







一、什么是Elasticsearch
分布式全文搜索引擎。其中对比MySQL 数据库-->索引(index) 、表-->类型(type)、行-->文档(doc)、Columns-->属性(fields)
二、基础语法
elasticsearch 使用Restful风格接口,对数据搜索引擎进行操作。
1.检索文档:
_index,_type,_id,_version,found 被称之为元数据,代码该文档的一些基础信息
Request: GET /index/type/id(检索部分文档id后面可以追加?_source=fields,fields来指定需要检索的属性。若不追加指定属性则不返回元数据)
Response:
{
"_index" : "website", //索引
"_type" : "blog", //类型
"_id" : "123", //文档Id
"_version" : 1, //文档版本,每次进行操作过改版本就会加一包括删除,分布式更新凭证
"found" : true, //该文档是否被找到
"_source" : { //文档内容
"title": "My first blog entry",
"text": "Just trying this out...",
"date": "2014/01/01"
}
}1-1.批量检索文档:
Request:POST /inde(可选)/type(可选)/_mget
{
"docs" : [
{
"_index" : "website", //不填默认URL中的配置
"_type" : "blog",
"_id" : 2
},
{
"ids":["2","1"] //可以指定多个ID
}
]
}Response: 多个文档搜索结果的集合,若某一个不存在该文档错误结果会被响应回来
2.更新文档:
Request:PUT /index/type/id (实际上是对文档的替换,将旧索引文档进行删除替换成新文档)
Response:
{
"_index": "zoo",
"_type": "lion",
"_id": "1",
"_version": 6,
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": false
}
2-2.局部更新文档:
不存在时创建。但是多线程同时更新会出现数据错误问题, 为了避免丢失数据,update API在检索(retrieve)阶段检索文档的当前_version,然后在重建索引(reindex)阶段通过index请求提交。如果其他进程在检索(retrieve)和重建索引(reindex)阶段修改了文档,_version将不能被匹配,然后更新失败。可以通过设置URL中的参数retry_on_conflict 重新尝试次数来更新。
(1)Request: POST /index/type/id/_update {"doc":{"new fields":"new value","new filelds2":"new value"}}
(2)使用Groovy脚本
3.创建文档:
Request:POST /index/type/id (如果存在则返回错误,不存在就创建)
4.删除文档:
Request: DELETE /index/type/id (删除的文档版本信息也会自增,但是get搜索不到等到再次保存时版本自增一)
5.批量操作:
bulk API允许我们使用单一请求来实现多个文档的create、index、update或delete。这对索引类似于日志活动这样的数据流非常有用,它们可以以成百上千的数据为一个批次按序进行索引。其中操作请求体使用“\n”连接起来的Json文档流,每一行数据不能包含未被转义的字符。
试着批量索引标准的文档,随着大小的增长,当性能开始降低,说明你每个批次的大小太大了。开始的数量可以在1000~5000个文档之间,如果你的文档非常大,可以使用较小的批次。通常着眼于你请求批次的物理大小是非常有用的。一千个1kB的文档和一千个1MB的文档大不相同。一个好的批次最好保持在5-15MB大小间。
Body:
{ action: { metadata }}\n
{ request body }\nRequest:
{ "delete": { "_index": "website", "_type": "blog", "_id": "123" }} //删除不需要请求体
{ "create": { "_index": "website", "_type": "blog", "_id": "123" }}
{ "title": "My first blog post" } //操作请求体
{ "index": { "_index": "website", "_type": "blog" }}
{ "title": "My second blog post" }
{ "update": { "_index": "website", "_type": "blog", "_id": "123", "_retry_on_conflict" : 3} }
{ "doc" : {"title" : "My updated blog post"} }
