






1. 语言模型
什么是语言模型?通俗的来讲是判断一句话是否符合人说话的模型,如可以说”猫有四条腿“,却不能说”四条腿有猫“。因为”四条腿有猫“这样的表述不符合人们的正常语言规范。在语言模型的发展过程中,分别出现了专家语法规则模型,统计语言模型,神经网络语言模型三个阶段。其中,专家语法规则模型出现在语言模型的初始阶段,我们知道,每一种语言都有其特定的语法规则,因此在早期,人们设法通过归纳出的语法规则来对语言建模;统计语言模型则是对句子的概率分布建模,通过对大量语料的统计发现,符合人们正常语言规范的句子出现的概率要大于不符合语言规范的句子,如上述的“猫有四条腿”出现的概率要大于“四条腿有猫”的概率;神经网络语言模型是在统计语言模型的基础上,通过神经网络模型对句子的概率分布建模的方法。下面将从统计语言模型开始讲起。
2. 统计语言模型
2.1. 统计语言模型
统计语言模型(statistical language modeling)通过对大量语料的统计预测出句子的分布。用形式表述,即对于一段文本序列 S = w 1 , w 2 , ⋯ , w T S=w_1,w_2,\cdots ,w_T S=w1,w2,⋯,wT,它的概率可以表示为
P ( S ) = P ( w 1 , w 2 , ⋯ , w T ) P\left ( S \right )=P\left ( w_1,w_2,\cdots ,w_T \right ) P(S)=P(w1,w2,⋯,wT)
通过概率中的链式法则,可以求得上述句子的概率值:
P ( w 1 , w 2 , ⋯ , w T ) = P ( w 1 ) ⋅ P ( w 2 ∣ w 1 ) ⋯ P ( w T ∣ w 1 , w 2 , ⋯ w T − 1 ) P\left ( w_1,w_2,\cdots ,w_T \right )=P\left ( w_1 \right )\cdot P\left ( w_2\mid w_1 \right )\cdots P\left ( w_T\mid w_1,w_2,\cdots w_{T-1} \right ) P(w1,w2,⋯,wT)=P(w1)⋅P(w2∣w1)⋯P(wT∣w1,w2,⋯wT−1)
其中, P ( w i ∣ w 1 , ⋯ , w i − 1 ) P\left ( w_i\mid w_1,\cdots ,w_{i-1} \right ) P(wi∣w1,⋯,wi−1)表示的是在词 w 1 , ⋯ , w i − 1 w_1,\cdots ,w_{i-1} w1,⋯,wi−1出现的条件下词 w i w_i wi出现的概率,对于以上的统计语言模型,每一个词的概率便是模型的参数,如上述的 P ( w 1 ) P\left ( w_1 \right ) P(w1), P ( w 2 ∣ w 1 ) P\left ( w_2\mid w_1 \right ) P(w2∣w1)等。为了计算模型的参数,需要统计每个词出现的概率,如对于词 w i w_i wi,可以通过以下的方式统计得到:
P ( w i ∣ w 1 , ⋯ , w i − 1 ) = N ( w 1 , w 2 , ⋯ , w i ) N ( w 1 , w 2 , ⋯ , w i − 1 ) P\left ( w_i\mid w_1,\cdots ,w_{i-1} \right )=\frac{N_{\left ( w_1,w_2,\cdots ,w_i \right )}}{N_{\left ( w_1,w_2,\cdots ,w_{i-1} \right )}} P(wi∣w1,⋯,wi−1)=N(w1,w2,⋯,wi−1)N(w1,w2,⋯,wi)
其中, N ( w 1 , w 2 , ⋯ , w i ) N_{\left ( w_1,w_2,\cdots ,w_i \right )} N(w1,w2,⋯,wi)表示的在文本语料中出现文本序列 w 1 , w 2 , ⋯ , w i w_1,w_2,\cdots ,w_i w1,w2,⋯,wi的次数。
在实际的过程中,如果文本的长度比较长,要估算 P ( w i ∣ w 1 , ⋯ , w i − 1 ) P\left ( w_i\mid w_1,\cdots ,w_{i-1} \right ) P(wi∣w1,⋯,wi−1)是非常困难的,主要体现在以下的两个方面:
- 需要计算的参数过多。假设词库 V V V的大小为100000,对于包含10个词的序列,潜在的参数个数为 10000 0 10 − 1 100000^{10}-1 10000010−1;
- 数据极度稀疏,长序列的出现频次较低;
2.2. n-gram模型
