







2台机器,系统均为Centos 7.2,主节点IP为10.45.154.236,第二节点的IP为10.45.154.70,均为内网IP。
1.下载相关软件包
到官网上下载最新版本ElasticSearch 7.4,https://www.elastic.co/cn/downloads/elasticsearch
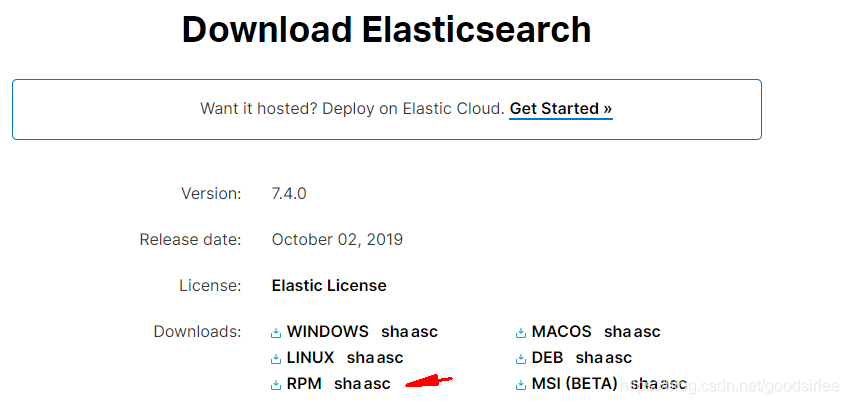
我选择的是RPM包
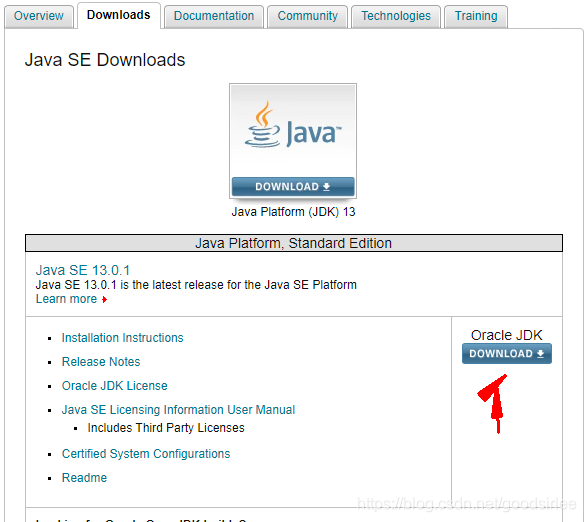
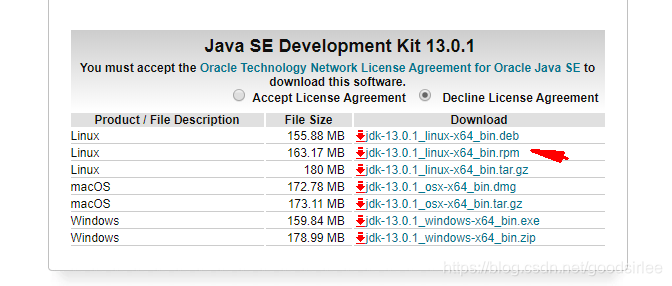
下载最新的JDK 13 https://www.oracle.com/technetwork/java/javase/downloads/index.html
2.修复系统配置
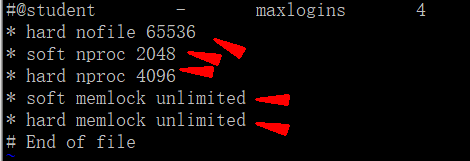
vi /etc/security/limits.conf
新增内容如下:
* hard nofile 65536
* soft nproc 2048
* hard nproc 4096
* soft memlock unlimited
* hard memlock unlimited
vi /etc/sysctl.conf
新增内容如下:
vm.max_map_count=655360
fs.file-max=655360
执行 sysctl -p 让其生效
3.安装软件
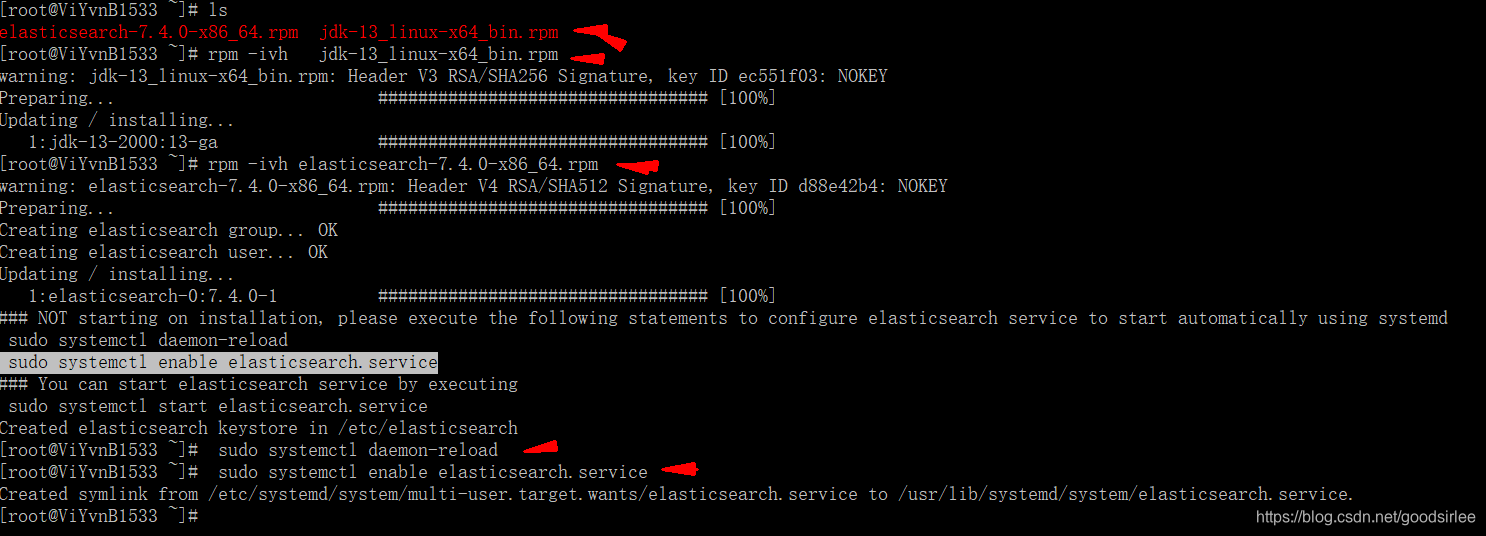
直接rpm安装软件包,再执行如下命令,让其开机自启
sudo systemctl daemon-reload
sudo systemctl enable elasticsearch.service
查看一下java环境是否正常

4.修改配置文件
做个备份: cp -rf /etc/elasticsearch/elasticsearch.yml /etc/elasticsearch/elasticsearch.yml.bak
/etc/elasticsearch/elasticsearch.yml
主节点配置信息:
#集群名称
cluster.name: ES-Cluster
#节点名称
node.name: ES-node1
#是否是master节点