//每一行最后必须跟上换行符
三、Elasticsearch 分片
保存新文档时,对于数据保存主分片的选择根据公式来计算:
shard = hash(routing) % number_of_primary_shardsrouting:任意字符串,默认是文档ID。
number_of_primary_shards:该节点上elasticsearch数据主分片数量
1.节点交互
为了阐述意图,我们假设有三个节点的集群。它包含一个叫做bblogs的索引并拥有两个主分片。每个主分片有两个复制分片。相同的分片不会放在同一个节点上,所以我们的集群是这样的:
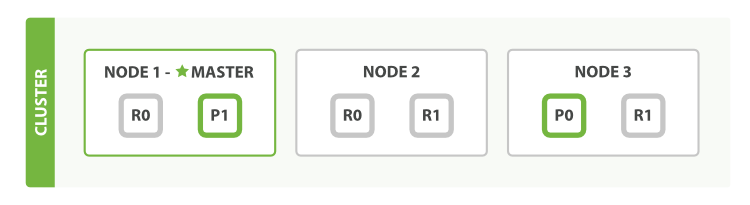
我们能够发送请求给集群中任意一个节点。每个节点都有能力处理任意请求。每个节点都知道任意文档所在的节点,所以也可以将请求转发到需要的节点。下面的例子中,我们将发送所有请求给Node 1,这个节点我们将会称之为请求节点(requesting node)。
新建、索引和删除请求都是写(write)操作,它们必须在主分片上成功完成才能复制到相关的复制分片上。
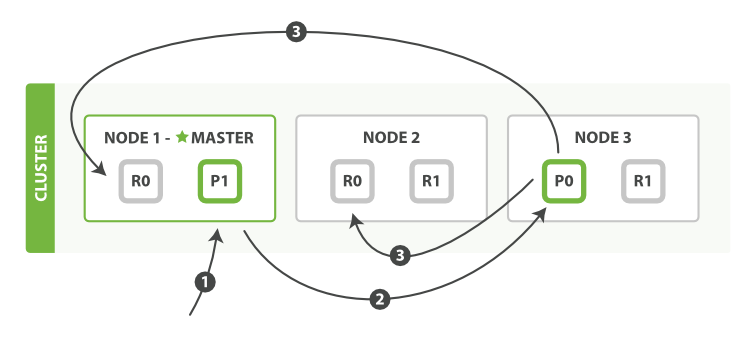
下面我们罗列在主分片和复制分片上成功新建、索引或删除一个文档必要的顺序步骤:
- 客户端给
Node 1发送新建、索引或删除请求。 - 节点使用文档的
_id确定文档属于分片0。它转发请求到Node 3,分片0位于这个节点上。 Node 3在主分片上执行请求,如果成功,它转发请求到相应的位于Node 1和Node 2的复制节点上。当所有的复制节点报告成功,Node 3报告成功到请求的节点,请求的节点再报告给客户端。
客户端接收到成功响应的时候,文档的修改已经被应用于主分片和所有的复制分片。你的修改生效了。
四、ES高级搜索
1.多索引搜索查询
Request: POST /index1,index2,inde*,_all/type1,type2/_search
2.分页
Request: POST /index1/type2/_search?size=1&from=5
分布式查询分页会将协调节点发向各个节点发送查询分页请求,但是各节点会将from+limit的内容返回以供协调节点排除顺序,所以在分布式查询过程中不建议深度分页查询。具体解决办法后面会讲到
备注:(在集群系统中深度分页
为了理解为什么深度分页是有问题的,让我们假设在一个有5个主分片的索引中搜索。当我们请求结果的第一页(结果1到10)时,每个分片产生自己最顶端10个结果然后返回它们给请求节点(requesting node),它再排序这所有的50个结果以选出顶端的10个结果。现在假设我们请求第1000页——结果10001到10010。工作方式都相同,不同的是每个分片都必须产生顶端的10010个结果。然后请求节点排序这50050个结果并丢弃50040个!你可以看到在分布式系统中,排序结果的花费随着分页的深入而成倍增长。这也是为什么网络搜索引擎中任何语句不能返回多于1000个结果的原因。)
3.简易搜索字符串
实际上elasticsearch将文档中的字符串集合成一个_all字段,使用“q=”进行字符串查询时是直接查询_all字段。
Request:POST /index/type/_search?q=(+必须满足,-必须不被满足,没有出现认为匹配越高越好)
4.结构化查询(URL + ?explain 可以查看到具体返回详情)
使用query请求体进行查询:
单子句查询
Request: GET /_search
{
"query":{
"match":{
"field":"XXX"
}
},
"_source":[ //限定返回字段
"field1",
"field2"
]
}合并多子句
Request: GET /_search
{
"query":{
"bool": {
"must": { "match": { "email": "business opportunity" }}, //必须匹配到的条件
"must_not": { "match": { "email": "business opportunity" }},
"should": [
{ "match": { "starred": true },
"multi_match": { //多字段查询
"query": "full text search",
"fields": [ "title", "body" ]
}
},
{ "bool": {
"must": { "folder": "inbox" }},
"must_not": { "spam": true }}
}}
],
"filter": [ //过滤器
{ "term": { "status": "published" }},
{ "range": { "publish_date": { "gte": "2015-01-01" }}} //过滤范围
],
"minimum_should_match": 1 //控制boolshould条件最少匹配的个数,默认为1
}
}
