







什么是消息的完整性处理?
一个从 spout 中发送出的 tuple 会产生上千个基于它创建的 tuples。例如,有这样一个 word-count 拓扑:
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("sentences", new KestrelSpout("kestrel.backtype.com", 22133, "sentence_queue",new StringScheme()));
builder.setBolt("split", new SplitSentence(), 10)
.shuffleGrouping("sentences");
builder.setBolt("count", new WordCount(), 20)
.fieldsGrouping("split", new Fields("word"));
这个拓扑从一个 Kestrel 队列中读取句子,然后将句子分解成若干个单词,然后将它每个单词和该单词的数量发送出去。这种情况下,从 spout 中发出的 tuple 就会产生很多基于它创建的新 tuple:包括句子中单词的 tuple 和 每个单词的个数的 tuple。这些消息构成了这样一棵树:
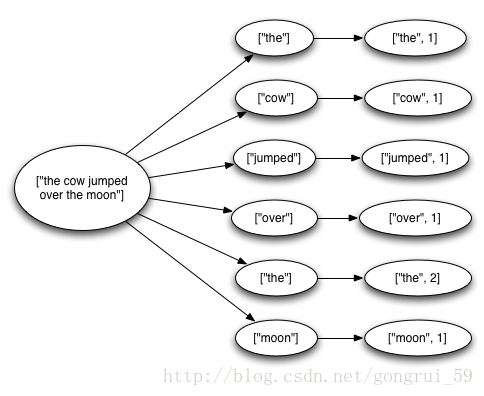
如果这棵 tuple 树发送完成,并且树中的每一条消息都得到了正确的处理,就表明发送 tuple 的 spout 已经得到了“完整性处理”。对应的,如果在指定的超时时间内 tuple 树中有消息没有完成处理就意味着这个 tuple 失败了。这个超时时间可以使用 Config.TOPOLOGY_MESSAGE_TIMEOUT_SECS 参数在构造拓扑时进行配置,如果不配置,则默认时间为 30 秒。
如何实现不同层次的消息保证机制?
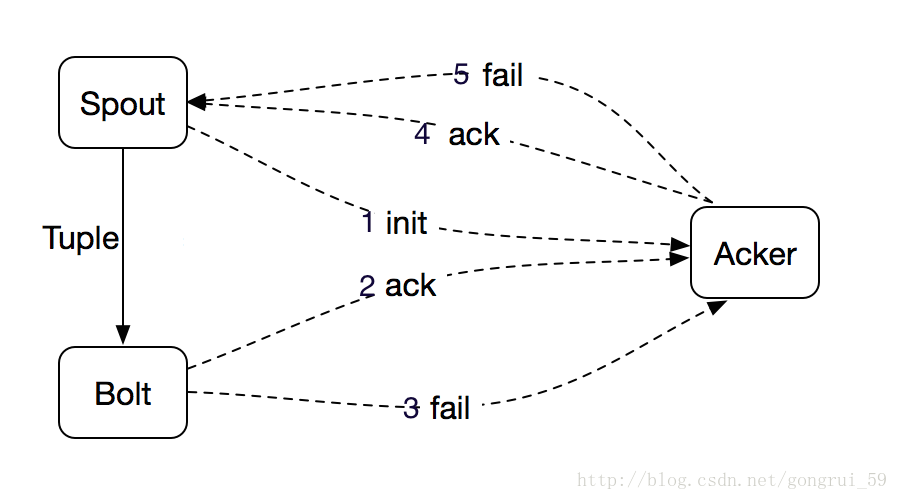
Tuple 的完全处理需要 Spout、Bolt 以及 Acker(Storm 中用来记录某棵 Tuple 树是否被完全处理的节点)协同完成,如上图所示。从 Spout 发送 Tuple 到下游,并把相应信息通知给 Acker,整棵 Tuple 树中某个 Tuple 被成功处理了都会通知 Acker,待整棵 Tuple 树都被处理完成之后,Acker 将成功处理信息返回给 Spout;如果某个 Tuple 处理失败,或者超时,Acker 将会给 Spout 发送一个处理失败的消息,Spout 根据 Acker 的返回信息以及用户对消息保证机制的选择判断是否需要进行消息重传。可以得到Storm的可靠性是通过一个叫做Acker的模块来实现的,它会跟踪Spout、Bolt发送tuple时所形成的tuple树,看tuple树是成功处理(tuple叶子是否被都被处理)还是失败(只要一个tuple叶子失败了)了。
除了Acker要跟踪tuple树的处理状态外,当然还需要Spout和Bolt来配合,才能达到Storm的可靠性。那么如何来配合呢?
