有用的。
1.3.4 Non-standard Database Types in a Repository
<bean id="jobRepository" class="org...JobRepositoryFactoryBean">
<property name="databaseType" value="db2"/>
<property name="dataSource" ref="dataSource"/>
</bean>
1.4 Configuring a JobLauncher
<bean id="jobLauncher"
class="org.springframework.batch.core.launch.support.SimpleJobLauncher">
<property name="jobRepository" ref="jobRepository" />
</bean>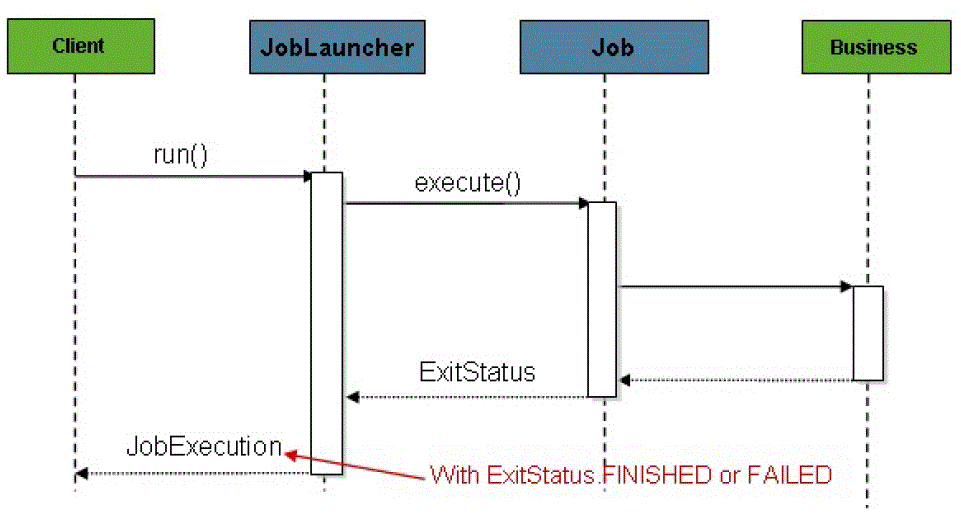
<bean id="jobLauncher"
class="org.springframework.batch.core.launch.support.SimpleJobLauncher">
<property name="jobRepository" ref="jobRepository" />
<property name="taskExecutor">
<bean class="org.springframework.core.task.SimpleAsyncTaskExecutor" />
</property>
</bean>
1.5 Running a Job
1.5.1 在 Web Container 内部运行 Jobs
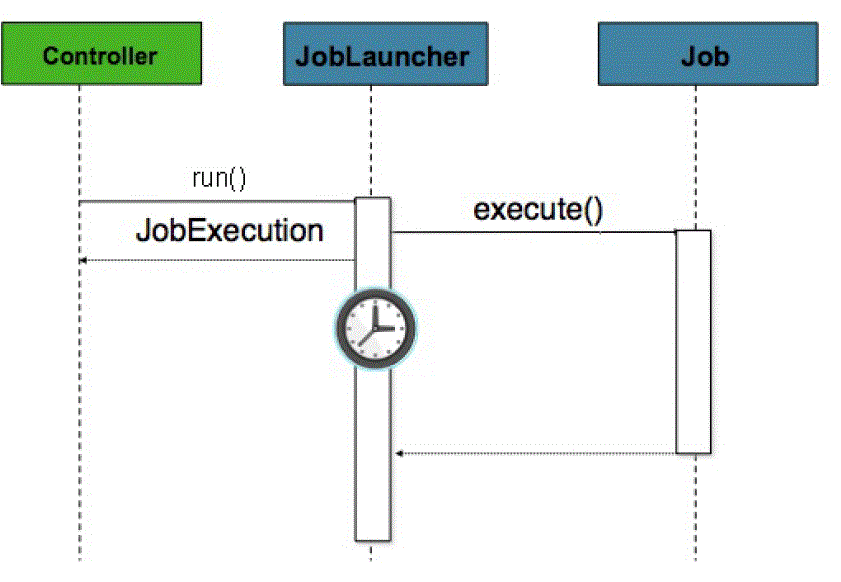
@Controller
public class JobLauncherController {
@Autowired
JobLauncher jobLauncher;
@Autowired
Job job;
@RequestMapping("/jobLauncher.html")
public void handle() throws Exception{
jobLauncher.run(job, new JobParameters());
}
}1.6 Meta-Data 高级用法
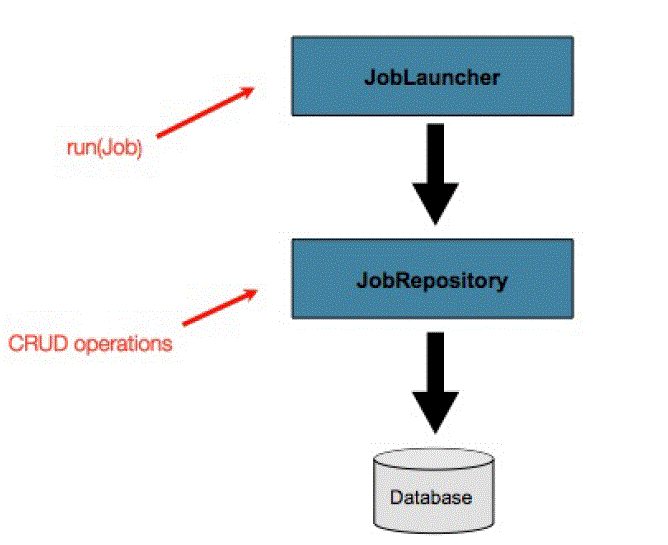
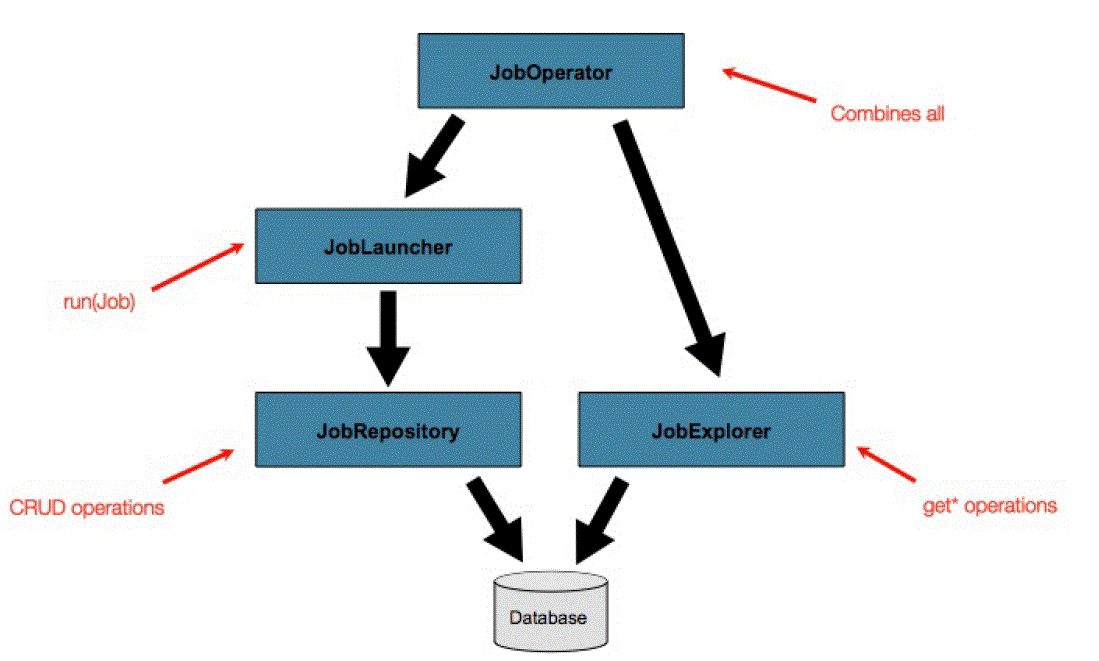
1.6.1 Querying the Repository
public interface JobExplorer {
List<JobInstance> getJobInstances(String jobName, int start, int count);
JobExecution getJobExecution(Long executionId);
StepExecution getStepExecution(Long jobExecutionId, Long stepExecutionId);
JobInstance getJobInstance(Long instanceId);
List<JobExecution> getJobExecutions(JobInstance jobInstance);
Set<JobExecution> findRunningJobExecutions(String jobName);
}<bean id="jobExplorer" class="org.spr...JobExplorerFactoryBean"
p:dataSource-ref="dataSource" /><bean id="jobExplorer" class="org.spr...JobExplorerFactoryBean"
p:dataSource-ref="dataSource" p:tablePrefix="BATCH_" />1.6.2 JobRegistry
