







开篇序
在学习机器学习的过程中,我写了简单易学的机器学习算法的专题,依然还有很多的算法会陆续写出来。网上已经有很多人分享过类似的材料,我只是通过自己的理解,想尽可能用一种通俗易懂的方式讲出来。在不断学习的过程中,陆陆续续补充了很多的知识点,在学习吴军老师的《数学之美》的过程中,也补充了很多我之前遗漏的知识点,吴军老师已经在《数学之美》上把问题讲得很清楚,我在这里只是再增加一些我对这些问题的认识。专题的顺序与原书不一致,其中的原因是我在学习机器学习的过程中遇到了问题会翻阅一些书,所以,顺序与我学习时遇到的问题是相关的。借此机会,感谢那些默默支持我的人,我会更加努力写出高质量的博文。
一、什么是TF-IDF
首先解释下TF-IDF的全称,TF-IDF全称是Term Frequency / Inverse Document Frequency,全称的意思为词频、逆文本频率。
在我们处理文本时,例如,对于一篇文章,文章是由很多的词组成,通过与我们的词库对比,我们可以很容易的过滤掉一些公认的停止词(Stop Word),只保留一些关键词。停止词是指对文章的主题没有任何帮助却在文章中大量出现的一些词,如“的”、“是”等。剩下的关键词也并不是都是同等重要的,我们要确定关键词在文章中的权重,这样我们才能确定文章的主题,此时,我们就可以使用TF-IDF来计算各个关键词的权重。
TF是指一个词在一篇文章中出现的频率。单纯使用TF将会出现一些问题,问题是一些通用的词对于主题并没有太大的作用,反倒是一些出现频率较少的词才能够表达文章的主题。所以权重的设计必须满足:一个词预测主题的能力越强,权重越大,反之,权重越小。
所有统计的文章中,一些词只是在其中很少几篇文章中出现,那么这样的词对文章的主题的作用很大,这些词的权重应该设计的较大。IDF就是在完成这样的工作,如果一个关键词 在
在 篇文章中出现,那么越大,关键词的权重反倒是越小。最后我们将TF的值和IDF的值综合考虑,便能得到关键词的权重:
篇文章中出现,那么越大,关键词的权重反倒是越小。最后我们将TF的值和IDF的值综合考虑,便能得到关键词的权重: 。
。
二、如何计算TF-IDF值
对于一个处理好的词项-文档矩阵:
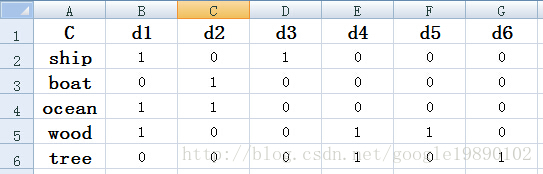
文章有:d1,d2,d3,d4,d5和d6,关键词有:“ship”,“boat”,“ocean”,“wood”和“tree”。矩阵中的数字表示词在对应文章中出现的次数。
1、TF的计算
TF表示词在一篇文章中出现的频率。这里我们假设每篇文章的词的个数为 ,
, 。则词“ship”在文章d1中的TF值为:
。则词“ship”在文章d1中的TF值为: 。其他的可以依次类比。
。其他的可以依次类比。
2、IDF的计算
IDF的公式为:
其中, 表示全部的文章数,表示关键词出现的文章数。如关键词“ship”在文章d1和d3中出现,则
表示全部的文章数,表示关键词出现的文章数。如关键词“ship”在文章d1和d3中出现,则 ,而全部的文章数
,而全部的文章数 。则
。则") 。
。
3、TF-IDF的值
TF-IDF的值即为最终的权重,是将TF值与IDF值相乘,则对于关键词“ship”的TF-IDF值为:
三、实际的例子
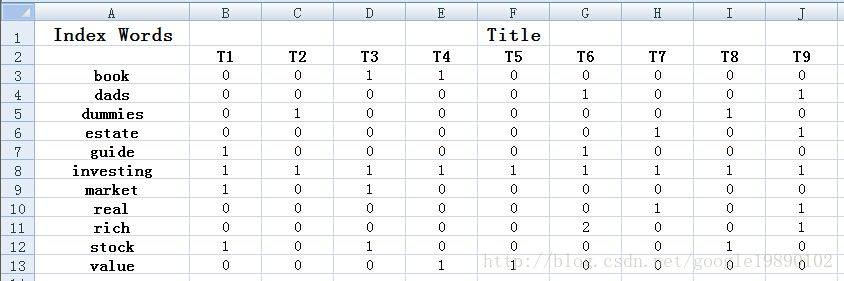
选择了9个标题:(参考文献2)
- The Neatest Little Guide to Stock Market Investing
- Investing For Dummies, 4th Edition
- The Little Book of Common Sense Investing: The Only Way to Guarantee Your Fair Share of Stock Market Returns
- The Little Book of Value Investing
- Value Investing: From Graham to Buffett and Beyond
- Rich Dad's Guide to Investing: What the Rich Invest in, That the Poor and the Middle Class Do Not!
