









1.首先要有虚拟机(vmware 这是一个虚拟机安装软件,然后下载cenos操作系统,centos是linux社区办的一个流行的操作系统,还有Redhat 商业版的,安全还提供一些额外的服务,但是要收费,还有对虚拟机的硬件和软件进行配置,在VMware这个图形化的工具里面就可以进行配置)或者是购买阿里的ecs服务器,下载cenos公共镜像(有免费的为啥不用这个呢)。
2.连接远程服务器和对远程服务器的管理用xhell(功能强大)或者是putty(小巧),因为要设计到一些文件传输到远程,所以这里推荐flashftp 或者是xftp(xhell推荐使用,xftp集成到xhell)
3.后台java项目的部署https://www.renren.io/ renren-fast
下载后台java 的源码,然后下载eclips编辑器,因为这个项目是用springboot来开发的,springboot用了mevan,所以要下载meavn (一个java项目的管理工具,在导入meavn项目的时候回下载jarl类,也方便发布)然后镜像修改成阿里的镜像(修改方法自行百度,其实只是在cnof加几行代码就行了),然后在编辑器里面配置好maven,然后导入已经存在的maven项目
下载navicat ,在安装的时候如果报错10038 ,那是因为mysql没有启动,navicat 只是一个mysql的图形化管理页面,前提还是得有mysql,所以还得下载mysql。
4.前台项目的部署
5.linux 目录和命令的学习 我的其他的文章
6.防火墙管理, centos 自带firewalld 防火墙,命令如下

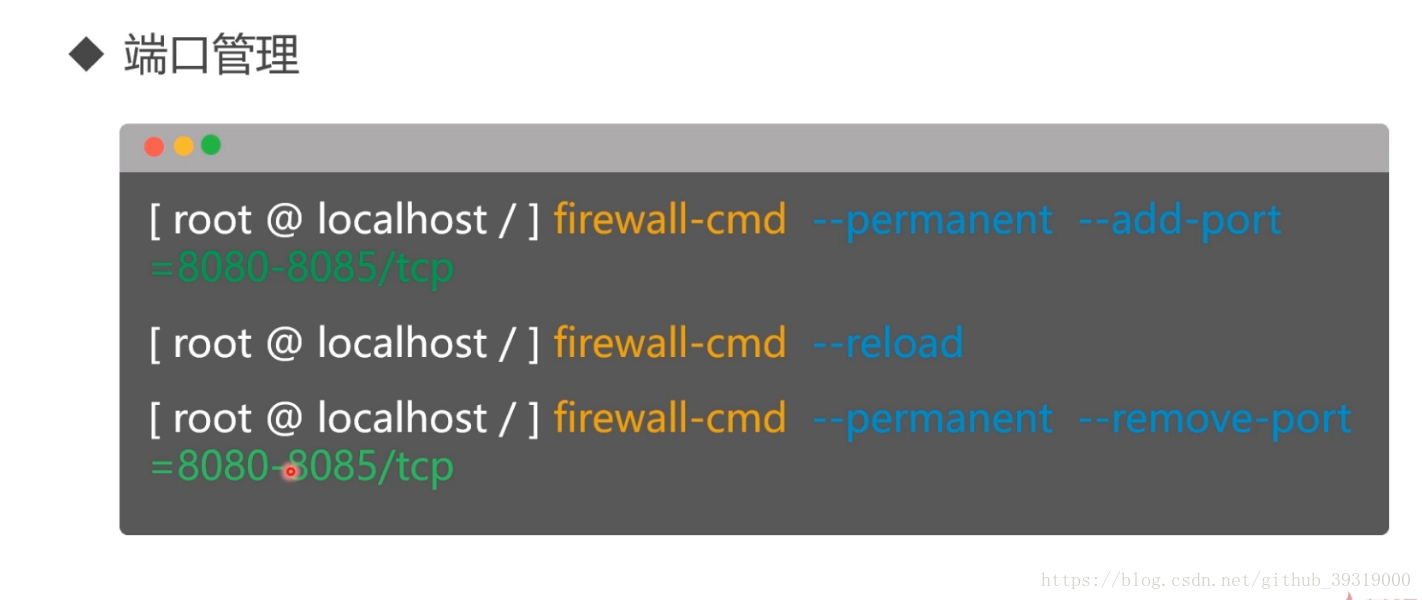
查看防火墙开启的端口号是 firewall-cmd --permanent --list-ports
查看有哪些服务通过防火墙连接了互联网 firewall-cmd --permanent --list-services
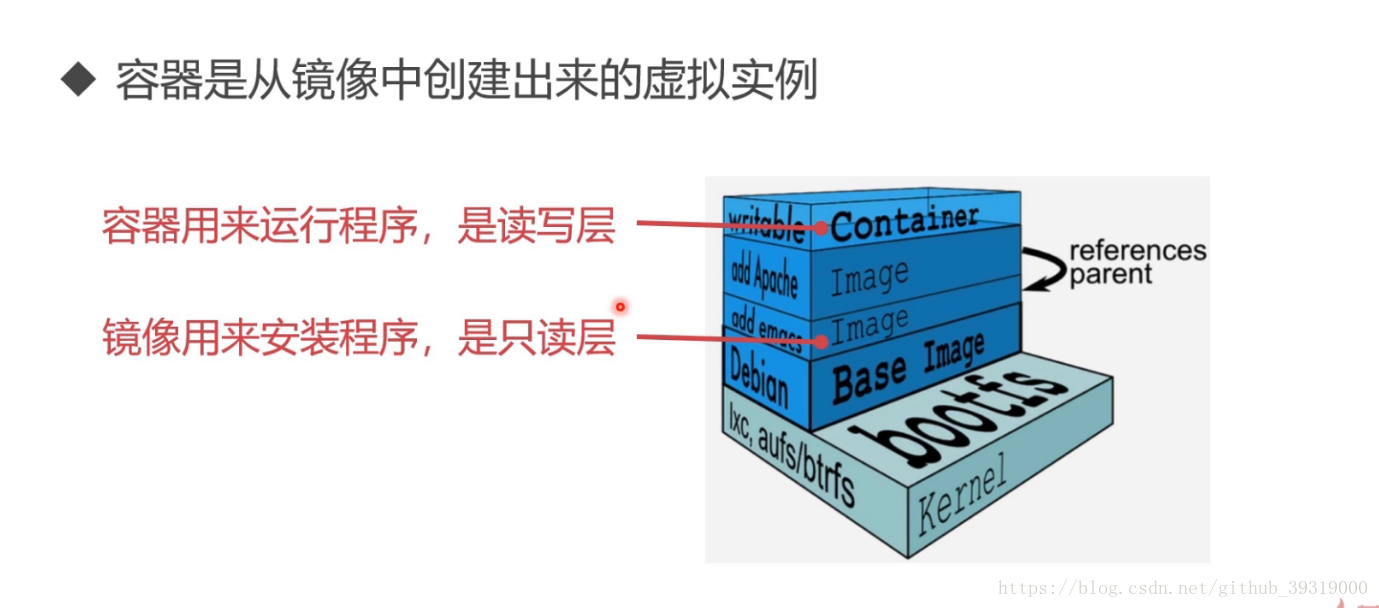
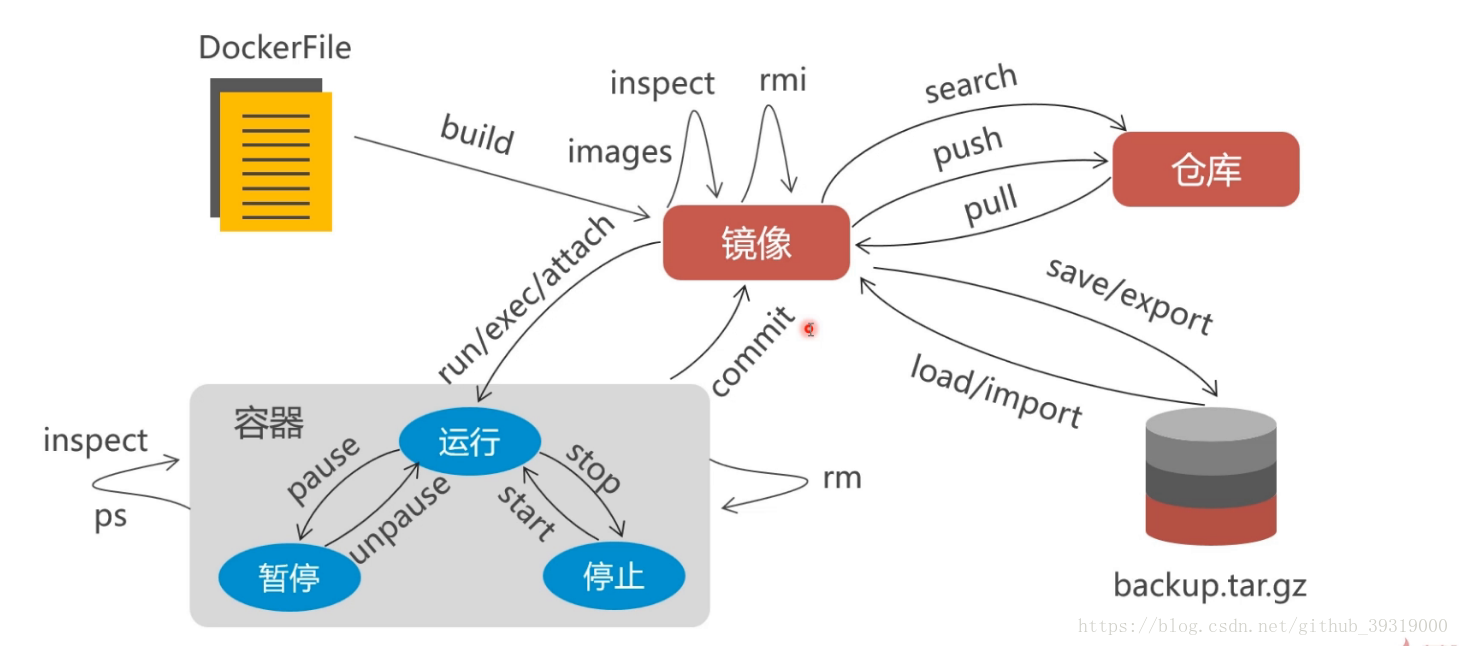
7. docker 学习 镜像是可读不可写的,实际存在的,容器是虚拟的,可读可写的
这里有片腾讯课堂的文章讲的比较详细 https://ke.qq.com/course/303636



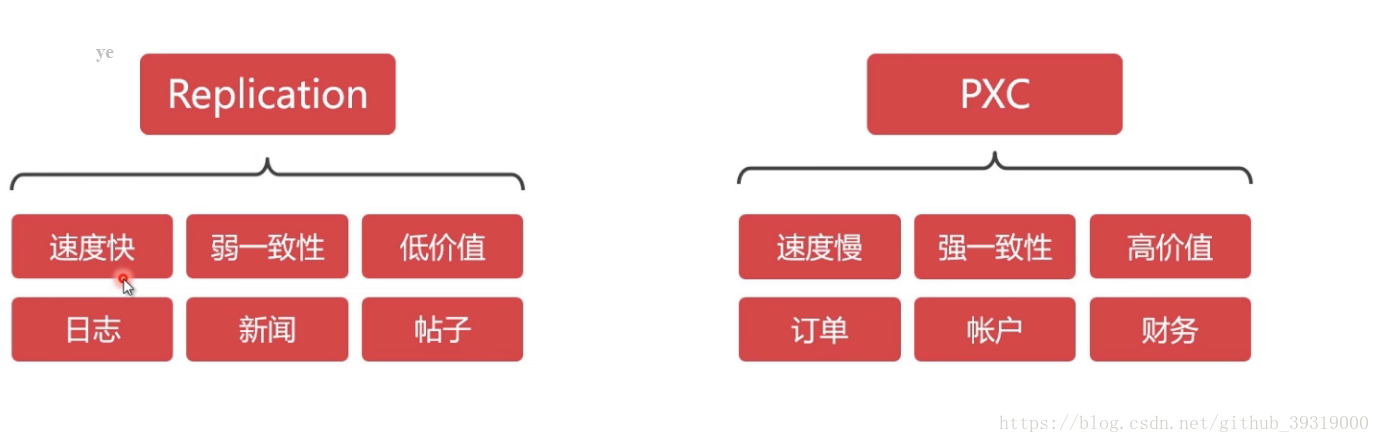