<bean id="jobRegistry" class="org.spr...MapJobRegistry" />JobRegistryBeanPostProcessor
<bean id="jobRegistryBeanPostProcessor" class="org.spr...JobRegistryBeanPostProcessor">
<property name="jobRegistry" ref="jobRegistry"/>
</bean>并不一定要像例子中给post处理器一个id,但是使用id可以在子context中(比如作为作为父 bean 定义)也使用post处理器,这样所有的job在创建时都会自动注册进JobRegistry。
AutomaticJobRegistrar
<bean class="org.spr...AutomaticJobRegistrar">
<property name="applicationContextFactories">
<bean class="org.spr...ClasspathXmlApplicationContextsFactoryBean">
<property name="resources" value="classpath*:/config/job*.xml" />
</bean>
</property>
<property name="jobLoader">
<bean class="org.spr...DefaultJobLoader">
<property name="jobRegistry" ref="jobRegistry" />
</bean>
</property>
</bean>ClassPathXmlApplicationContextFactory。这个工厂类的一个特性是默认情况下他会复制父上下文的一些配置到子上下文。因此如果不变的情况下不需要重新定义子上下文中的 PropertyPlaceholderConfigurer 和AOP配置。
在必要情况下,AutomaticJobRegistrar 可以和 JobRegistyBeanPostProcessor 一起使用。例如,job有可能既定义在父上下文中也定义在子上下文中的情况。
1.6.3 JobOperator
public interface JobOperator {
List<Long> getExecutions(long instanceId) throws NoSuchJobInstanceException;
List<Long> getJobInstances(String jobName, int start, int count)throws NoSuchJobException;
Set<Long> getRunningExecutions(String jobName) throws NoSuchJobException;
String getParameters(long executionId) throws NoSuchJobExecutionException;
Long start(String jobName, String parameters)throws NoSuchJobException, JobInstanceAlreadyExistsException;
Long restart(long executionId)throws JobInstanceAlreadyCompleteException, NoSuchJobExecutionException,
NoSuchJobException, JobRestartException;
Long startNextInstance(String jobName)throws NoSuchJobException, JobParametersNotFoundException, JobRestartException,
