






2.Neighborhood-Based Collaborative Filtering
2.2 评分矩阵的一些特性
评分的类型, (1)连续型评分,例如Jester的评分从-10到10。(2)离散型评分,最为常见,1-5分等。(3)序列评分,例如,“Strongly Disagree”, “Disagree”, “Neutral”, “Agree”,从某种意义上说和(2)是差不多的。(4)二元评分,like or dislike。(5)一元评分,与(4)的区别在于,它只表达like 或者dislike中的一种,例如只表达like的系统,只记录like的user-item为1, 其余皆无信息。
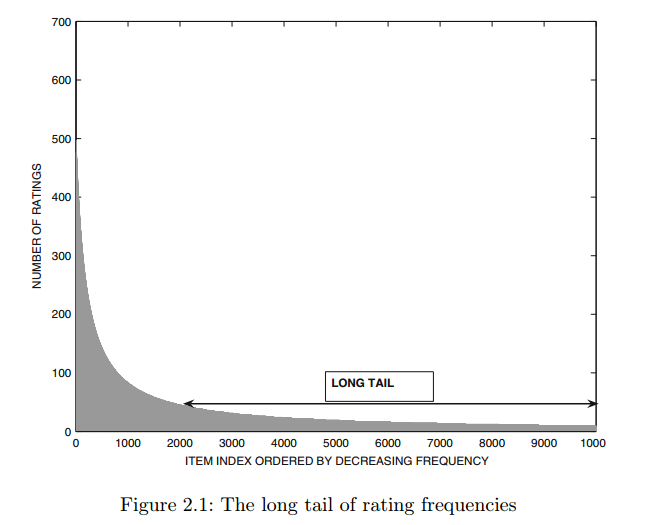
item的评分频数服从长尾分布,在一般推荐系统中,若不考虑此因素,往往会推荐比较流行的商品(评分次数多)。
2.3 Predicting Ratings with Neighborhood-Based Methods
2.3.1 User-Based Neighborhood Models
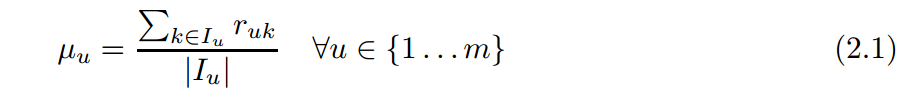
pearson相似度的计算公式为
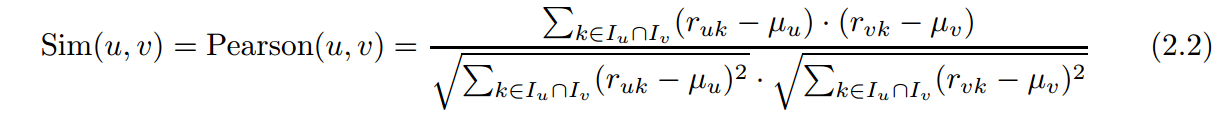
计算用户均值的时候,是用户所有评分的均值,而在计算pearson的时候,计算范围是限在两个用户共同的评分上的。若两用户无共同评分,则pearson为0.
接下来,开始预测评分,首先定义mean-centered 评分,即减掉均值的评分,
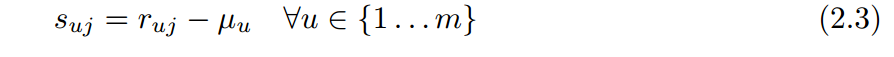
则预测评分公式为
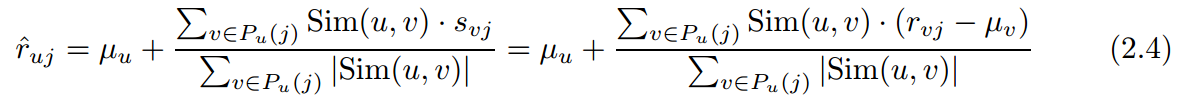
这里说明一下,为什么要去均值,因为每个用户都有自己评分的一个level,减掉均值能够减少这个因素的影响,提高预测准确率,当然如果排序的话,影响不大。
这种类型的的推荐系统一般流程就是先定义相似性度量,再确定预测评分公式。
下面在这两方面,讨论一些变种。
(1)相似度度量上,用余弦计算,有两种
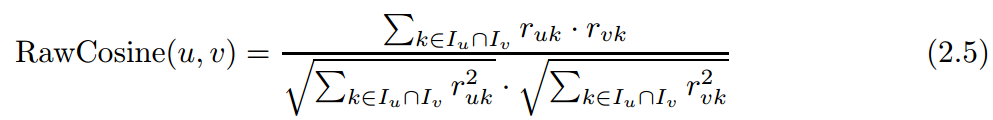
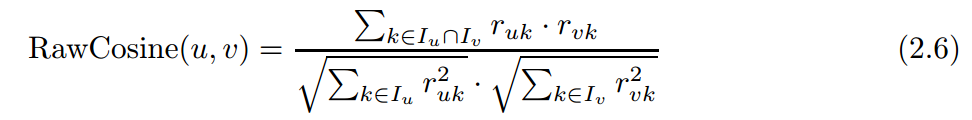
因为pearson有考虑到user评分的level,所以往往在预测方面更偏向于用pearson。
还有一个问题就是,用户两两之间共同评分的数量不一样,这就造成严重的biase, 一般来说,共同评分的数量越多,相似度度量是越可靠的,因此提出,DiscountedSim,即
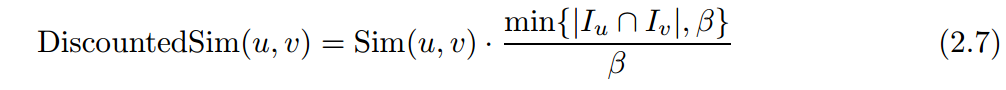
其中\beta是一个阈值。
