







这是2024.8月发表在Computers in biology and medicine的一篇论文。这篇论文提出了一种创新方法,利用知识蒸馏训练 EEG 分类器,结合预训练的潜在扩散模型从 EEG 数据中重建图像。
代码链接https://github.com/matteoferrante/EEG_decoding
这篇文章的作者来自意大利罗马第二大学和美国哈佛大学医学院,他们主要做医学成像、神经影像方面的研究。
一、研究背景及目的
EEG 在解码大脑视觉表征方面具有重要价值,但当前研究多关注多主体模型,且基于 EEG 信号重建视觉刺激存在挑战。本研究旨在改进现有方法,实现从 EEG 模式中翻译感知体验的实时应用。已有研究利用深度学习模型从 EEG 信号解码视觉表征,但存在不足。本文提出的方法与之不同,使用基于 CLIP 的知识蒸馏训练卷积神经网络,结合生成扩散合成,直接从 EEG 脑信号重建详细逼真的视觉刺激。
注:CLIP 即 Contrastive Language-Image Pre-Training,是一种对比语言 - 图像预训练的神经网络架构。它通过对比学习的方式,训练图像编码器和文本编码器,使二者能够将图像和文本映射到一个共同的嵌入空间中。在这个空间里,语义一致的图像和文本在距离上更为接近,从而让模型学会关联图像和文本信息。
二、实验
1、数据预处理
使用 ImageNet EEG 和 THINGSEE - G2 两个公开数据集。前者来自 6 名参与者观看 40 个 ImageNet 类别的 2000 张图片的 EEG 记录,采样率 1000Hz;后者包含 10 名参与者对 1854 个类别的 82160 次 EEG 反应记录。
先对 EEG 信号用陷波滤波器去除 49 - 51Hz 的电源线干扰,再用 14 - 70Hz 的带通巴特沃斯滤波器聚焦相关频段,然后对 EEG 信号在各个通道上进行标准化。将滤波后的 EEG 信号分割成 40ms 的窗口,每次移动 20ms,以获取适合模型处理的短时段数据。运用短时傅里叶变换(STFT)对这些分段信号进行时频分解(TFD),把每个试次的信号转化为 128 通道的频谱图。针对 THINGSEE - G2 数据集类别多的问题,用 K - 均值聚类算法对预训练 CLIP 模型生成的图像嵌入进行处理,确定 8 个聚类类别,为整个数据集生成伪标签。重新标注数据后,将频谱图用于卷积神经网络的训练与评估。下图是聚类的实例:

2、模型构建与训练
EEG 分类器(CNN):采用带有集成残差连接的卷积神经网络(CNN)对 EEG 时频分布(TFDs)进行分类。将经过预处理得到的 EEG 频谱图作为输入,这些频谱图是通过对滤波和标准化后的 EEG 信号进行短时傅里叶变换得到的。
基于 CLIP 的知识蒸馏:使用预训练的 CLIP 图像分类器作为 “教师” 模型。CLIP 能够将图像和文本映射到一个共同的嵌入空间,通过对比学习使语义一致的图像和文本在该空间中距离更近。在本研究中,CLIP 从图像中生成类概率,为学生模型提供监督信号。基于 EEG 数据训练的 CNN 作为 “学生” 模型。它通过知识蒸馏的方式,学习教师模型(CLIP)所学到的知识,即根据神经信号预测类概率。