node.master: true
#是否允许该节点存储索引数据
node.data: true
#日志目录
path.logs: /var/log/elasticsearch
#绑定地址
network.host: 0.0.0.0
#http端口
http.port: 9200
#集群主机列表
discovery.seed_hosts: [“10.45.154.236”,“10.45.154.70”]
#启动全新的集群时需要此参数,再次重新启动时此参数可免
#cluster.initial_master_nodes: [“10.45.154.236”]
#集群内同时启动的数据任务个数,默认是2个
cluster.routing.allocation.cluster_concurrent_rebalance: 32
#添加或删除节点及负载均衡时并发恢复的线程个数,默认4个
cluster.routing.allocation.node_concurrent_recoveries: 32
#初始化数据恢复时,并发恢复线程的个数,默认4个
cluster.routing.allocation.node_initial_primaries_recoveries: 32
#存储位置
path.data: /data
#是否开启跨域访问
http.cors.enabled: true
#开启跨域访问后的地址限制,*表示无限制
http.cors.allow-origin: “*”
第二个节点配置如下:
#集群名称
cluster.name: ES-Cluster
#节点名称
node.name: ES-node2
#是否是master节点
node.master: false
#是否允许该节点存储索引数据
node.data: true
#日志目录
path.logs: /var/log/elasticsearch
#绑定地址
network.host: 0.0.0.0
#http端口
http.port: 9200
#集群主机列表
discovery.seed_hosts: [“10.45.154.236”,“10.45.154.70”]
#启动全新的集群时需要此参数,再次重新启动时此参数可免
#cluster.initial_master_nodes: [“10.45.154.236”]
#集群内同时启动的数据任务个数,默认是2个