为了简化上述的问题,通常在估算条件概率时,距离大于等于 n n n的上文词会被忽略,即所谓的n-gram模型。n-gram模型是基于马尔科夫假设,即当前词出现的概率仅依赖前 n − 1 n−1 n−1个词
P ( w i ∣ w 1 , ⋯ , w i − 1 ) ≈ P ( w i ∣ w i − n + 1 , ⋯ , w i − 1 ) P\left ( w_i\mid w_1,\cdots ,w_{i-1} \right )\approx P\left ( w_i\mid w_{i−n+1},\cdots ,w_{i-1} \right ) P(wi∣w1,⋯,wi−1)≈P(wi∣wi−n+1,⋯,wi−1)
当 n = 1 n=1 n=1时,又称为unigram(一元语言模型),句子的概率值为 P ( w 1 , w 2 , ⋯ , w T ) = P ( w 1 ) ⋅ P ( w 2 ) ⋯ P ( w T ) P\left ( w_1,w_2,\cdots ,w_T \right )=P\left ( w_1 \right )\cdot P\left ( w_2 \right )\cdots P\left ( w_T \right ) P(w1,w2,⋯,wT)=P(w1)⋅P(w2)⋯P(wT),从公式可以看出,u nigram模型中,句子的概率为其中的每个词的概率的乘积,即假设每个词是相互独立的,这样句子中的词序信息会丢失,虽然估算方便了,但是效果会有较大的损耗;为了解决性能和效率的问题,通常设置 n = 2 n=2 n=2或者 n = 3 n=3 n=3,当 n = 2 n=2 n=2时,又称为bigram(二元语言模型),当 n = 3 n=3 n=3时,又称为trigram(三元语言模型),即当前词部分依赖上文中的词。
3. 神经网络语言模型
在n-gram模型中,为了更好地保留词序信息,构建更强大的语言模型,通常希望选择较大的 n n n。当 n n n较大时,长度为 n n n的序列出现的次数就会非常少,数据稀疏的问题依然没有能够解决。为了更好地解决n-gram中估算概率遇到的数据稀疏问题,神经网络语言模型应运而生。NNLM(Nerual Network Language Model)是经典的用神经语言模型,在论文《A Neural Probabilistic Language Model》中提出。
3.1. NNLM原理
对于神经网络语言模型,训练数据集与上述一致,是一系列词的集合构成的序列: S = w 1 , w 2 , ⋯ , w T S=w_1,w_2,\cdots ,w_T S=w1,w2,⋯,wT,其中, w t ∈ V w_t\in V wt∈V, V V V表示的是词库。NNLM的目标函数为:
f ( w t , ⋯ , w t − n + 1 ) = P ( w t ∣ w 1 , ⋯ , w t − 1 ) f\left ( w_t,\cdots ,w_{t-n+1} \right )=P\left ( w_t\mid w_1,\cdots ,w_{t-1} \right ) f(wt,⋯,wt−n+1)=P(wt∣w1,⋯,wt−1)
神经网络语言模型通过词 w t w_t wt的前 n − 1 n-1 n−1个词 w t − n + 1 , ⋯ , w t − 1 w_{t-n+1},\cdots ,w_{t-1} wt−n+1,⋯,wt−1估算出概率 P ( w t ∣ w 1 , ⋯ , w t − 1 ) P\left ( w_t\mid w_1,\cdots ,w_{t-1} \right ) P(wt∣w1,⋯,wt−1),从而避免大量的统计工作。这里有两个限制条件:
- ∑ i = 1 ∣ V ∣ f ( i , w t − 1 , ⋯ , w t − n + 1 ) = 1 \sum_{i=1}^{\left | V \right |}f\left ( i,w_{t-1},\cdots ,w_{t-n+1} \right )=1 ∑i=1∣V∣f(i,wt−1,⋯,wt−n+1)=1
- f > 0 f>0 f>0
神经语言模型NNLM采用普通的三层前馈神经网络结构,其网络结构如下图所示(与通常的三层前馈神经网络略有不同):
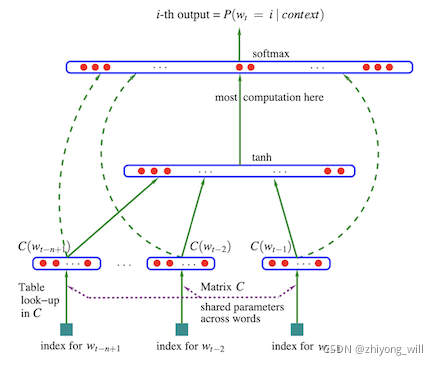
从网络结构可以看出,三层的网络中第一层为输入层,通过一个映射矩阵
C
C
C(
C
C
C可以认为是一个
∣
V
∣
×
m
\left | V \right |\times m
∣V∣×m的共享矩阵,将词库
V
V
V中的每个词映射成对应的向量,可通过索引的方式取得对应词的词向量)将前
n
n