使用知识蒸馏损失,促使学生模型(CNN)的输出接近教师模型(CLIP)的输出。通过最小化两者之间的差异,让学生模型学习到教师模型的知识。在训练过程中,将 EEG 频谱图输入到 CNN 中,同时将对应的图像输入到 CLIP 中。CLIP 输出类概率作为软标签,CNN 的输出与这些软标签进行比较,计算损失并更新 CNN 的参数。
图像重建模型:采用 Stable Diffusion 模型,它是一种潜在扩散模型。在训练好 EEG 分类器后,将分类器预测的类别标签输入到 Stable Diffusion 模型中,生成与 EEG 活动对应的图像,通过不断调整模型参数,使得生成的图像更符合预期的视觉内容,实现从 EEG 活动到视觉内容的重建。
3、实验结果
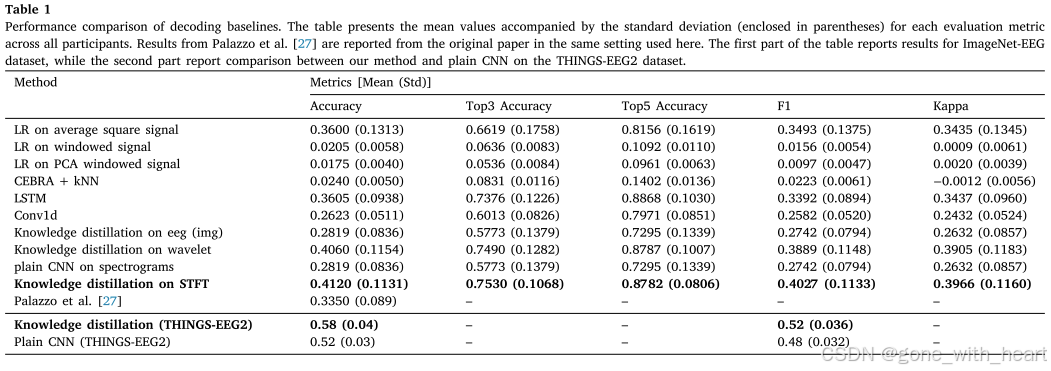
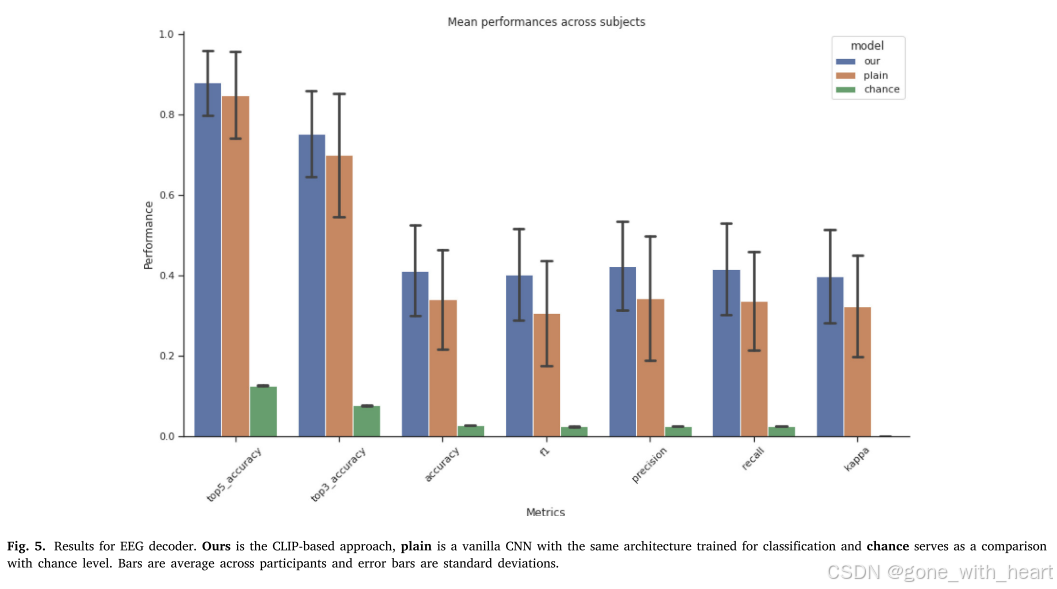
分类性能:使用 top-5、top-3、top-1 准确率、F1 分数和归一化 kappa 分数等指标评估模型性能。在 ImageNet-EEG 数据集上,基于 CLIP 知识蒸馏的 CNN 模型表现卓越,top-5 准确率达 87%,远超传统机器学习基线模型,如逻辑回归在平均平方信号上的 top-5 准确率仅 0.8156。与其他深度学习模型相比,该模型也更具优势,证明知识蒸馏技术和 2D 卷积在处理 EEG 数据时的有效性。在 THINGSEE- G2 数据集上,采用聚类衍生伪标签后,该模型 top-1 预测准确率达 58%,优于普通 CNN,表明其能有效从 EEG 数据中解码语义信息。
图像重建:在 ImageNet-EEG 数据集上,模型能根据 EEG 数据重建图像。虽存在类别混淆,如 “bolete” 可能被误重建为 “pizza”,但整体上能准确识别主要语义类别并重建相应图像,证明模型有一定的图像重建能力。在 THINGSEE- G2 数据集上,文章未详细展示图像重建结果,而是着重展示分类结果,以证明模型解码语义信息的能力
三、总结
该研究提出用知识蒸馏训练 EEG 分类器并结合潜在扩散模型重建图像的创新方法。经对两个独立数据集的实验验证,该方法在 EEG 解码和图像重建方面取得显著成果,为脑 - 机接口、神经假体和人机交互等领域带来新可能。未来研究将聚焦提升系统解码精度与效率,探索与 fMRI 等其他模态的融合以改善空间分辨率,融入实时反馈机制优化脑 - 机接口,同时深入研究相关伦理问题和神经数据安全,确保技术合理应用 。
[1] Ferrante M, Boccato T, Bargione S, et al. Decoding visual brain representations from electroencephalography through knowledge distillation and latent diffusion models[J]. Computers in Biology and Medicine, 2024, 178: 108701.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









