






To improve game performance, we’d like to highlight a programming paradigm that will help you maximize your CPU potential, make your game more efficient, and code smarter.
Before we get into detail of data-oriented programming, let’s explain the problems it solves and common pitfalls for programmers.
Memory
The first thing a programmer must understand is that memory is slow and the way you code affects how efficiently it is utilized. Inefficient memory layout and order of operations forces the CPU idle waiting for memory so it can proceed doing work.
The easiest way to demonstrate is by using an example. Take this simple code for instance:
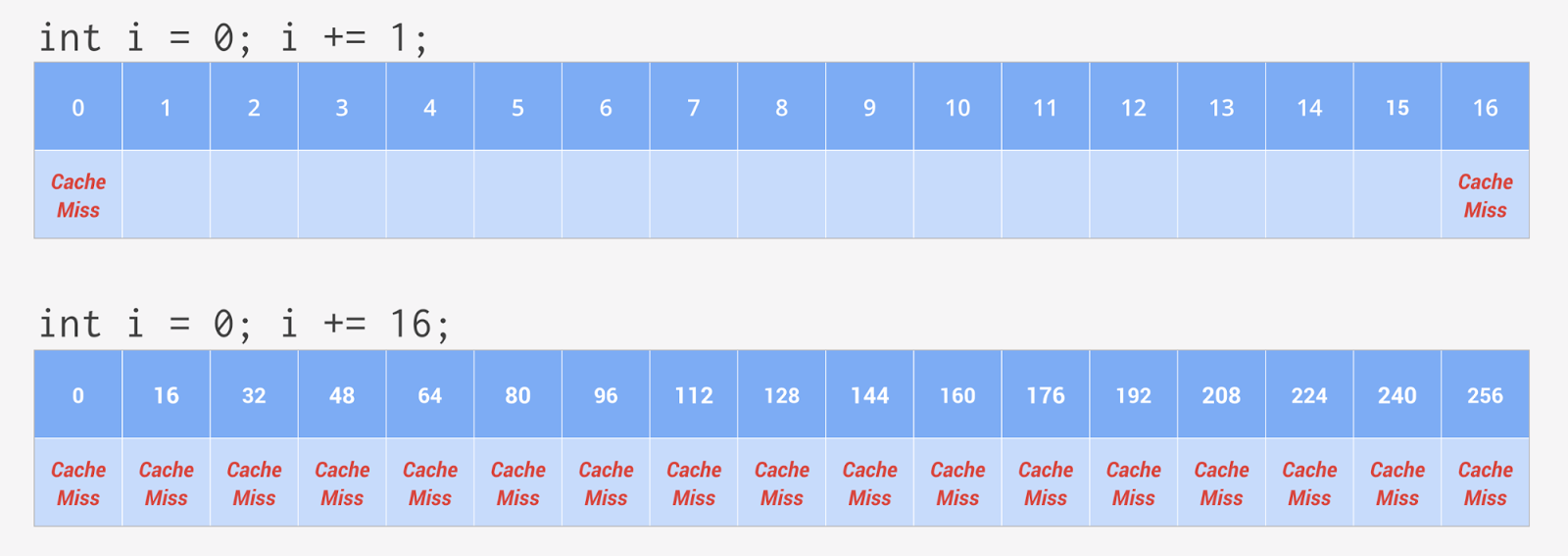
char data[1000000]; // One Million bytes unsigned int sum = 0; for ( int i = 0; i < 1000000; ++i ) { sum += data[ i ]; }
An array of one million bytes is declared and iterated on one byte at a time. Now let's change things a little to illustrate the underlying hardware. Changes marked in bold:
char data[16000000]; // Sixteen Million bytes unsigned int sum = 0; for ( int i = 0; i < 16000000; i += 16 ) { sum += data[ i ]; }
The array is changed to contain sixteen million bytes and we iterate over one million of them, skipping 16 at a time.
A quick look suggests there shouldn't be any effect on performance as the code is translated to the same number of instructions and runs the same number of times, however that is not the case. Here is the difference graph. Note that this is on a logarithmic scale--if the scale were linear, the performance difference would be too large to display on any reasonably-sized graph!