Spout的可靠性保证
在Storm中,消息处理可靠性从Spout开始的。storm为了保证数据能正确的被处理, 对于spout产生的每一个tuple,storm都能够进行跟踪,这里面涉及到了ack/fail的处理, 如果一个tuple被处理成功,那么spout便会调用其ack方法,如果失败,则会调用fail方法。而topology中处理tuple的每一个bolt都会通过OutputCollector来告知storm,当前bolt处理是否成功。
我们知道spout必须能够追踪它发射的所有tuples或其子tuples,并且在这些tuples处理失败时能够重发。那么spout如何追踪tuple呢?storm是通过一个简单的anchor机制来实现的(在下面的bolt可靠性中会讲到)。
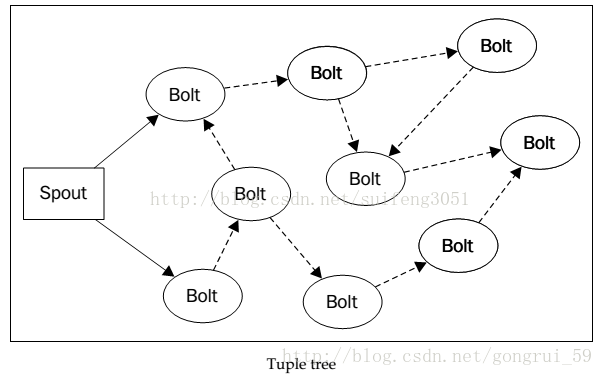
如上图所示,实线代表的是spout发射的根tuple,而虚线代表的就是来源于根tuple的子tuples。这个图就是一个TupleTree。在这个tree中,所有的bolt都会ack或fail一个tuple,如果tree中所有的bolt都ack了经过它的tuple,那么Spout的ack方法就会被调用,表示整个消息被处理完成。如果tree中的任何一个bolt fail一个tuple,或者整个处理过程超时,则Spout的fail方法便会被调用。
当Storm的Spout发射一个Tuple后,他便会调用nextTuple()方法,在这个过程中,保证可靠性处理的第一步就是为发射出的Tuple分配一个唯一的ID,并把这个ID传给emit()方法:
collector.emit( new Values("value1" , "value2") , msgId ); 为Tuple分配一个唯一ID的目的就是为了告诉Storm,Spout希望这个Tuple产生的Tuple tree在处理完成或失败后告知它,如果Tuple被处理成功,Spout的ack()方法就会被调用,相反如果处理失败,Spout的fail()方法就会被调用,Tuple的ID也都会传入这两个方法中。
需要注意的是,虽然spout有可靠性机制,但这个机制是否启用由我们控制的。IBasicBolt在emit一个tuple后自动调用ack()方法,用来实现比较简单的计算。如果是IRichBolt的话,如果想要实现anchor,必须自己调用ack方法。
Bolt中的可靠性
Bolt中的可靠性主要靠两步来实现:
1、发射衍生Tuple的同时anchor原Tuple
2、对各个Tuples做ack或fail处理
anchor一个Tuple就意味着在输入Tuple和其衍生Tuple之间建立了关联,关联之后的Tuple便加入了Tuple tree。我们可以通过如下方式anchor一个Tuple:
collector.emit( tuple, new Values( word)); 如果我们发射新tuple的时候不同时发射元tuple,那么新发射的Tuple不会参与到整个可靠性机制中,它们的fail不会引起root tuple的重发,我们成为unanchor:
collector.emit( new Values( word)); ack和fail一个tuple的操作方法:
this .collector.ack(tuple);
this .collector.fail(tuple); storm的可靠性是由spout和bolt共同决定的,storm利用了anchor机制来保证处理的可靠性。如果spout发射的一个tuple被完全处理,那么spout的ack方法即会被调用,如果失败,则其fail方法便会被调用。在bolt中,通过在emit(oldTuple,newTuple)的方式来anchor一个tuple,如果处理成功,则需要调用bolt的ack方法,如果失败,则调用其fail方法。一个tuple及其子tuple共同构成了一个tupletree,当这个tree中所有tuple在指定时间内都完成时spout的ack才会被调用,但是当tree中任何一个tuple失败时,spout的fail方法则会被调用。
IBasicBolt类会自动调用ack/fail方法,而IRichBolt则需要我们手动调用ack/fail方法。
通过以上两步,Acker就能确定了一个tuple树。最后Acker还需要知道每个tuple树上的每个tuple的处理结果。是成功还是失败?结果的通知也是需要Bolt来告知Acker的。处理成功了则调用collector.ack(srctuple);处理失败了则调用collector.fail(srctuple);其中srctuple都是Bolt收到的源tuple。
当Acker确定了tuple树被成功处理了,那么Storm会调用Spout的ack方法;如果Acker确定tuple树被失败处理了(包括超时),那么Storm会调用Spout的fail方法。
Storm为了简化编程,它提供了BaseBasicBolt,这个类提供的collector不是一般的OutputCollector,而是BasicOutputCollector,通过BasciOutputCollector,已经实现了锚定和结果通知。我们只要继承BaseBasicBolt来定义Bolt就可以了。
发送消息的时候,只要collector.emit(newtuple); 只要指定新产生的tuple就以了,无需指定源tuple。
发送结果的时候,如果成功了,可以不需要写任何代码;如果失败了,则抛出一个FailedException异常。
如果要Acker来跟踪每个tuple树,那么会消耗很多的内存,是无法满足实现条件的。这时Storm采用了一个非常巧妙的算法,通过给每个tuple分配一个64bit的随机数,生成tuple的时候会和之前的结果做一次异或xor,Bolt响应的时候也会和之前的结果做一次异或xor,我们知道相同的两个数做异或,结果一定为0,那么当tuple树上的所有tuple都做了两次异或后,结果一定会为0,那么Acker就可以通过异或xor的结果是否为0,能判断整个tuple树的处理结果了。当然这种算法需要的内存可以很少,也可能会出现误判的情况,但出现误判的概率几乎为0。
可靠性还是需要一些额外的计算和网络开销的,如果你的应用不需要可靠性支持,可以通过下面的几种方法取消可靠性支持:
整个topology都取消:通过设置Acker的并发度为0:Config.TOPOLOGY_ACKERS = 0,那么这时候,Spout发送完tuple后,Spout的ack方法立即被调用。
某个Bolt发送的tuple都取消:此Bolt不需要做锚定就可以了。(按道理也不需要调用ack)
某个tuple取消:在Spout发送Spout时,不指定msgid就可以了。
测试代码:
package com.yc.hadoop.storm02.work;
import java.util.Map;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;
public class MySpout extends BaseRichSpout {
private static final long serialVersionUID = 5669587246566277919L;
private SpoutOutputCollector collector;
@Override