cluster.routing.allocation.cluster_concurrent_rebalance: 32
#添加或删除节点及负载均衡时并发恢复的线程个数,默认4个
cluster.routing.allocation.node_concurrent_recoveries: 32
#初始化数据恢复时,并发恢复线程的个数,默认4个
cluster.routing.allocation.node_initial_primaries_recoveries: 32
#存储位置
path.data: /data
#是否开启跨域访问
http.cors.enabled: true
#开启跨域访问后的地址限制,*表示无限制
http.cors.allow-origin: “*”
5.创建存储目录
mkdir -p /data/nodes
chown elasticsearch:elasticsearch /data/nodes
6.开放防火墙端口
在主节点上执行:
firewall-cmd --permanent --zone=public --add-rich-rule=“rule family=“ipv4” source address=“10.45.154.70” port protocol=“tcp” port=“9300” accept”
firewall-cmd --complete-reload
在第二节点上执行:
firewall-cmd --permanent --zone=public --add-rich-rule=“rule family=“ipv4” source address=“10.45.154.236” port protocol=“tcp” port=“9300” accept”
firewall-cmd --complete-reload
7.启动ES
两台都执行:
systemctl start elasticsearch
主节点查看效果:
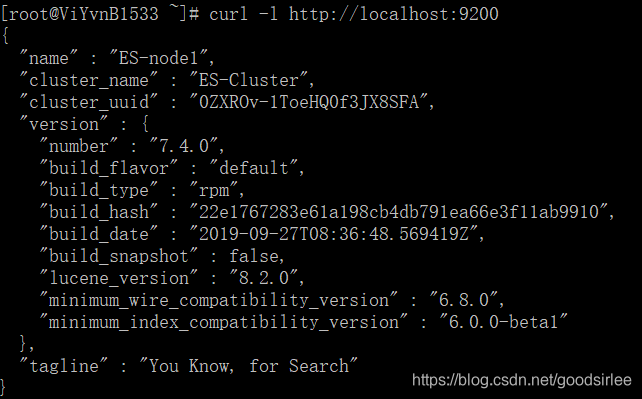
第二节点查看效果:
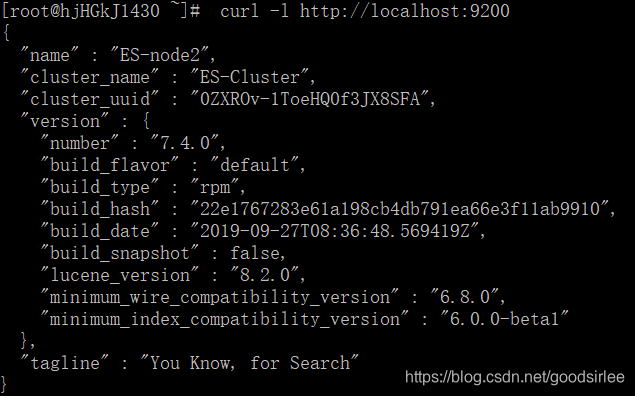














 79
79











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









