






1、设定一个文件(UTF-8.txt)为UTF-8编码,另一个文件(GBK.txt)为GBK编码。
UTF-8.txt 中的汉字 copy ( Ctrl+a, Ctrl+c ) 到 GBK.txt 中会乱码?
答案:不会!
如下错误操作会导致乱码:
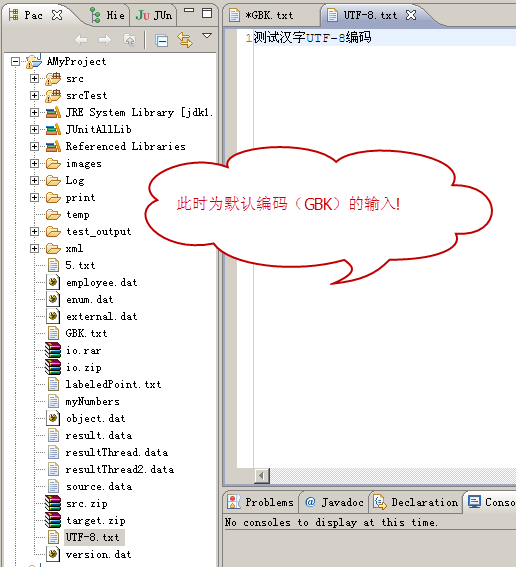
a、UTF-8.txt 采用默认编码 ( GBK ) ,输入:“测试汉字UTF-8编码”
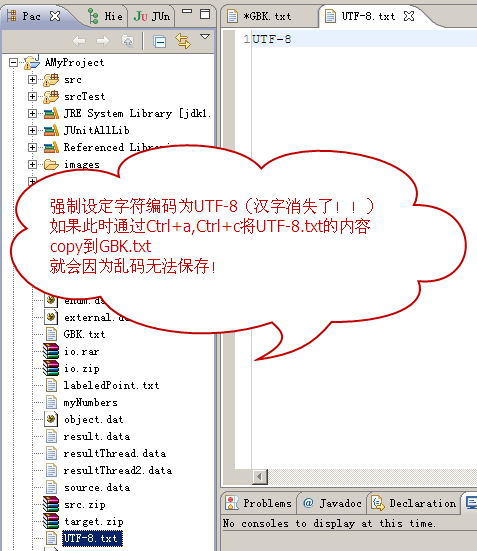
b、再重设字符编码为UTF-8,显示文字:“UTF-8”
c、再将文字补全:“测试汉字UTF-8编码”,再进行copy操作就会出现乱码。其实乱码在b操作就出现了,而不是因为这里的汉字!
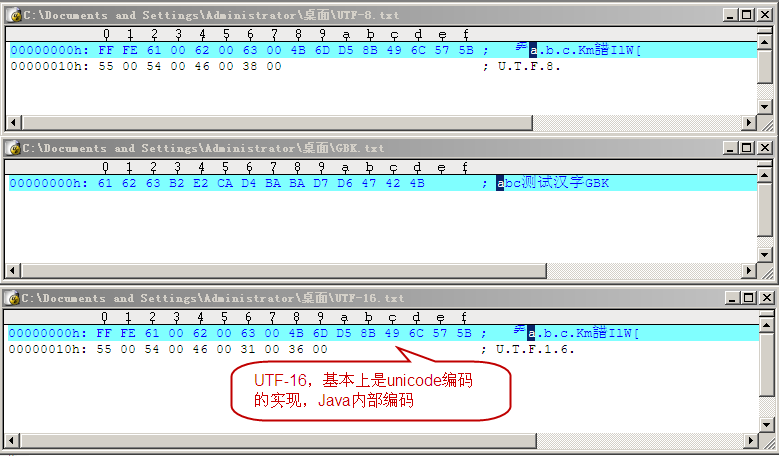
通过 UltraEdit 查看字符 UTF-8 和 GBK 编码的二进制形式:
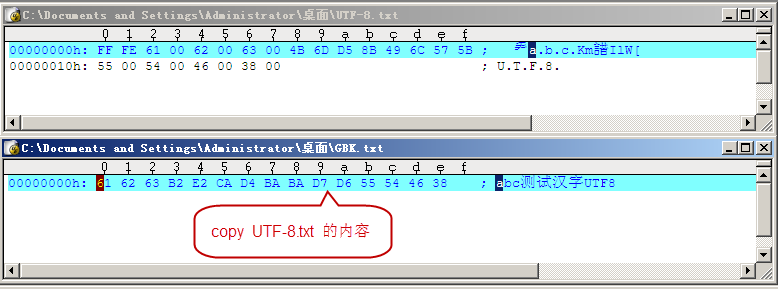
将UTF-8.txt 的内容 Ctrl+a, Ctrl+c 拷贝到GBK.txt ,通过二进制显示:
2、读取编码为UTF-8的文件(UTF-8.txt),写入采用系统默认编码(GBK)的文件,分析乱码产生的原因并消除。
public static void main(String[] args) {
utf8ToGbk();
utf8ToGbk_2();
utf8ToGbk_3();
}
static void utf8ToGbk(){
String text = read("UTF-8.txt");
