






转载自学术头条
一个月前,OpenAI 总裁 Greg Brockman 向世人展示了 GPT-4 令人惊讶的多模态能力,如从手写文本直接生成网站和识别图像中的幽默元素等。
尽管目前 OpenAI 暂未对 GPT-4 用户开放这一能力,但具有多模态能力的视觉语言模型令人充满了想象力。
近日,来自阿卜杜拉国王科技大学的研究团队,便提出了一个具有类似 GPT-4 图像理解与对话能力的 AI 大模型——MiniGPT-4,并将其开源 。
。
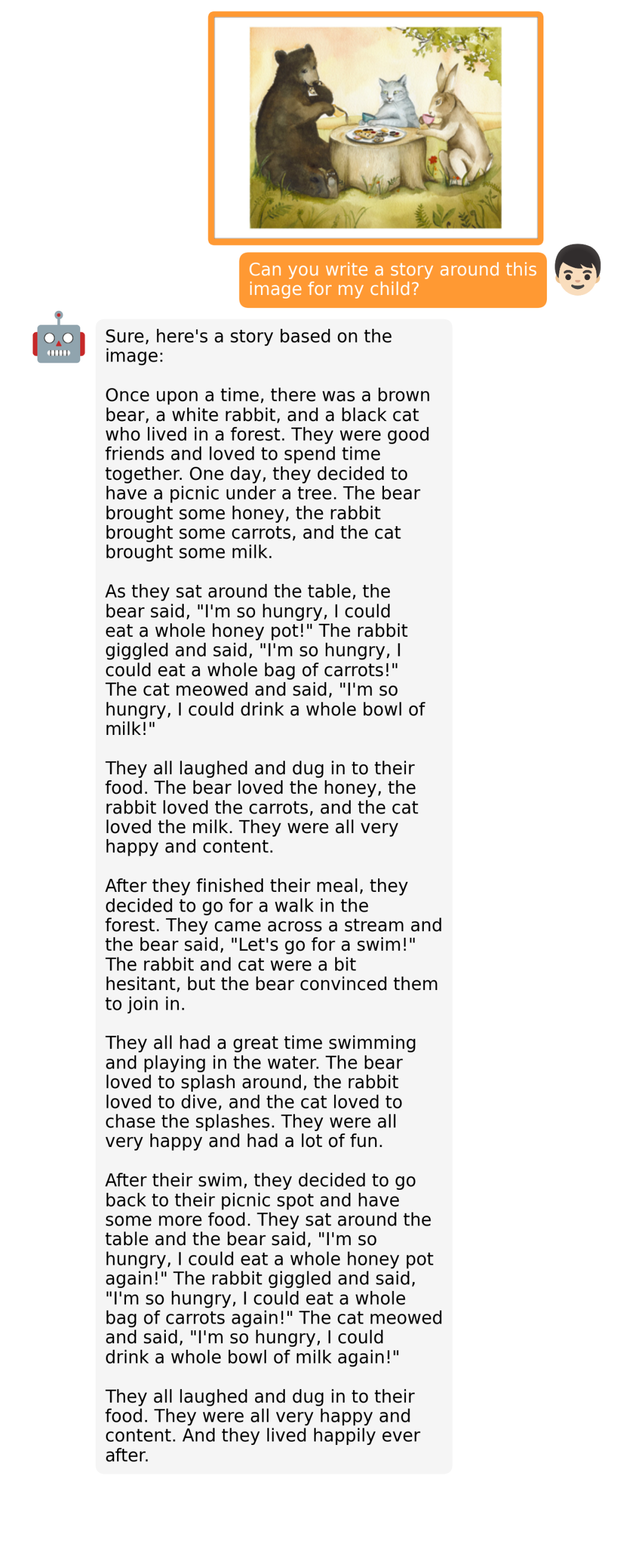
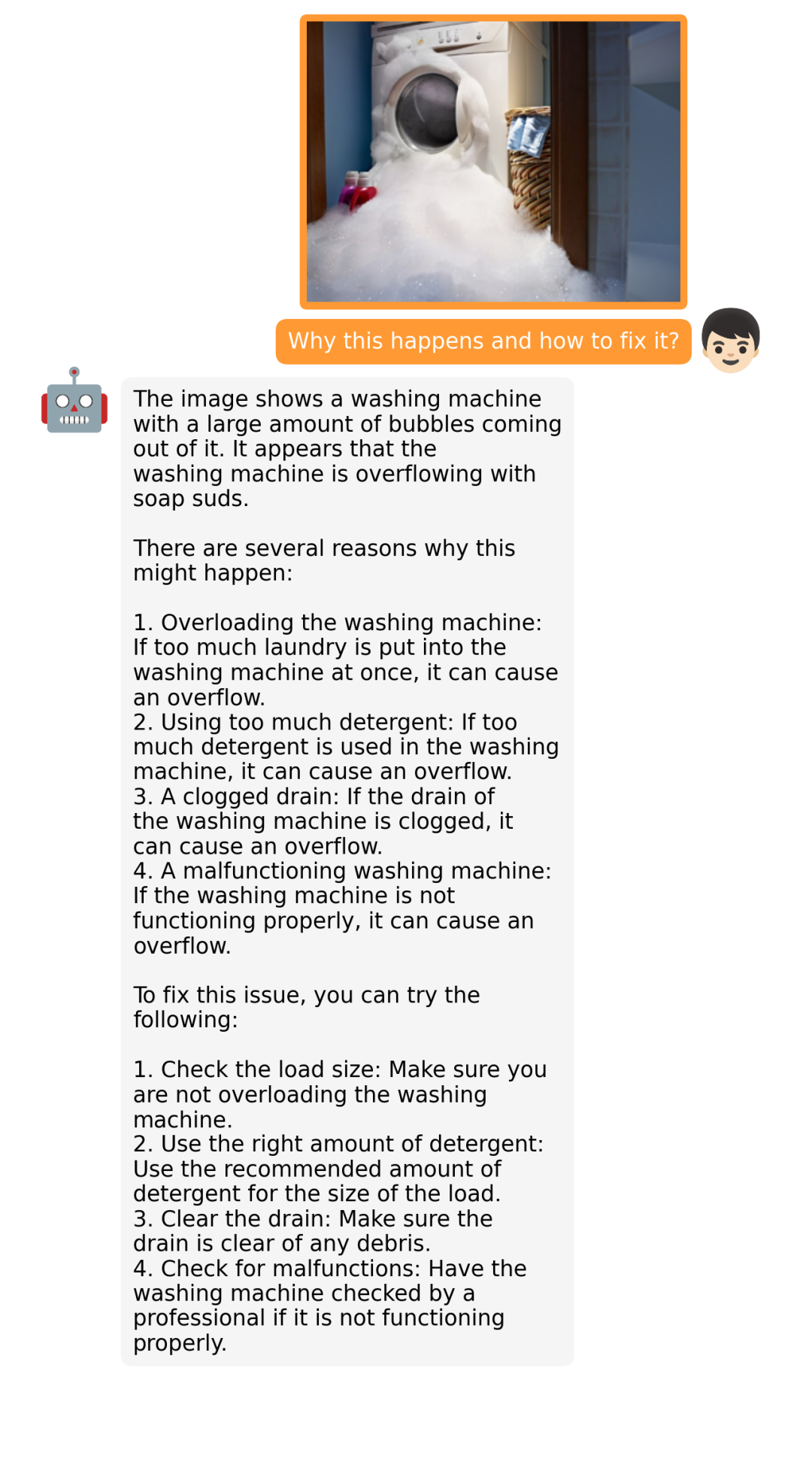
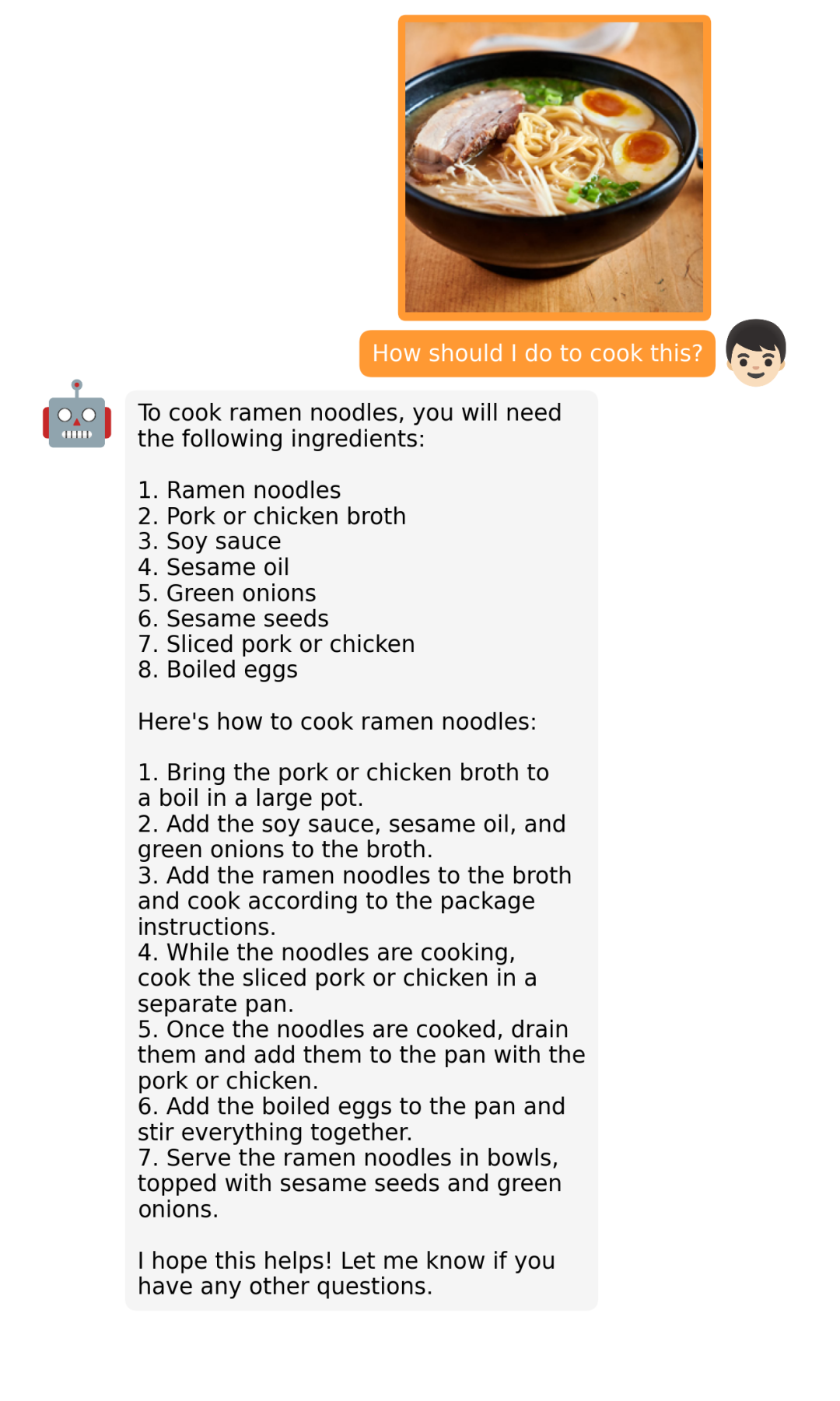
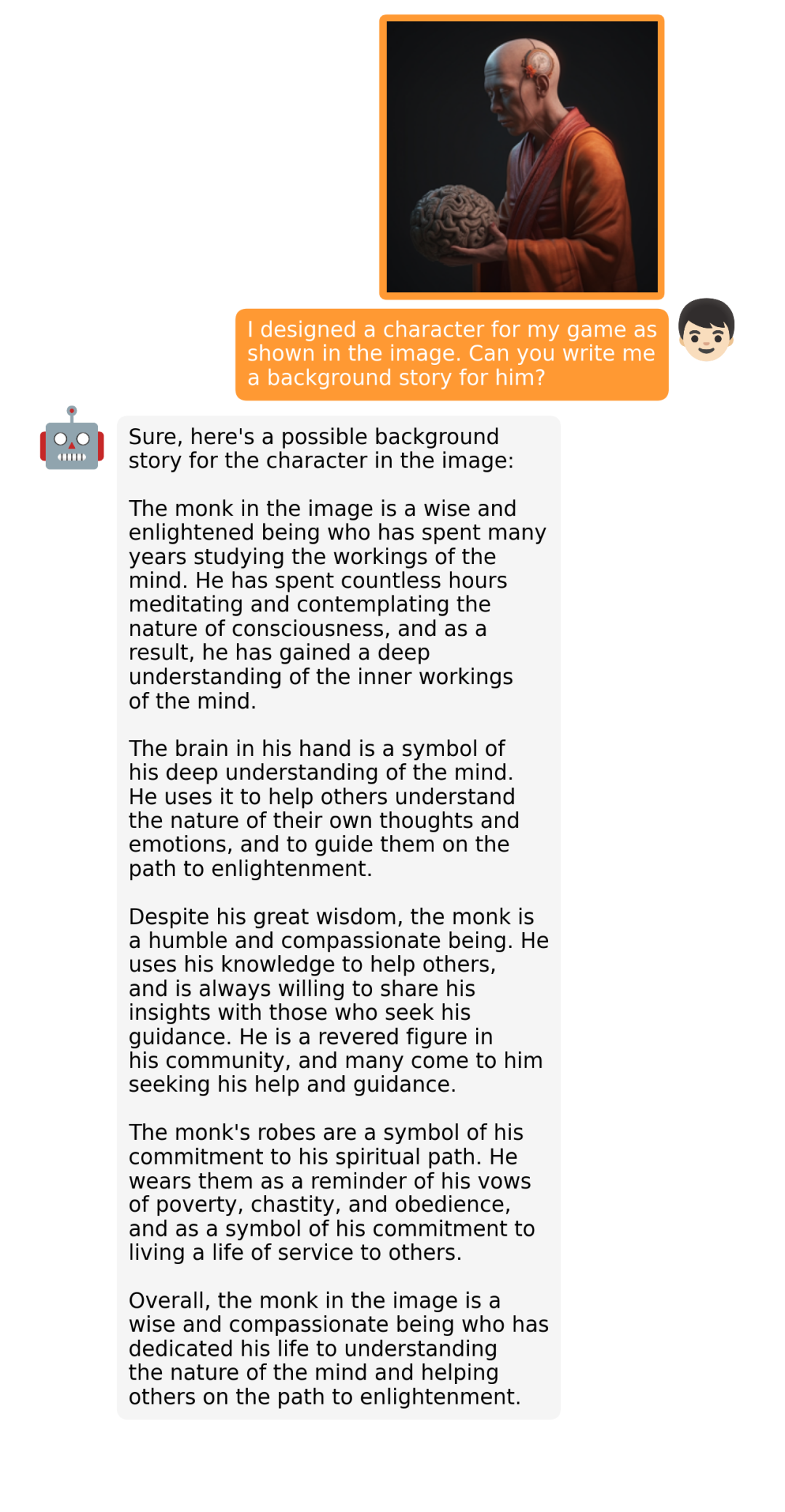