JobExecutionAlreadyRunningException, JobInstanceAlreadyCompleteException;
boolean stop(long executionId)throws NoSuchJobExecutionException, JobExecutionNotRunningException;
String getSummary(long executionId) throws NoSuchJobExecutionException;Map<Long, String> getStepExecutionSummaries(long executionId)
throws NoSuchJobExecutionException;
Set<String> getJobNames();
}<bean id="jobOperator" class="org.spr...SimpleJobOperator">
<property name="jobExplorer">
<bean class="org.spr...JobExplorerFactoryBean">
<property name="dataSource" ref="dataSource" />
</bean>
</property>
<property name="jobRepository" ref="jobRepository" />
<property name="jobRegistry" ref="jobRegistry" />
<property name="jobLauncher" ref="jobLauncher" />
</bean>1.6.4 JobParametersIncrementer
startNextInstance方法却有些无所是处。这个方法通常用于启动Job的一个新的实例。但如果 JobExecution 存在若干严重的问题,同时该Job 需要从头重新启动,那么这时候这个方法就相当有用了。不像JobLauncher ,启动新的任务时如果参数不同于任何以往的参数集,这就要求一个新的 JobParameters 对象来触发新的 JobInstance,startNextInstance 方法将使用当前的JobParametersIncrementer绑定到这个任务,并强制其生成新的实例:
public interface JobParametersIncrementer {
JobParameters getNext(JobParameters parameters);
}public class SampleIncrementer implements JobParametersIncrementer {
public JobParameters getNext(JobParameters parameters) {
if (parameters==null || parameters.isEmpty()) {
return new JobParametersBuilder().addLong("run.id", 1L).toJobParameters();
}
long id = parameters.getLong("run.id",1L) + 1;
return new JobParametersBuilder().addLong("run.id", id).toJobParameters();
}
}<job id="footballJob" incrementer="sampleIncrementer"> ...
</job>1.6.5 Stopping a Job
Set<Long> executions = jobOperator.getRunningExecutions("sampleJob");
jobOperator.stop(executions.iterator().next());













 432
432











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