}(filter 实际上缩小查询范围,在性能上面要比query快的多,通过range来缩小会先通过filter返回缩小范围的文档再进行查询)
4.1 查询子句
1.term:精确匹配值数字,布尔类型,字符串(未经过分词的)
2.terms:精确匹配多条件值,单个字段可以提供多个数值
3.rang:过滤范围,gt大于,gte大于等于,lt小于,lte小于等于
4.exits/missing:文档中是否包含或者确实某个字段,等同于 SQL is NULL
5.match:全文查询会在查询前进行字符串分词,相当于模糊查询检索出按照匹配度得分(_score)对结果进行排序
{
"query":{
"bool":{
"must":{
"term":{
"age":26
},
"terms":{ //模糊查询
"tag":[
"search",
"full_text",
"nosql"
]
}
},
"filter":{
"range":{ //过滤范围
"age":{
"gte":20,
"lt":30
}
},
"exits/missing":{ //等同于SQL is null
"field":"name"
}
}
}
}
}
5.排序
添加sort后不会在以相关性来进行排序(可以设置track_scores为true来强行指定按照相关性排序),允许多级排序,其中若是排序字段为集合则可以为集合指定内容排序,可以使用min, max, avg 或 sum这些模式。其中默认字符串会进行analyzed,相当是集合对于集合进行排序会消耗大量内存,建议排序为分词的字符串。
{
"query":{
"filtered":{
"filter":{
"term":{
"user_id":1
}
}
}
},
"sort":[
{
"date":{
"order":"desc"
}
},
{
"field":{
"order":"asc"
}
}
]
}
// 集合多模式
"sort": {
"dates": {
"order": "asc",
"mode": "min"
}
}
五、ES映射与分析
映射对应MySQL中的设计表结构,在创建type时可以指定文档各字段的类型。映射创建后无法修改(新增映射实际上是将原来的干掉重新创建索引,大数量会比较慢),增加映射则直接_update局部更新即可
创建映射:
Request:curl -X PUT /my_index/_mapping/amy_type?pretty
{
"mappings": {
"my_type": {
"dynamic": "strict", //遇到未知字段如何处理 true:自动添加 false:忽略字段 strict:抛出异常
"properties": {
"title": { "type": "string"},
"stash": { //添加一个新的可搜索字段到文档中
"type": "object",
"dynamic": true
},
"dynamic_templates": [ //映射模板
{ "es": {
"match": "*_es", //以_es结尾的字段
"match_mapping_type": "string", //使用在特定的类型上
"mapping": {
"type": "string",
"analyzer": "spanish"
}
}},
{ "en": {
"match": "*", 其他所有字段
"match_mapping_type": "string",
"mapping": {
"type": "string",
"analyzer": "english"
}
}}
]
}
}
}
}查看映射:
Request: curl -X GET /my_index/_mapping/my_type
1.倒排索引
Elasticsearch 全文搜索的基础,其实质是将所有文档进行拆分(使用分析器中的分词器进行拆分),将唯一的单词以及文档建立对应关系表,在进行全文所有时根据相似度算法计算出最优结果,按照实际得分排名(_score)结果进行返回数据。
2.分析器
分析器主要工作是标记化一个文本块为适用于倒排索引单独的词(term),实际上可以对同一个索引建立多个分析器,在实际建立文档字段时选择预设好的分析器。(具体分析器三部分解释可以参考 https://blog.csdn.net/flashflight/article/details/51816023)
预设分析器:
Request: curl PUT IP:PORT/my_index
Body:
{
"settings": {
"analysis": {
"char_filter": { //自定义字符过滤
"&_to_and": {
"type": "mapping",
"mappings": ["&=> and "]
},
"xxx": {....},
"yyy": {....}
},
"tokenizer"{
},
"filter": { //自定义Token过滤器
"my_stopwords": {
"type": "stop",
"stopwords": ["the", "a"]
}
},
"analyzer": {