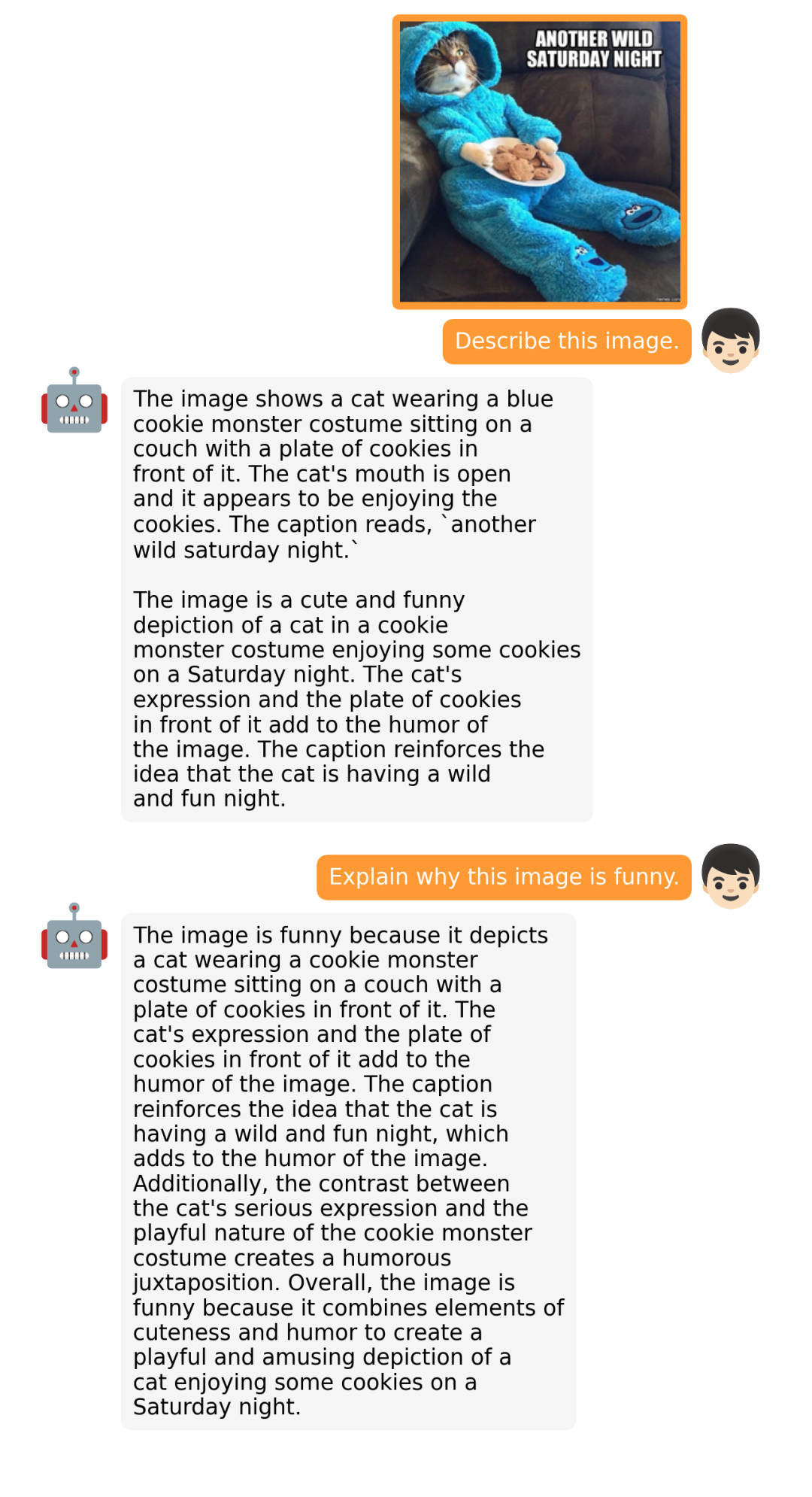
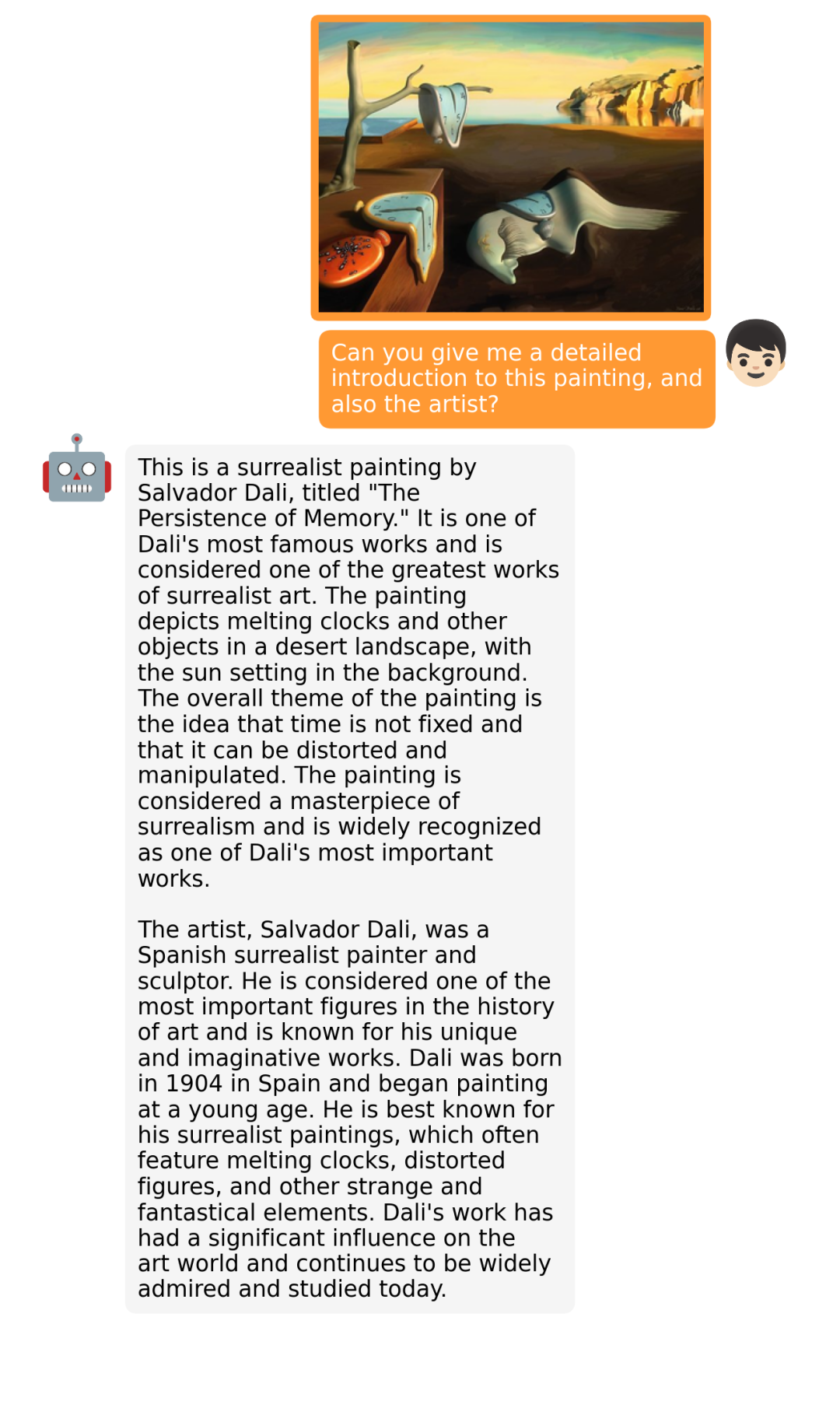
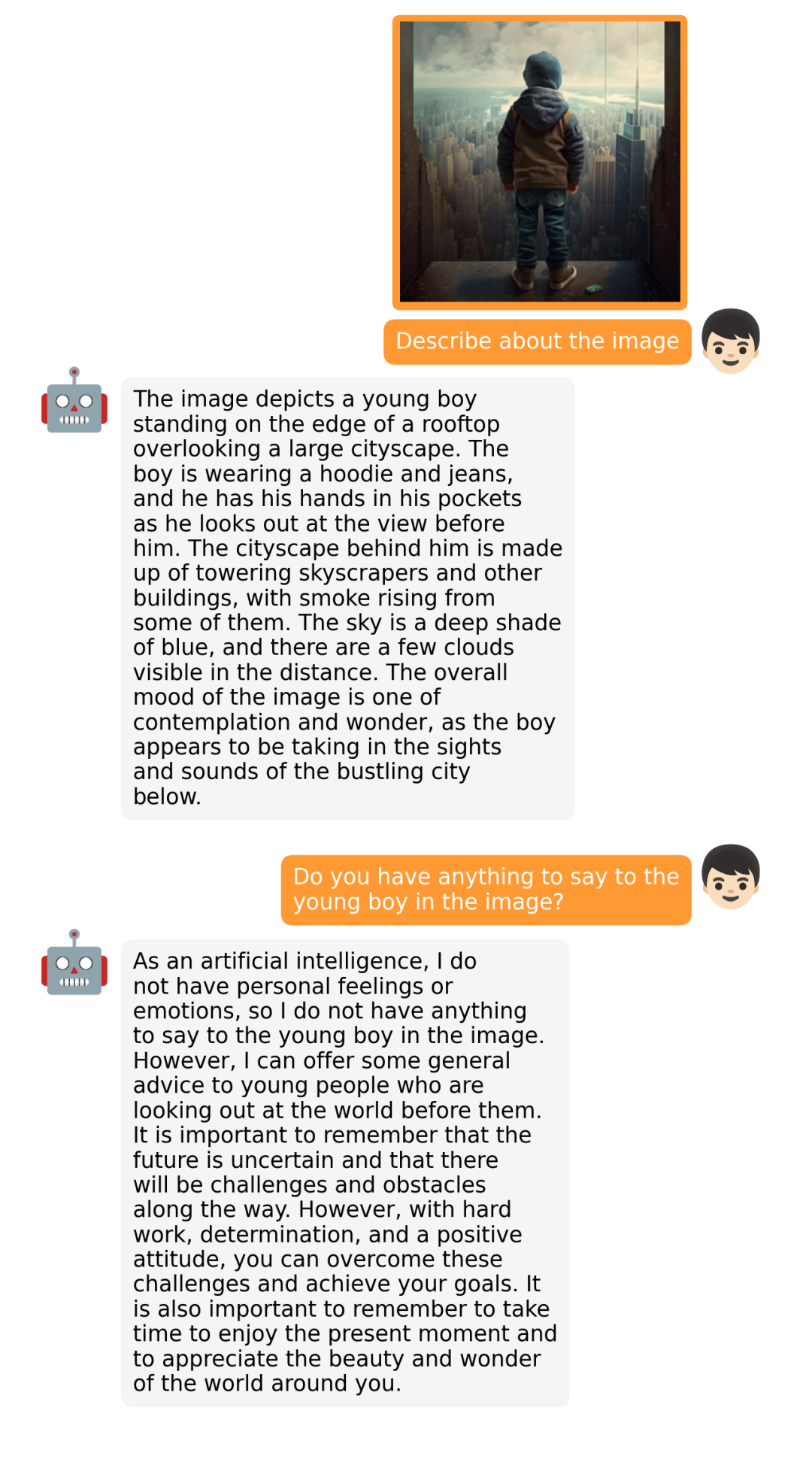
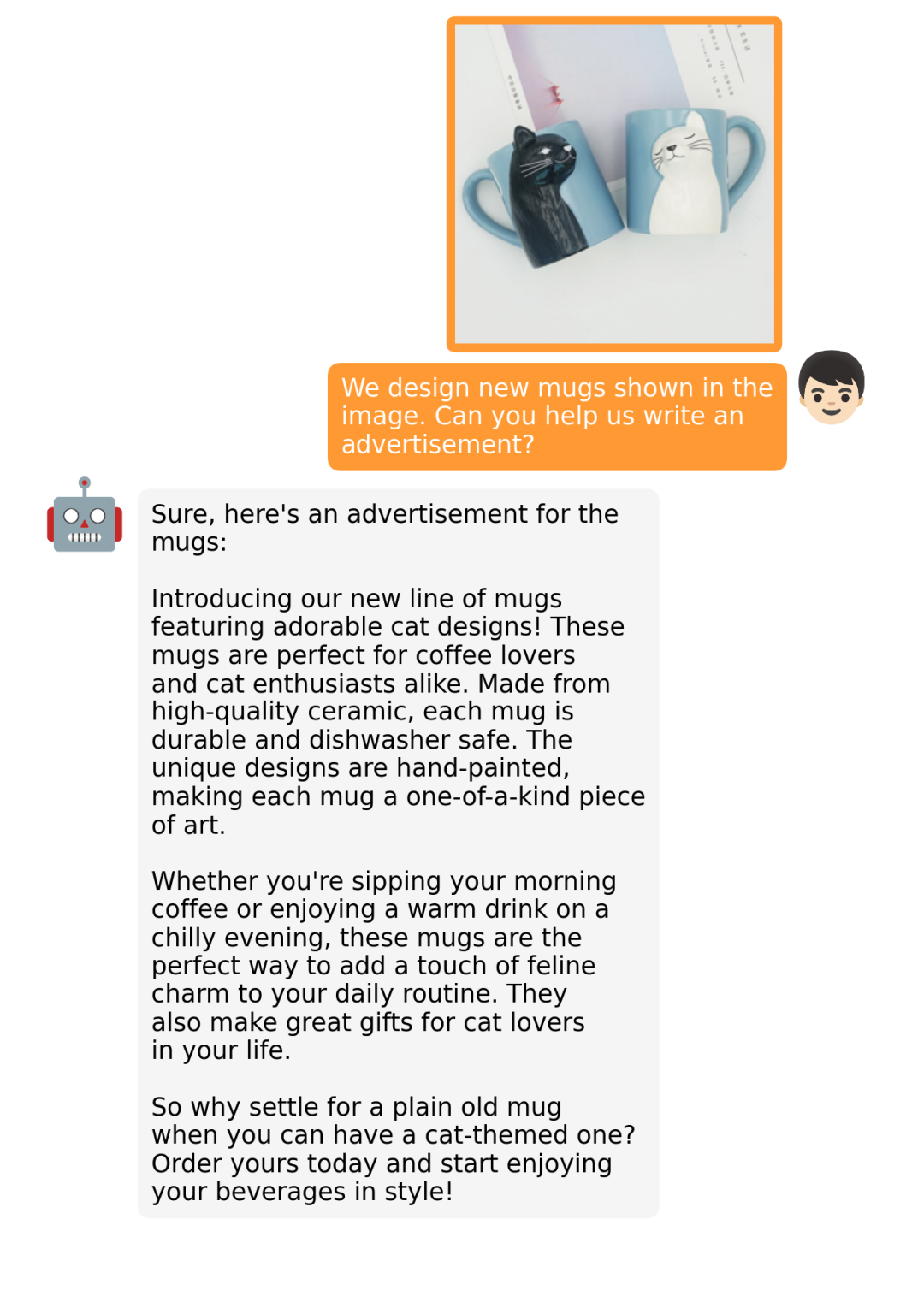
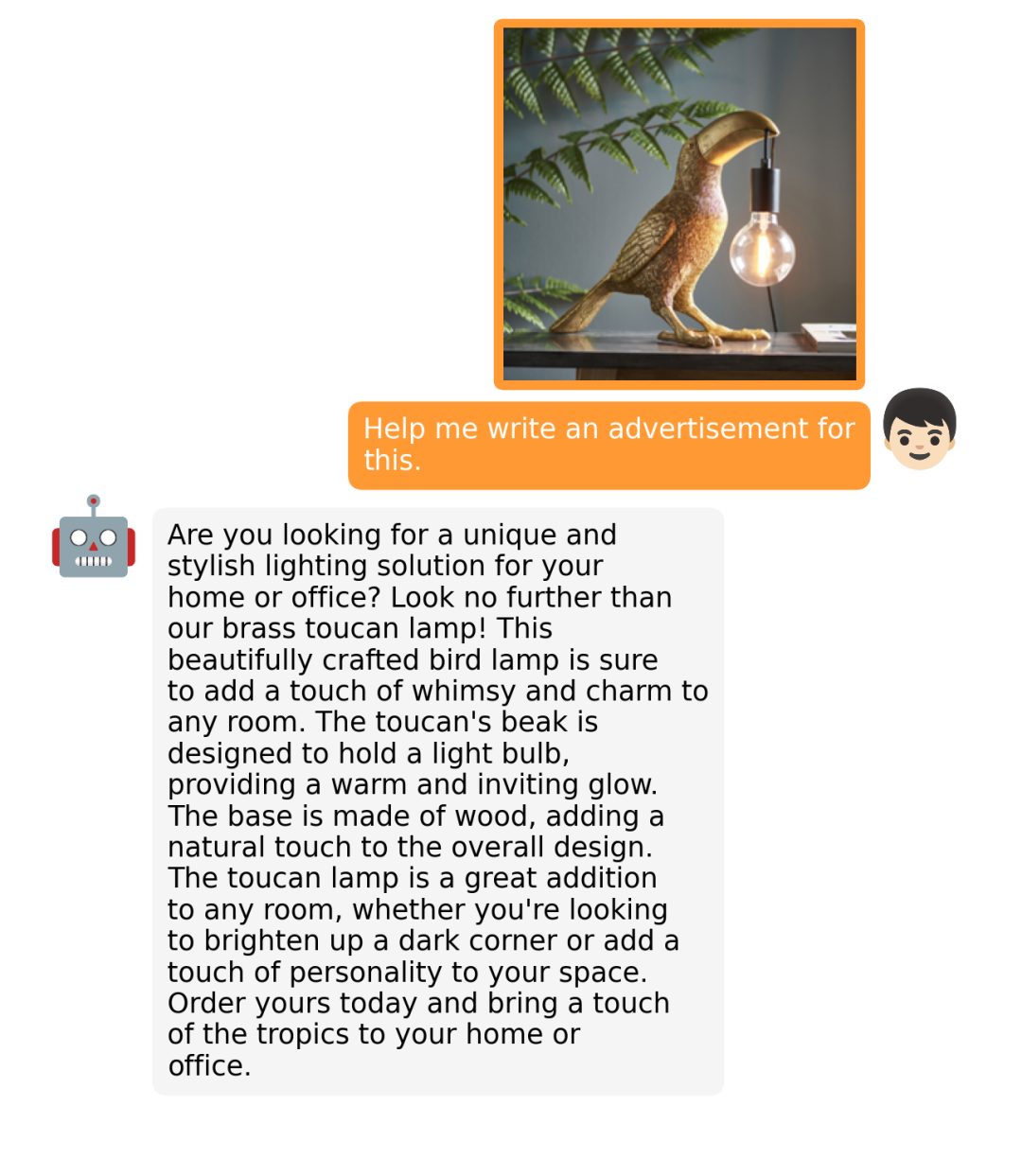