write("utf8ToGbk.txt", text);
System.out.println(text);
}
//文件为 UTF-8 编码,而读取默认用 GBK 编码,所以要强制转换为 UTF-8
static void utf8ToGbk_2(){
String text = read("UTF-8.txt");
try {
text = new String(text.getBytes("GBK"),"UTF-8");
} catch (UnsupportedEncodingException e) {
System.err.println("Encodeing Error!");
}
write("utf8ToGbk_2.txt", text);
System.out.println(text);
}
//直接指定读取文件采用 UTF-8 编码
static void utf8ToGbk_3(){
String text = read("UTF-8.txt", "UTF-8");
write("utf8ToGbk_3.txt", text);
System.out.println(text);
}utf8ToGbk.txt(在Eclipse中显示为乱码,采用Windows默认文本打开正常)
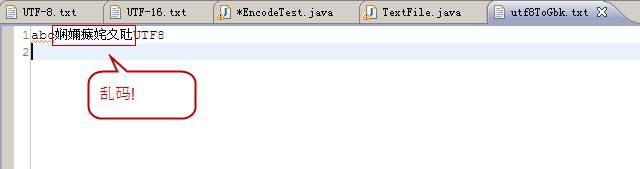
分析,编码转换过程如下:
UTF-8(文件内容) --> GBK(读取流) -->Unicode(Java内存,这里出错了) -->GBK(文件)
错误原因:UTF-8 的数据被错误的当成 GBK 的数据转换成 Unicode
utf8ToGbk_2.txt(正常)