n个词映射成
m
m
m维的词向量,如词库
V
V
V中的第
i
i
i个词,映射成词向量后为
C
(
i
)
∈
R
m
C\left ( i \right )\in\mathbb{R}^m
C(i)∈Rm,生成前
n
−
1
n-1
n−1个词的向量表示
x
x
x:
x = ( C ( w t − 1 ) , C ( w t − 2 ) , ⋯ , C ( w t − n + 1 ) ) x=\left ( C\left ( w_{t-1} \right ),C\left ( w_{t-2} \right ),\cdots ,C\left ( w_{t-n+1} \right ) \right ) x=(C(wt−1),C(wt−2),⋯,C(wt−n+1))
当输入层完成对上文的 n − 1 n-1 n−1个词的词向量表示后,模型将数据送入到剩下的两层网络中,分别为隐藏层和输出层 y y y:
y = b + W x + U t a n h ( d + H x ) y=b+Wx+Utanh\left ( d+Hx \right ) y=b+Wx+Utanh(d+Hx)
假设 h h h表示隐藏层的神经元个数,那么 H ∈ R h × ( n − 1 ) m H\in \mathbb{R}^{h\times \left ( n-1 \right )m} H∈Rh×(n−1)m, d ∈ R h d\in \mathbb{R}^{h} d∈Rh, U ∈ R ∣ V ∣ × h U\in \mathbb{R}^{\left | V \right |\times h} U∈R∣V∣×h, W ∈ R ∣ V ∣ × ( n − 1 ) m W\in \mathbb{R}^{\left | V \right |\times \left ( n-1 \right )m} W∈R∣V∣×(n−1)m, b ∈ R ∣ V ∣ b\in \mathbb{R}^{\left | V \right |} b∈R∣V∣。
输出层共有 ∣ V ∣ \left | V \right | ∣V∣个神经元,依次对应着词库 V V V中每个词的可能性。为了使得所有神经元的结果之和为 1 1 1,在输出层 y y y之后,需要加入softmax函数,将 y y y专程对应的概率值:
P ( w t ∣ w t − n + 1 , ⋯ , w t − 1 ) = e x p ( y w t ) ∑ i e x p ( y i ) P\left ( w_t\mid w_{t−n+1},\cdots ,w_{t-1} \right )=\frac{exp\left ( y_{w_t} \right )}{\sum _iexp\left ( y_i \right )} P(wt∣wt−n+1,⋯,wt−1)=∑iexp(yi)exp(ywt)
3.2. 模型训练
综上,模型中的参数为 θ = ( b , d , W , U , H , C ) \theta =\left ( b,d,W,U,H,C \right ) θ=(b,d,W,U,H,C),对于整个语料,神经网络语言模型需要最大化:
L = 1 T ∑ t l o g f ( w t , w t − 1 , ⋯ , w t − n + 1 ; θ ) + R ( θ ) L=\frac{1}{T}\sum _tlog\: f\left ( w_t,w_{t-1},\cdots ,w_{t-n+1}; \theta \right )+R\left ( \theta \right ) L=T1t∑logf(wt,wt−1,⋯,wt−n+1;θ)+R(θ)
其中 R ( θ ) R\left ( \theta \right ) R(θ)为正则项,对于神经网络的训练,通常使用梯度下降对损失函数求解,对于上述的最大化问题,可通过下述公式迭代求解:
θ ← θ + ϵ ∂ L ∂ θ \theta \leftarrow \theta +\epsilon \frac{\partial L}{\partial \theta } θ←θ+ϵ∂θ∂L
参考文献
- [1] Kandola E J , Hofmann T , Poggio T , et al. A Neural Probabilistic Language Model[J]. Studies in Fuzziness & Soft Computing, 2006, 194:137-186.














 145
145











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