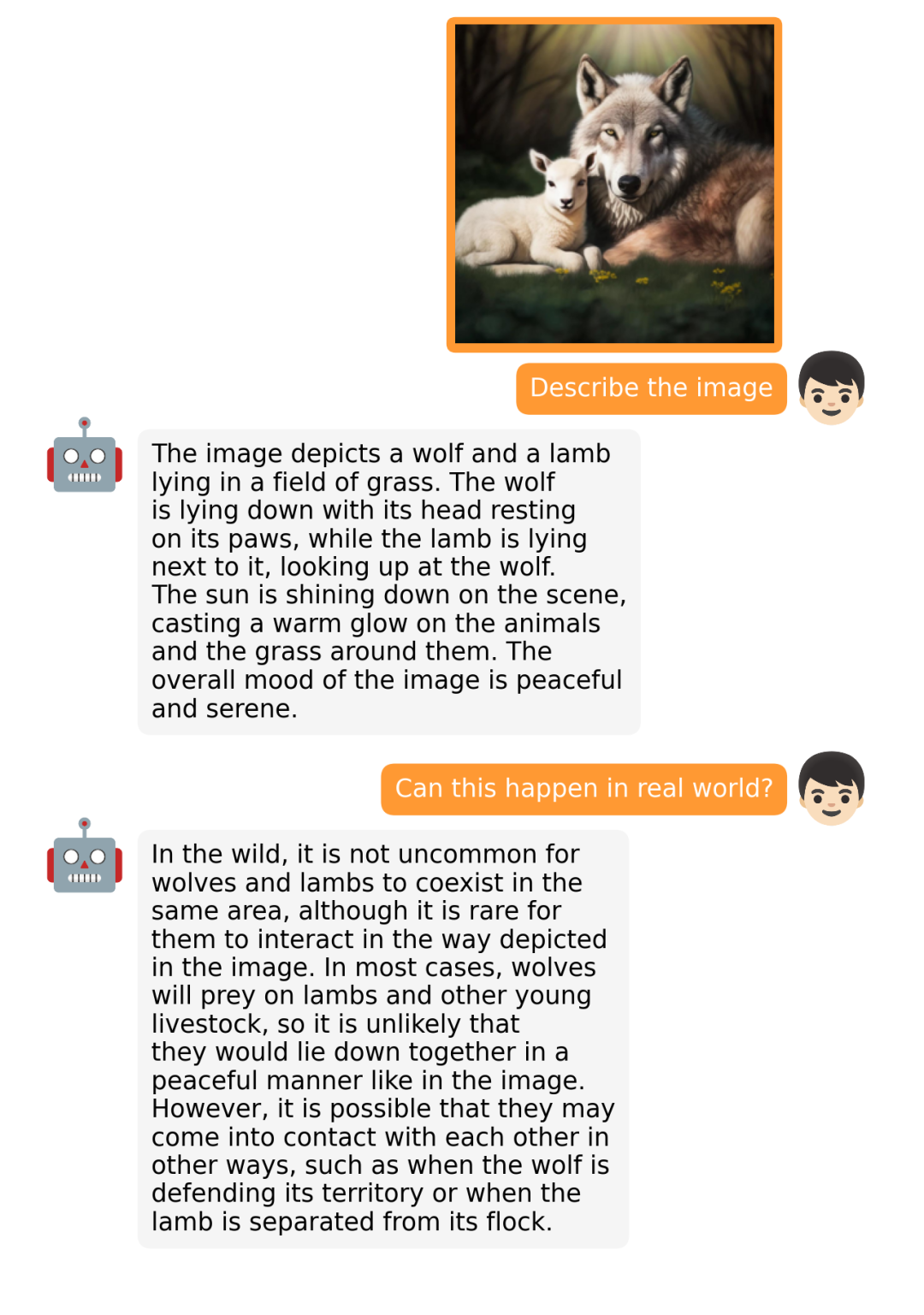
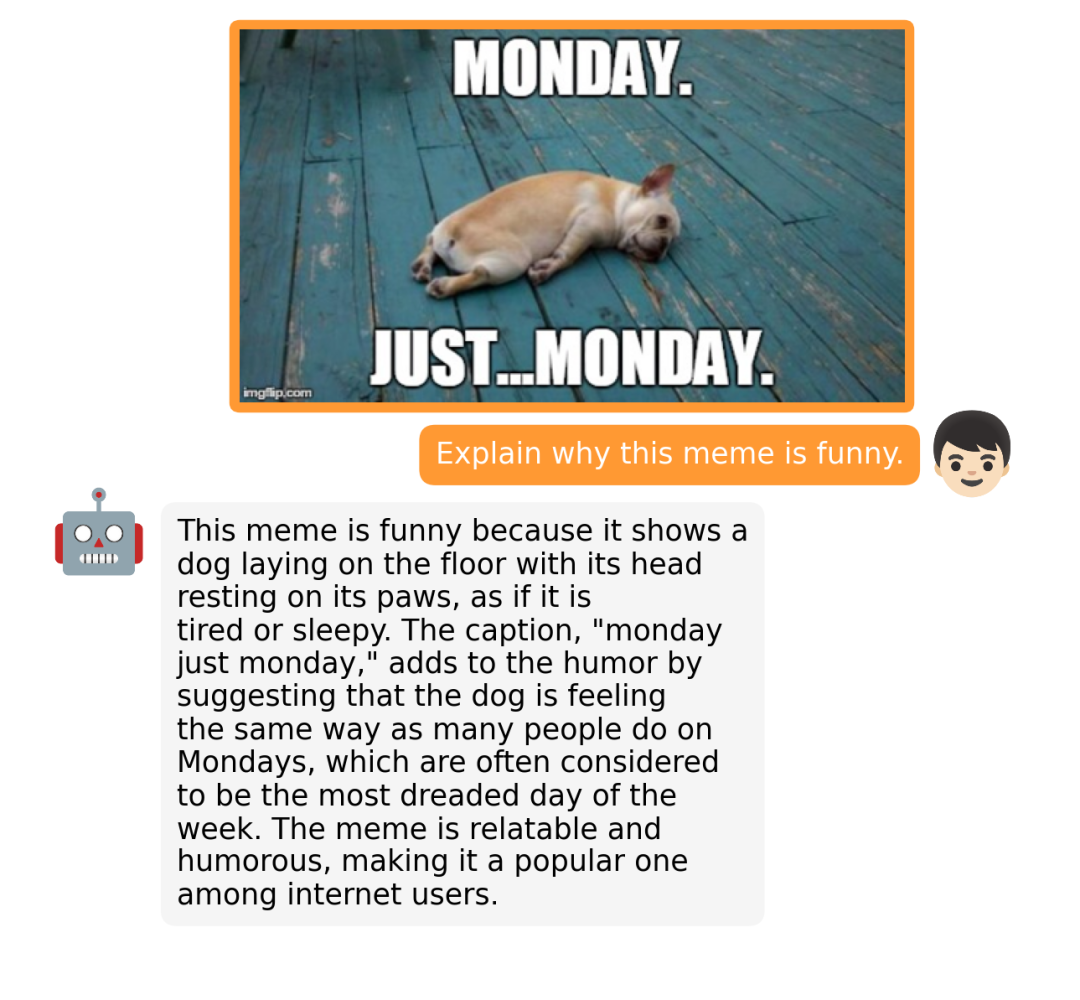
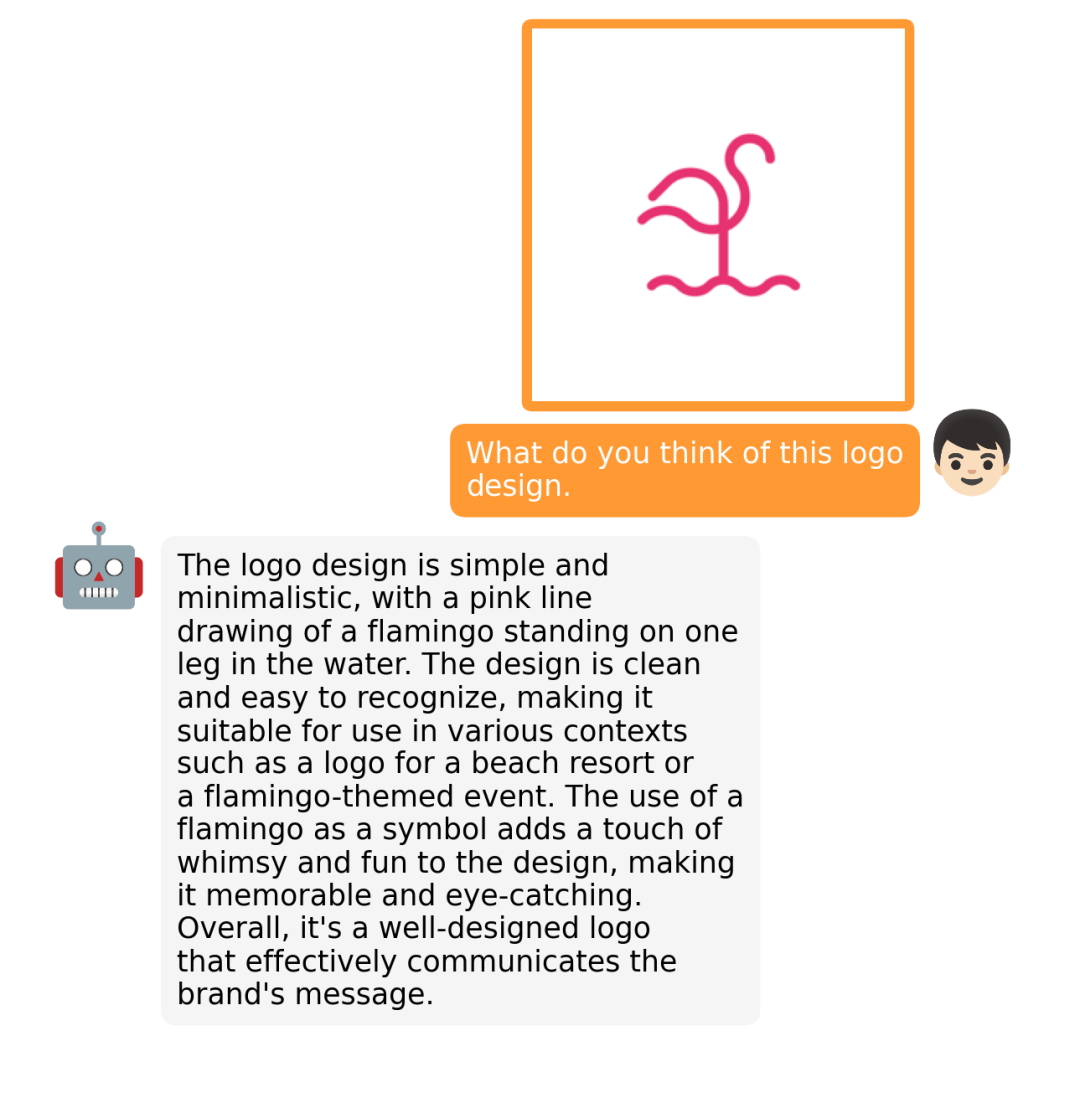
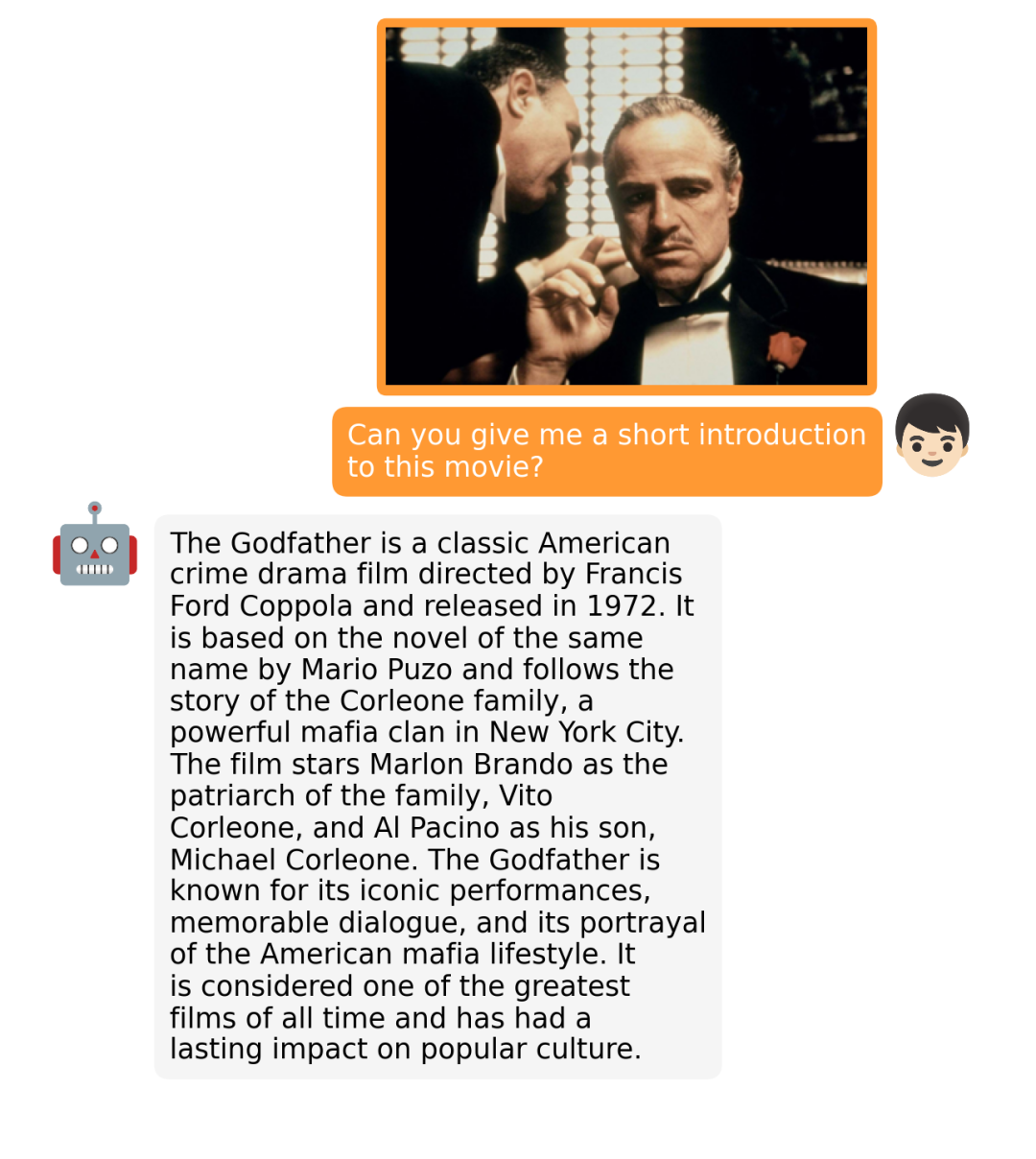