7. mysql 集群方案介绍,建议使用pxc,因为弱一致性会有问题,比如说a节点数据库显示我购买成功,b 节点数据库显示没有成功,这就麻烦了,pxc 方案是在全部节点都写入成功之后才会告诉你成功,是可读可写双向同步的,但是replication是单向的,不同节点的数据库之间都会开放端口进行通讯,如果从防火墙的这个端口关闭,pxc就不会同步成功,也不会返给你成功了。
8.创建mysql集群
1.因为我们采用的是pxc方案,所以要在docker的官方仓库下载pxc方案的镜像
2.由上面我们知道各节点之间在通讯的时候时候内部端口的,首先我们要创建内部网段,并且分配具体的ip。
3.创建数据卷,容器中的数据不要放在容器中而是放在宿主机上,这样当容器出现问题的时候,可以删除容器,重新创建。
(数据卷 如果用的是pxc技术的话,创建数据卷的时候不能单纯的使用文件夹的映射,否则会闪退,必须得用volume技术)
3.运行pxc镜像,(运行完后产生的是数据库的实例,用数据库连接宿主机的ip的分配的端口号就可以进行连接)输入各种参数产生数据库节点 还有之前创建了网段现在分配一个给这个节点进行通讯,然后登陆数据库进行连接。到此完成mysql集群。

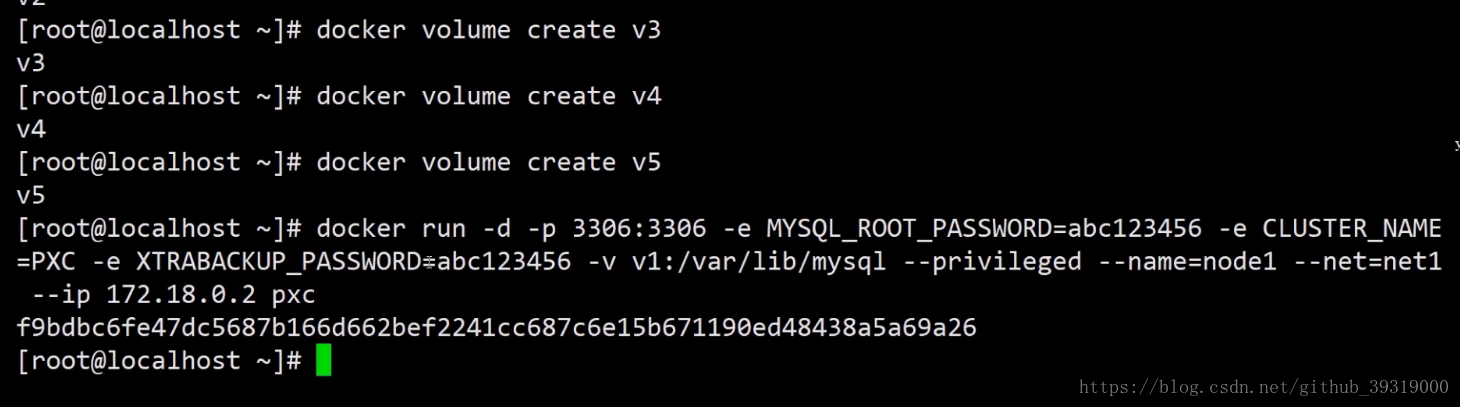
9.mysql 数据库的负载均衡(相当于请求转发器)
