






一:引言
POSIX线程遵循一种共享状态的并发模型。在这种模型中,若干线程同时访问共享对象时,需要在线程间有合适的协调机制。特别是,需要以下特性来简化这种模型中的编程:
原子性访问:当某个线程正在修改共享对象时,需要避免另一个线程访问它;
内存可见性:一旦某个线程修改了共享对象,我们希望当修改发生后,在另一个线程中就能立即得到最新的状态。就像下图中描述的那样。
互斥锁通常被介绍为是一种保证原子访问的机制。但是实际上,锁不仅用于管理共享对象的访问,它还用于处理内存可见性的问题。接下来我们将看到,某些情况下,原子访问不成问题,但是内存可见性却至关重要。这种场景下,没有互斥锁的帮助,将会犯下严重的错误。
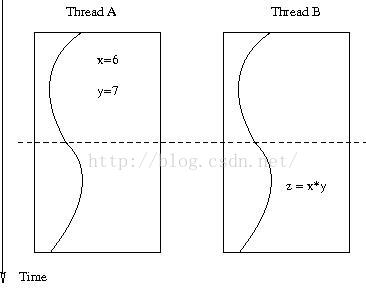
上图中,线程A设置x=6,y=7,接下来,在线程B中设置z=x*y。我们希望z是42.
二:Mutexes arefor sissy
考虑下面的“马拉松”程序。线程A会一直run(),直到它到达线程B设置的“终点线”。所谓“终点线”是通过arrived标志位来表示的。
volatile bool arrived = false;
volatile float miles = 0.0;
/*--- Thread A ----------------------------------------*/
while (!arrived)
{
run();
}
printf("miles run: %f\n", miles);
/*-----------------------------------------------------*/
/*--- Thread B ----------------------------------------*/
miles = 26.385; // 42.195 Km
arrived = true;
/*-----------------------------------------------------*/
这里对于arrived标志位的访问,并没有使用互斥锁。我曾经多次见到这样的代码,而且听到过下面的理由:
a:我们不需要互斥锁,因为这里仅有一个线程读,一个线程写;
b:即使这里我得到的是arrived的脏数据,它也是非零的,因此在C中也是为“真”的,所以循环依然会如期停止。原子性在这里并非一个问题,所以我们不需要互斥锁;
c:该示例中,互斥锁只是增加了代码的行数,并且减慢了程序的运行速度;
d:我经过了压力测试,程序如期的工作;
以上所有的理由,尽管在特定平台下可能是正确的。然而上面的代码仍然是错误的,当移植到另一个平台时,程序可能以非常微妙的方式失败。
三:硬件优化
某些平台上,线程A可能会如期停止,但是打印出的miles却是0.0。而在某些平台上,即使线程B中设置了arrived为true,但线程A可能也不会停止循环。
造成这种奇怪行为的原因是硬件。更确切的说,是因为在处理器访问内存时,硬件进行了某种优化措施。
通常而言,处理器从内存中取的一条数据,要比执行其他指令更慢。所以这里内存就成了性能瓶颈,因此硬件工程师们想出了聪明的办法来提高速度:首先就是使用缓存(cache)来加快访问。然而,这种优化带来了额外的复杂性:
a:当缓存不命中时,处理器依然需要访问更慢的内存;
b:在多核系统中,我们需要一个协议来维持缓存一致性(cache coherency)。
1:乱序执行
我们知道为了提高代码的执行速度,编译器可能会对指令进行重排序。然而你也许不知道,为了应对上面所说的问题,现代的处理器也会随手对指令进行重排序。
参考下面的伪汇编指令:
mov r1, mem // load mem cell to register r1
add r1,r1,r2 // r1 = r1+r2
add r3,r4,r5 // r3 = r4+r5
可能内存单元mem没有被缓存,因此需要从内存中获取。这种情况下,处理器可以按照下面的方式对指令进行重排序,以优化处理速度:
处理器执行第(1)条指令,但并不等待它的完成;
一旦第(1)条指令执行完成,就立即执行第(2)条指令;
第(3)条指令会立即执行,因为它所涉及的操作数是可得的,并且与前两条指令无关;
所以,处理器可能会按照下面的顺序执行指令:(3)-(1)-(2)。这样做的优势在于:在执行耗时的内存操作之前,处理器可以执行其他更有用的工作,从而提高执行速度。这种优化对于执行指令的线程而言,是完全透明的(也就是乱序对于当前线程而言是没有影响的)。
然而,这种重排序可能会影响到其他线程。考虑上面的代码,线程B中,因为重排序,arrived可能会在miles变量之前被置为true,这样,线程A停止循环,打印miles的值时,该值可能还没有被设置……
2:存储缓冲(Store Buffer)
在一个多核系统中,当CPU写入共享内存单元时,事情可能变得更加微妙。为了保证所有核对于该内存单元维护同一个值,必须要有一个协议,保证其他CPU核缓存的该内存单元的值成为无效值。这种协议会使得CPU写数据变得更慢。
此时,硬件工程师们又站了出来,提出了一个聪明的想法:将写请求缓存到一个被称为存储缓冲(store buffer)的硬件队列中。缓存的所有请求,将会在之后某个方便的时间点,一下子全部(in one fell swoop)应用到内存上。
这个所谓的“方便的时间点”,对于我们开发软件的人而言就带来了问题。比如上面的马拉松程序,有可能将arrived=true在存储缓冲中排队之后,并没有应用到内存上,从而线程A不能得到其最新的值,导致其一直运行下去……
四:内存屏障
以上我们看到了,在现代硬件系统上可能会出现的奇怪的事情,这不是我们所期望的好的内存可见性。在这样的系统上如何能编写稳健的程序呢?