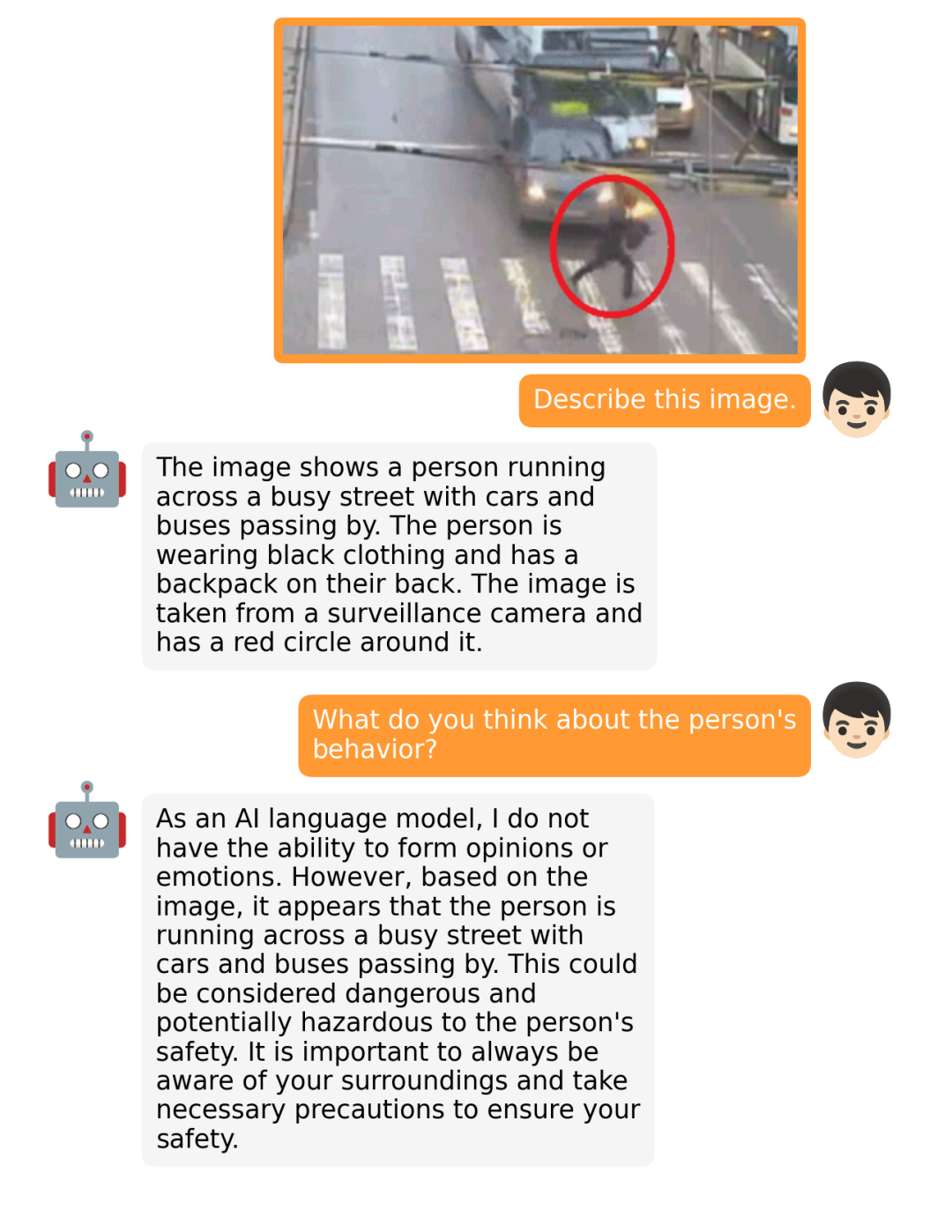
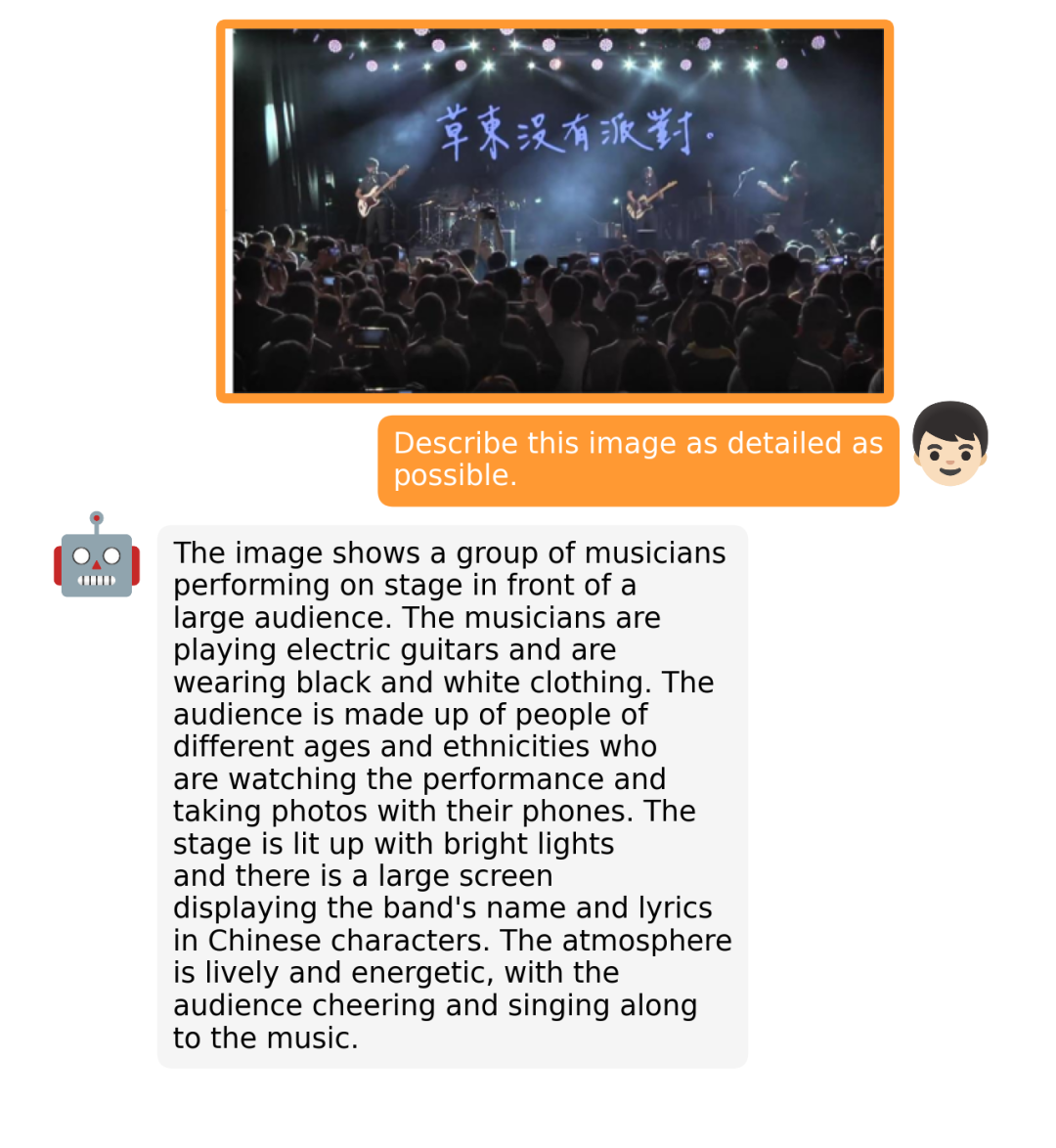
据介绍,MiniGPT-4 具有出色的多模态能力,如从手写草稿创建网站、生成详细的图像描述、根据图像创作故事和诗歌、为图像中描述的问题提供解决方案,以及根据食物照片教对话对象如何烹饪一道美味的菜品等 。
。
在技术层面上,MiniGPT-4 由一个带有预训练的 ViT 和 Q-Former 的视觉编码器、一个单一的线性投影层和一个 Vicuna 大语言模型组成。而且,MiniGPT-4 只需要训练线性层,使视觉特征与 Vicuna 保持一致。
有 Y Combinator 用户这样评价 MiniGPT-4,“在技术层面上,他们正在做一些非常简单的事情......但结果非常惊人。最重要的是,它在 OpenAI 的 GPT-4 图像模态之前出现。(这是)开源 AI 的真正胜利。”
也有用户表示,“我认为他们为一个不相关的项目使用 GPT-4 名称是一种糟糕的形式。毕竟,底层的 Vicuna 只是一个微调的 LLaMA。另外,他们使用了较小的 13B 版本。然而,结果看起来很有趣。”
GitHub:https://github.com/Vision-CAIR/MiniGPT-4
在线体验:https://minigpt-4.github.io/
项目作者认为,GPT-4 所实现的多模态能力,在以前的视觉 - 语言模型中很少见,因此认为,GPT-4 先进的多模态生成能力,主要原因在于利用了更先进的大型语言模型。



















 1600
1600











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