//自定义分析器,将想要的char_filter、tokenizer、filter给加载进来
"my_analyzer": {
"type": "custom",
"char_filter": ["htmp_strip", "&_to_and"], //数组顺序很重要,因为是照顺序执行,先执行htmp_strip,再执行&_to_and,然后才去执行tokenizer
"tokenizer": "standard",
"filter": ["lowercase", "my_stopwords"]
}
}
}
},
"mappings": {
"doc": {
"properties": {
"nickname": {
"type": "text",
"analyzer": "my_analyzer", //插入时使用自定义的分析器
"search_analyzer": "my_analyzer2" //查询时使用自定义的分析器
"index": "not_analyzed" //是否启用分析器,no:不索引该字段使搜不到,analyzed:默认,not_analyzed:不分析此字段
}
}
}
}
}
实际上感觉建立index牟复杂嘞,反而MySQL会比ES做得好。
其中包含三个部分(均可自定义)
字符过滤器:主要去除字符串中指定的字符,例如HTML字符串可以去除标签且一个分析器可以指定多个过滤器;
分词器:将字符串拆分成单个词(trem),根据不同语言或者拆分规则可指定分词器,但一个分析器只能使用同一个分词器,支持正则;
词单元过滤器:处理经过分词器拆分的单词,进行自动补全或者转换等等操作。可多个
Request:curl -X GET /_analyze?analyzer=standard&text=Text to analyze 测试分析器
六、ES分布式
1.分布式搜索
分布式搜索查询阶段具体步骤:

(1).客户端发送一个search(搜索)请求给Node 3,Node 3创建了一个长度为from+size的空优先级队列。
(2).Node 3 转发这个搜索请求到索引中每个分片的原本或副本。每个分片在本地执行这个查询并且结果将结果到一个大小为from+size的有序本地优先队列里去。
(3).每个分片返回document的ID和它优先队列里的所有document的排序值给协调节点Node 3。Node 3把这些值合并到自己的优先队列里产生全局排序结果。(协调节点使用归并排序算法进行排序)
分布式搜索取回阶段:

(1).协调节点辨别出哪个document需要取回,并且向相关分片发出GET请求。
(2).每个分片加载document并且根据需要丰富(enrich)它们,然后再将document返回协调节点。
(3).一旦所有的document都被取回,协调节点会将结果返回给客户端。
分布式搜索建议进行深度分页因为查询然后取回过程虽然支持通过使用from和size参数进行分页,但是要在有限范围内(within limited)。还记得每个分片必须构造一个长度为from+size的优先队列吧,所有这些都要传回协调节点。这意味着协调节点要通过对分片数量 * (from + size)个document进行排序来找到正确的size个document。
搜索字符串参数设置:(未完待续)
preference(偏爱)
timeout(超时)
routing(路由选择)
search_type(搜索类型)
scroll(滚屏)
scan(扫描)
七、Elasticsearch索引
1.设置索引
Request PUT /index
{
"settings": {
"number_of_shards" : 1, //主分片个数 索引创建后不能更改默认5
"number_of_replicas" : 0 //复制分片个数,创建后可以进行修改
}
}2.设置索引别名
Request: POST /_aliases(通过设置别名可以达到在重建索引时无停机切换以及数据迁移)
{
"actions": [
{
"add": {
"index": "my_index",
"alias": "my_index_alias"
}
}
]
}3.动态索引
ES如何保证新增文档或者新增字段可以加入到原有的文档中呢?实际上是以增加索引的方式来添加文档,步骤如下:
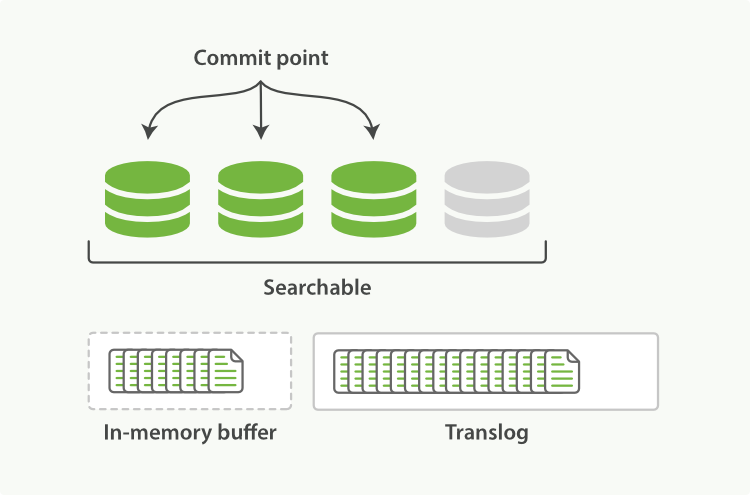
- 新的文档首先写入内存区的索引缓存。
- 不时,这些buffer被提交:
- 一个新的段——额外的倒排索引——写入磁盘。
- 新的提交点写入磁盘,包括新段的名称。
- 磁盘是fsync’ed(文件同步)——所有写操作等待文件系统缓存同步到磁盘,确保它们可以被物理写入。
- 新段被打开,它包含的文档可以被检索
- 内存的缓存被清除,等待接受新的文档。 * n
- 一个提交点写入硬盘
- 文件系统缓存通过fsync操作flush到硬盘
- 事务日志被清除
八、多字段搜索
未完待续














 1423
1423











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