负载均衡首先是数据库的集群,加入5个集群,每次请求都是第一个的话,有可能第一个数据库就挂掉了,所以更优的方案是对不同的节点都进行请求,这就需要有中间件进行转发,比较好的中间件有nginx,haproxy等,因nginx 支持插件,但是刚刚支持了tcp/ip 协议,haproxy 是一个老牌的中间转发件。如果要用haproxy的话,可以从官方下载镜像,然后呢对镜像进行配置(自己写好配置文件,因为这个镜像是没有配置文件的,配置好之后再运行镜像的时候进行文件夹的映射,配置文件开放3306(数据库请求,然后根据check心跳检测访问不同的数据库,8888 对数据库集群进行监控))。配置文件里面设置用户(用户在数据库进行心跳检测,判断哪个数据库节点是空闲的,然后对空闲的进行访问),还有各种算法(比如轮训),最大连接数,时间等,还有对集群的监控。配置文件写好以后运行这个镜像,镜像运行成功后进入容器启动配置文件 。其实haprocy返回的也是一个数据库实例(但是并不存储任何的数据,只是转发请求),这个实例用来check其他节点。最好生成至少两个这样的实例。当一个挂掉的时候,另外 一个可以顶上(这就是双机热备见10)。
10.双机热备
双机就是两个请求处理程序,比如两个haproxy,当一个挂掉的时候,另外 一个可以顶上。热备我理解就是keepalive。在haproxy 容器中安装keepalive。
关键就是虚拟ip,定义一个虚拟ip,然后比如两个haproxy分别安装keepalive镜像,因为haproxy是ubuntu系统的,所以安装用apt-get,keepalive是作用是抢占虚拟ip,抢到的就是主服务器,没有抢到的就是备用服务器,然后两个keepalive进行心跳检测(就是创建一个用户到对方那里试探,看是否还活着,mysql的集群之间也是心跳检测),如果 挂掉抢占ip。所以在启动keepalive 之前首先要编辑好他的配置文件,怎么抢占,权重是什么,虚拟ip是什么,创建的用户交什么。配置完启动完以后可以ping一下看是否正确.
然后将虚拟ip映射到局域网的ip
11.热备份数据
1.冷备份 导出数据库进行备份,但是数据库需要停机,影响业务
2.热备份
全量备份:整个都备份 增量备份:对变化的数据进行备份 。
方案:lvm 和xtrabackup lvm 需要对数据库进行加锁(锁表),只能读取数据不能写入数据。
具体方法:利用mysql集群的技术,暂停删除一个节点镜像,新建一个节点进行备份(先要创造一个数据卷用来映射容器中备份的数据),然后下载xtrabackup 进行备份。
备份数据进行恢复