public void open(@SuppressWarnings("rawtypes") Map conf, TopologyContext context,
SpoutOutputCollector collector) {
this.collector = collector;
}
int num = 0;
@Override
public void nextTuple() {
num++;
System.out.println("spout:"+num);
int messageid = num;
//开启消息确认机制,就是在发送数据的时候发送一个messageid,一般情况下,messageid可以理解为mysql数据里面的主键id字段
//要保证messageid和tuple之间有一个唯一的对应关系,这个关系需要程序员自己维护
this.collector.emit(new Values(num),messageid);
Utils.sleep(1000);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("num"));
}
@Override
public void ack(Object msgId) {
System.out.println("处理成功!"+msgId);
}
@Override
public void fail(Object msgId) {
System.out.println("处理失败!"+msgId);
}
}
package com.yc.hadoop.storm02.work;
import java.util.Map;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
public class MyBolt extends BaseRichBolt {
private static final long serialVersionUID = -7718845344194712302L;
private OutputCollector collector;
@Override
public void prepare(@SuppressWarnings("rawtypes") Map stormConf, TopologyContext context,
OutputCollector collector) {
this.collector = collector;
}
int sum = 0;
@Override
public void execute(Tuple input) {
try{
Integer num = input.getIntegerByField("num");
sum += num;
collector.emit(input, new Values("sum"));
this.collector.ack(input);
System.out.println("sum="+sum);
}catch(Exception e){
this.collector.fail(input);
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
package com.yc.hadoop.storm02.work;
import java.util.Map;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.BasicOutputCollector;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseBasicBolt;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
public class MyBolt02 extends BaseBasicBolt {
private static final long serialVersionUID = -7718845344194712302L;
int sum = 0;
@Override
public void prepare(@SuppressWarnings("rawtypes") Map stormConf, TopologyContext context) {
super.prepare(stormConf, context);
}
@Override
public void execute(Tuple input, BasicOutputCollector collector) {
Integer num = input.getIntegerByField("num");
sum += num;
collector.emit(new Values("sum"));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
package com.yc.hadoop.storm02.work;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.topology.TopologyBuilder;
public class MyStorm {
public static void main(String[] args) {
TopologyBuilder topologyBuilder = new TopologyBuilder();
String spout_id = MySpout.class.getSimpleName();
String bolt_id = MyBolt.class.getSimpleName();
topologyBuilder.setSpout(spout_id, new MySpout());
topologyBuilder.setBolt(bolt_id, new MyBolt02()).shuffleGrouping(spout_id);
Config config = new Config();
config.setMaxSpoutPending(1000);//如果设置了这个参数,必须要保证开启了acker机制才有效
//在本地运行
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology("test", config, topologyBuilder.createTopology());
}
}
这里有两个Bolt类,所继承的有不一样,但运行结果其实是差不多的。主要是区别baserichbolt和basebasicbolt的区别。
参考:http://ifeve.com/storm-guaranteeing-message-processing/
http://storm.apache.org/releases/1.0.2/Guaranteeing-message-processing.html
http://blog.csdn.net/suifeng3051/article/details/41682441
https://zhuanlan.zhihu.com/p/23127603














 8465
8465











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