分析,编码转换过程如下:
UTF-8(文件内容) --> GBK(读取流) --> UTF-8(强制转换) --> Unicode(Java内存) -->GBK(文件)
utf8ToGbk_3.txt(正常)

分析,编码转换过程如下:
UTF-8(文件内容) -->UTF-8(读取流) --> Unicode(Java内存) -->GBK(文件)
总结:要使其不产生乱码,只要满足在转换成Unicode前还原为原编码即可!形成了一个完美的圈!
其余代码:
//默认GBK编码
public static String read(String fileName){
StringBuilder sb = new StringBuilder();
try {
BufferedReader in = new BufferedReader(new FileReader(fileName));
try {
String s;
while((s = in.readLine())!=null){
sb.append(s);
sb.append("\n");
}
} finally{
in.close();
}
} catch (IOException e) {
e.printStackTrace();
}
return sb.toString();
}
//指定编码{charset}
public static String read( String fileName, String charset ){
StringBuilder sb = new StringBuilder();
BufferedReader in = null;
try {
in = new BufferedReader( new InputStreamReader( new FileInputStream(fileName), charset));
String s = null;
while( (s = in.readLine()) != null ){
sb.append(s);
sb.append("\n");
}
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
finally{
if( in != null ){
try {
in.close();
} catch (IOException e) {}
}
}
return sb.toString();
}
//默认编码
public static void write(String fileName, String text){
try {
PrintWriter out= new PrintWriter(fileName);
try {
out.print(text);
}finally{
out.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}3、Web 中文乱码解决方案
3.1、以 POST 方法提交的表单数据中的中文字符
由于Web容器默认的编码方式是ISO-8859-1,在Servlet/JSP 程序中,通过请求对象的 getParameter( ) 方法得到的字符串是以 ISO-8859-1 转换而来,这是导致乱码产生的原因之一。
为了避免容器以 ISO-8859-1 的编码方式返回字符串,对于以POST 方法提交的表单数据:
在获取请求参数之前,调用 request.setCharacterEncoding( "GBK" ),指明请求正文使用的字符编码是GBK。
向浏览器发送中文数据之前,调用response.setContentType( "text/html;charset=GBK" ),指定输出内容的编码方式是GBK。
对 JSP 页面,如下:
<% request.setCharacterEncoding("GBK"); %>
<%@ page contentType="text/html; charset=GBK" %>
3.2、以 GET 方法提交的表单数据中的中文字符
当提交表单采用 GET 方法时,提交的数据作为查询字符串被附加到 URL 的末端,发送到服务器,此时在服务器端调用 setCharacterEncoding() 方法也就没有作用了。我们需要在得到请求参数的值后,自己做正确的编码转换。
String content = request.getParameter("content");
content = new String(content.getBytes("ISO-8859-1"),"GBK");GBK----------->ISO-8859-1-->Unicode------------------------------------>ISO-8859-1---->GBK---->Unicode
(浏览器) (传输) (getParameter(),Java内存中) (getBytes("ISO-8859-1"))
由于 ISO-8859-1 ----> Unicode ----> ISO-8859-1 是一个对称过程,因而可以简化为:
GBK ----> ISO-8859-1 ----> GBK ----> Unicode
3.3、在数据库中存储和读取中文数据
只需将数据默认编码格式改为支持中文的编码即可(如,GBK,UTF-8)
3.4、Servlet/JSP 在不同语言系统的平台下运行
有时候,我们在中文系统平台下开发的 Web 应用程序移植到英文系统平台下,在 Servlet 和 JSP 中直接书写的中文字符串在输出时,将显示为乱码。这是因为在编译Servlet类或者 JSP 文件时,如果没有使用 -encoding 参数指定 Java 源程序的编码格式,javac 会获取本地操作系统默认的字符集,以该字符集将 Java 源程序转换为 Unicode 编码保存到内存中,然后将源程序编译为字节码(UTF-8 编码),保存到硬盘上。
在英文平台下,采用的默认编码格式是 ISO-8859-1 ,所以在编译后,执行输出时,原先在源文件中书写的中文字符串就变成了乱码。
解决这个问题,在编译 Servlet 的源程序时,可以用 -encoding 参数指定为 GBK
javac -encoding GBK HelloServlet.java对 JSP 页面,只要在 page 指令中用 pageEncoding 属性指定编码格式为GBK,Web容器就可以正确转换和编译JSP文件了
<%@ page pageEncoding="GBK"%>
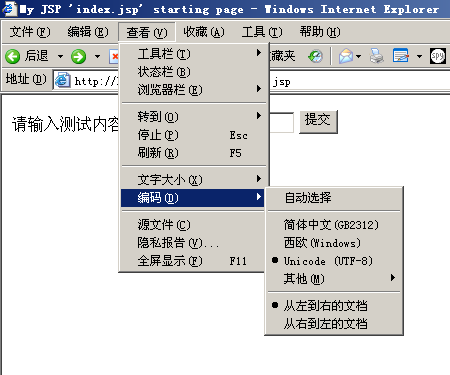
有关浏览器编码的问题,浏览器是用什么编码(GBK? GB2312? UTF-8? )来处理输入的字符?
浏览器会根据
<%@ page pageEncoding="UTF-8"%>
或
<%@ page contentType="text/html; charset=UTF-8" %>
来编码输入的字符,如图(它会根据不同的设定自动调整)















 7546
7546

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