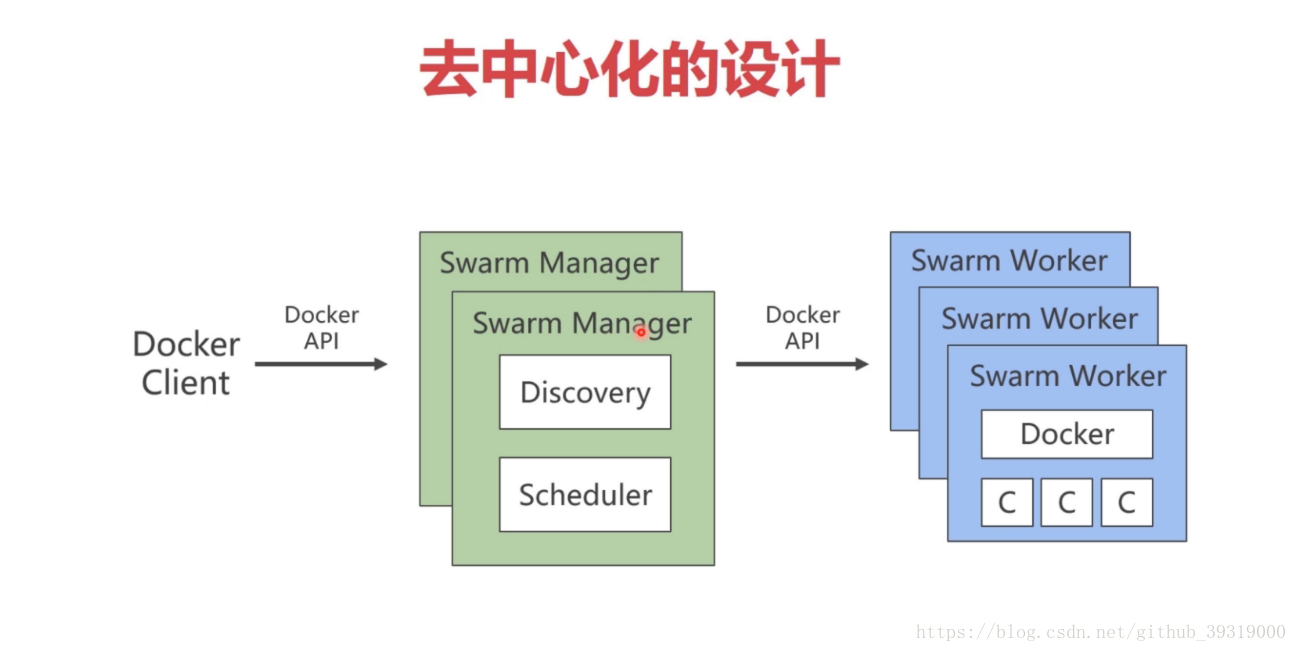
12.docker swarm技术(之前的docker集群都是在 一个虚拟主机上的,但是如果这个主机挂掉了over了,docker技术就是多个虚拟主机形成一个集群)
13.云端部署
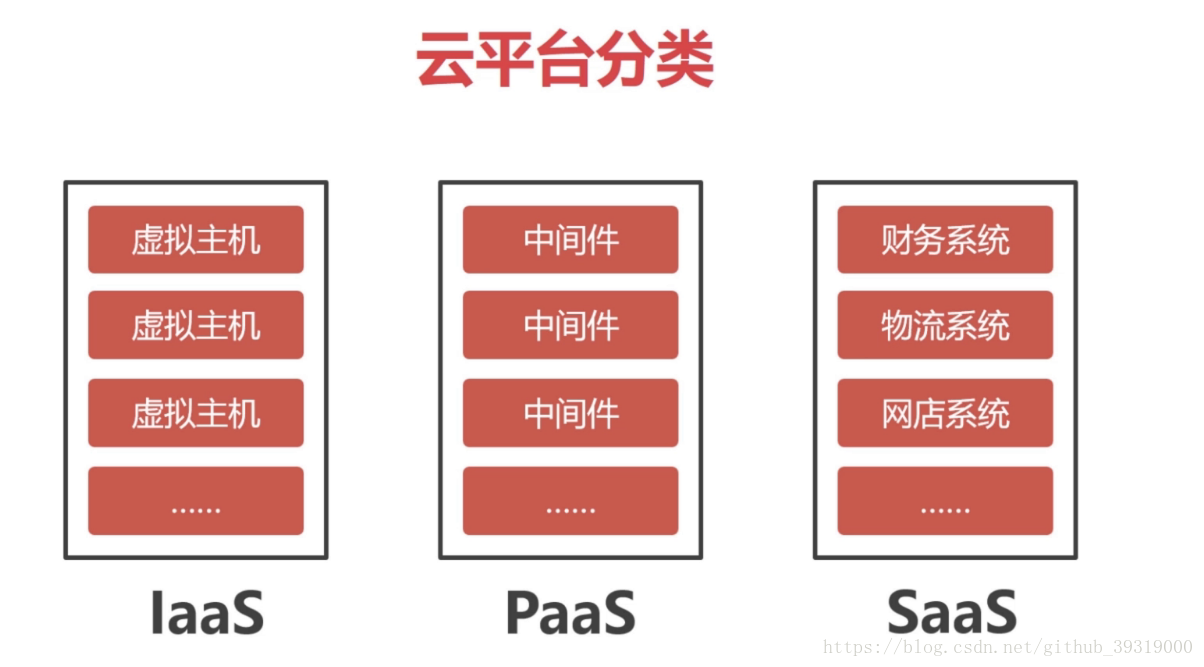
百度云倾向谷歌的方案做的是paas 云和saas云,比如百度的bae(baidu application engine)就是paas 。bcc(Baidu Cloud Compute)我理解就是laas
腾讯的优势是社交,可以在中间件挖掘很多的社交数据,paas
阿里倾向于亚马孙的的方案,平成的交易量和双11相比有很大的闲置资源,所以将闲置资源出租,laas云
在云平台搭建数据库集群的几种方式:
1.购买一个配置较高的云主机,在云主机内搭建docker pxc 数据库集群。
2.购买几个配置较低的云主机,用docker swarm技术组件集权
3.第三种就是将以上两种结合起来,如果一个云主机挂掉还有其他的云主机。














 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