- Investing in Real Estate, 5th Edition
- Stock Investing For Dummies
- Rich Dad's Advisors: The ABC's of Real Estate Investing: The Secrets of Finding Hidden Profits Most Investors Miss
去掉了停止词“and”,“edition”,“for”,“in”,“little”,“of”“the”,“to”。我们可以得到以下的词项-文档矩阵:
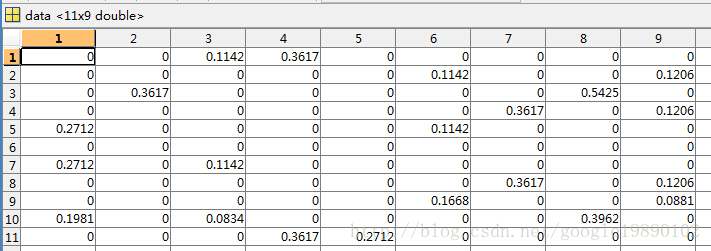
最终的结果为:
MATLAB源码
TF_IDF函数
function [ dataMade ] = TFIDF( dataSet )
[m,n] = size(dataSet);%计算dataSet的大小,m为词的个数,n为标题的个数
%rowSum = sum(dataSet);% 每个标题中关键词的总和
rowSum = [8,6,19,6,8,19,6,4,18];
colSum = sum(dataSet,2);% 每个词在不同标题中出现的总和
dataMade = zeros(m,n);% 构造一个一样大小的矩阵,用于存储TF-IDF值
for i = 1:m
TempIDF = log2(n./colSum(i,:));
for j = 1:n
dataMade(i,j) = (dataSet(i,j)./rowSum(:,j))*TempIDF;
end
end
end
主函数
%% TF_IDF
% load data
% 注意每一列为标题,每一行为词
dataSet = [0 0 1 1 0 0 0 0 0
0 0 0 0 0 1 0 0 1
0 1 0 0 0 0 0 1 0
0 0 0 0 0 0 1 0 1
1 0 0 0 0 1 0 0 0
1 1 1 1 1 1 1 1 1
1 0 1 0 0 0 0 0 0
0 0 0 0 0 0 1 0 1
0 0 0 0 0 2 0 0 1
1 0 1 0 0 0 0 1 0
0 0 0 1 1 0 0 0 0
];
% 计算TF-IDF值
data = TFIDF(dataSet);注意点:在参考文献2中有两个问题:
1、在求解TF时,TF的分母应该是整个文本的长度,可参见维基百科http://zh.wikipedia.org/wiki/TF-IDF。
2、在求解IDF时,取对数的时应该是以2为底,而不是以
为底。
参考文献
1、《数学之美》吴军 著. 第11章 如何确定网页和查询的相关性. P105-110.














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