Graph in logarithmic scale
The simple change making the loop skip 16 bytes at a time makes the program run 5 times slower!
The average difference in performance is 5x and is consistent when iterating 1,000 bytes up to a million bytes, sometimes increasing up to 7x. This is a serious change in performance.
Note: The benchmark was run on multiple hardware configurations including a desktop with Intel 5930K 3.50GHz CPU, a Macbook Pro Retina laptop with 2.6 GHz Intel i7 CPU and Android Nexus 5 and Nexus 6 devices. The results were pretty consistent.
If you wish to replicate the test, you might have to ensure the memory is out of the cache before running the loop because some compilers will cache the array on declaration. Read below to understand more on how it works.
Explanation
What happens in the example is quite simply explained when you understand how the CPU accesses data. The CPU can’t access data in RAM; the data must be copied to the cache, a smaller but extremely fast memory line which resides near the CPU chip.
When the program starts, the CPU is set to run an instruction on part of the array but that data is still not in the cache, therefore causing a cache miss and forcing the CPU to wait for the data to be copied into the cache.
For simplicity sake, assume a cache size of 16 bytes for the L1 cache line, this means 16 bytes will be copied starting from the requested address for the instruction.
In the first code example, the program next tries to operate on the following byte, which is already copied into the cache following the initial cache miss, therefore continuing smoothly. This is also true for the next 14 bytes. After 16 bytes, since the first cache miss the loop, will encounter another cache miss and the CPU will again wait for data to operate on, copying the next 16 bytes into the cache.
In the second code sample, the loop skips 16 bytes at a time but hardware continues to operate the same. The cache copies the 16 subsequent bytes each time it encounters a cache miss which means the loop will trigger a cache miss with each iteration and cause the CPU to wait idle for data each time!
Note: Modern hardware implements cache prefetch algorithms to prevent incurring a cache miss per frame, but even with prefetching, more bandwidth is used and performance is lower in our example test.
In reality the cache lines tend to be larger than 16 bytes, the program would run much slower if it were to wait for data at every iteration. A Krait-400 found in the Nexus 5 has a L0 data cache of 4 KB with 64 Bytes per line.
If you are wondering why cache lines are so small, the main reason is that making fast memory is expensive.
Data-Oriented Design
The way to solve such performance issues is by designing your data to fit into the cache and have the program to operate on the entire data continuously.
This can be done by organizing your game objects inside Structures of Arrays (SoA) instead of Arrays of Structures (AoS) and pre-allocating enough memory to contain the expected data.
For example, a simple physics object in an AoS layout might look like this:
struct PhysicsObject { Vec3 mPosition; Vec3 mVelocity; float mMass; float mDrag; Vec3 mCenterOfMass; Vec3 mRotation; Vec3 mAngularVelocity; float mAngularDrag; };
This is a common way way to present an object in C++.
On the other hand, using SoA layout looks more like this:
class PhysicsSystem { private: size_t mNumObjects; std::vector< Vec3 > mPositions; std::vector< Vec3 > mVelocities; std::vector< float > mMasses; std::vector< float > mDrags; // ... };
Let’s compare how a simple function to update object positions by their velocity would operate.
For the AoS layout, a function would look like this:
void UpdatePositions( PhysicsObject* objects, const size_t num_objects, const float delta_time ) { for ( int i = 0; i < num_objects; ++i ) { objects[i].mPosition += objects[i].mVelocity * delta_time; } }
The PhysicsObject is loaded into the cache but only the first 2 variables are used. Being 12 bytes each amounts to 24 bytes of the cache line being utilised per iteration and causing a cache miss with every object on a 64 bytes cache line of a Nexus 5.
Now let’s look at the SoA way. This is our iteration code:
void PhysicsSystem::SimulateObjects( const float delta_time ) { for ( int i = 0; i < mNumObjects; ++i ) { mPositions[ i ] += mVelocities[i] * delta_time; } }
With this code, we immediately cause 2 cache misses, but we are then able to run smoothly for about 5.3 iterations before causing the next 2 cache misses resulting in a significant performance increase!
The way data is sent to the hardware matters. Be aware of data-oriented design and look for places it will perform better than object-oriented code.
We have barely scratched the surface. There is still more to data-oriented programming than structuring your objects. For example, the cache is used for storing instructions and function memory so optimizing your functions and local variables affects cache misses and hits. We also did not mention the L2 cache and how data-oriented design makes your application easier to multithread.
Make sure to profile your code to find out where you might want to implement data-oriented design. You can use different profilers for different architecture, including the NVIDIA Tegra System Profiler, ARM Streamline Performance Analyzer, Inteland PowerVR PVRMonitor.
If you want to learn more on how to optimize for your cache, read on cache prefetching for various CPU architectures.















 8927
8927


 到【灌水乐园】发言
到【灌水乐园】发言









Links to this post
Create a Link