(2)在预测评分上,主要的变种有Z-score,即标准化。
首先定义标准方差
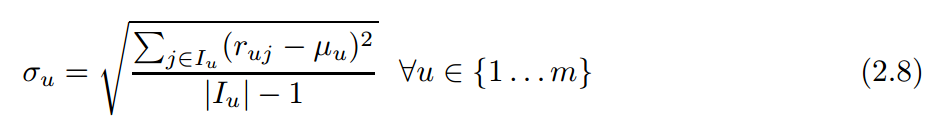
再定义Z-score
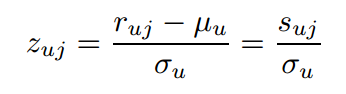
而后,预测评分公式为
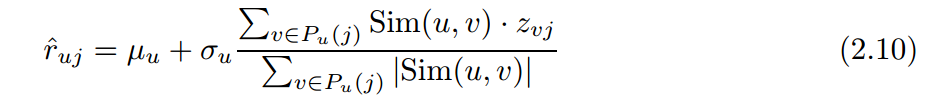
另外在计算用户的k个近邻的时候,会包括一些与用户关系不大,或者负相关的用户,但是这些用户对于预测评分并没有贡献,所以,往往要剔除掉这些用户,再进行评分的预测,提高准确率。
最后一点,还要考虑长尾分布的影响,削弱流行商品的影响程度,定义m_j表示item j的评分次数,m表示用户总数。则权重表示为
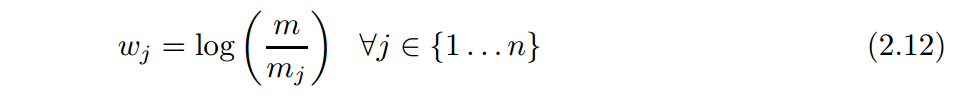
相似度的计算则变为
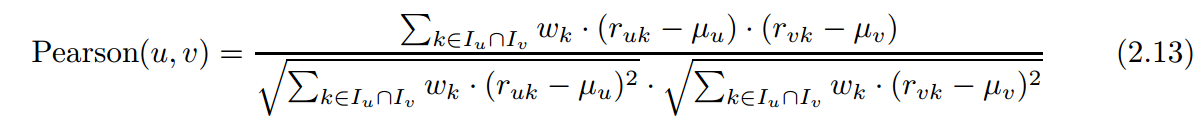
2.3.2 Item-Based Neighborhood Models
仍然从两个步骤来讨论,相似性的度量以及预测评分公式。
在item-based上,一般采用adjustedCosine计算相似度,即
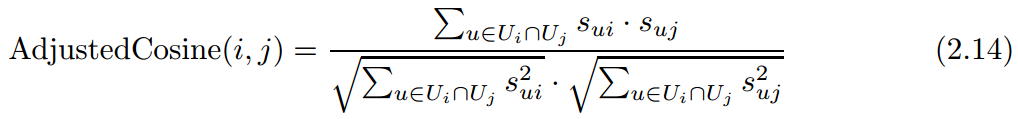
符号定义与前面一致,这里需要注意的是,去均值化的时候,减去的仍然是user上的均值,并不是item上的均值。如果采用pearson计算的话,则采用的是item上的均值,一般adjustedCosine能够取得比较好的效果。
差别参看http://www.zhihu.com/question/21824291。
评分预测公式为
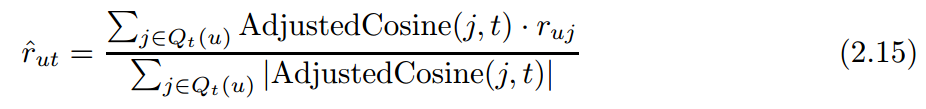
这里不用去中心化,因为是用的同一用户的评分,属于该用户同一level上。
因为user-based和item-based极为相似,因此在user-based中讨论过的改进,都可以用在item-based上,这里不再展开讨论。
2.3.3 Efficient Implementation and computational complexity
2.3.4 Comparing User-Based and Item-Based Methods
2.3.5 Strengths and Weaknesses of Neighborhood-Based Methods
优点:容易实现,可解释性强。缺点:计算时间和空间需求大。2.3.6 A Unified View of User-Based and Item-Based Methods















 901
901

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