这就是内存屏障(memorybarriers, membars, memory fences, mfences)的作用所在。所谓内存屏障,是一种特殊的处理器指令,作用在于:
a:flush存储缓冲;
b:内存屏障之前所有挂起的操作都会执行完成;
c:内存屏障之后的指令不会进行重排序;
通过使用内存屏障,可以保证所有的重排序都已完成,所有挂起的写操作都已执行。因此其他线程的数据一致性得以保证,从而保证了良好的内存可见性。而且:互斥锁的实现中,使用了我们所需要的内存屏障……
如果你对内存屏障和硬件优化有兴趣的话,建议读一下Paul McKenny的论文(http://www.rdrop.com/users/paulmck/scalability/paper/whymb.2009.04.05a.pdf)。
五:实际的例子
之前的讨论较为理论,本节中我们来看一个具体的,因为没有正确的内存可见性而导致奇怪结果的例子。
下面的代码中,创建了2个线程。使用了全局变量Arun和Brun,使用Pthreadbarrier(不是内存屏障!,其实不用也可以)保证两个线程同时启动。一旦两个线程都结束后,应该能保证条件(Astate==1 || Bstate==1)为真。如果该表达式为假,则打印出一条信息。
/*------------------------------- mutex_01.c --------------------------------*
On Linux, compile with:
cc -std=c99 -pthread mutex_01.c -o mutex_01
Check your system documentation how to enable C99 and POSIX threads on
other Un*x systems.
Copyright Loic Domaigne.
Licensed under the Apache License, Version 2.0.
*--------------------------------------------------------------------------*/
#define _POSIX_C_SOURCE 200112L // use IEEE 1003.1-2004
#include <unistd.h> // sleep()
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
#include <string.h> // strerror()
#include <errno.h>
/***************************************************************************/
/* our macro for errors checking */
/***************************************************************************/
#define COND_CHECK(func, cond, retv, errv) \
if ( (cond) ) \
{ \
fprintf(stderr, "\n[CHECK FAILED at %s:%d]\n| %s(...)=%d (%s)\n\n",\
__FILE__,__LINE__,func,retv,strerror(errv)); \
exit(EXIT_FAILURE); \
}
#define ErrnoCheck(func,cond,retv) COND_CHECK(func, cond, retv, errno)
#define PthreadCheck(func,rc) COND_CHECK(func,(rc!=0), rc, rc)
/*****************************************************************************/
/* real work starts here */
/*****************************************************************************/
/*
* Accordingly to the Intel Spec, the following situation
*
* thread A: thread B:
* mov [_x],1 mov [_y],1
* mov r1,[_y] mov r2,[_x]
*
* can lead to r1==r2==0.
*
* We use this fact to illustrate what bad surprise can happen, if we don't
* use mutex to ensure appropriate memory visibility.
*
*/
volatile int Arun=0; // to mark if thread A runs
volatile int Brun=0; // dito for thread B
pthread_barrier_t barrier; // to synchronize start of thread A and B.
/*****************************************************************************/
/* threadA- wait at the barrier, set Arun to 1 and return Brun */
/*****************************************************************************/
void*
threadA(void* arg)
{
pthread_barrier_wait(&barrier);
Arun=1;
return (void*) Brun;
}
/*****************************************************************************/
/* threadB- wait at the barrier, set Brun to 1 and return Arun */
/*****************************************************************************/
void*
threadB(void* arg)
{
pthread_barrier_wait(&barrier);
Brun=1;
return (void*) Arun;
}
/*****************************************************************************/
/* main- main thread */
/*****************************************************************************/
/*
* Note: we don't check the pthread_* function, because this program is very
* timing sensitive. Doing so remove the effect we want to show
*/
int
main()
{
pthread_t thrA, thrB;
void *Aval, *Bval;
int Astate, Bstate;
for (int count=0; ; count++)
{
// init
//
Arun = Brun = 0;
pthread_barrier_init(&barrier, NULL, 2);
// create thread A and B
//
pthread_create(&thrA, NULL, threadA, NULL);
pthread_create(&thrB, NULL, threadB, NULL);
// fetch returned value
//
pthread_join(thrA, &Aval);
pthread_join(thrB, &Bval);
// check result
//
Astate = (int) Aval; Bstate = (int) Bval;
if ( (Astate == 0) && (Bstate == 0) ) // should never happen
{
printf("%7u> Astate=%d, Bstate=%d (Arun=%d, Brun=%d)\n",
count, Astate, Bstate, Arun, Brun );
}
} // forever
// never reached
//
return EXIT_SUCCESS;
}
运行代码,得到的结果如下:
61586> Astate=0, Bstate=0 (Arun=1, Brun=1)
670781> Astate=0, Bstate=0 (Arun=1, Brun=1)
824820> Astate=0, Bstate=0 (Arun=1, Brun=1)
1222761> Astate=0, Bstate=0 (Arun=1, Brun=1)
1337091> Astate=0, Bstate=0 (Arun=1, Brun=1)
1523985> Astate=0, Bstate=0 (Arun=1, Brun=1)
2340428> Astate=0, Bstate=0 (Arun=1, Brun=1)
2400663> Astate=0, Bstate=0 (Arun=1, Brun=1)
导致这种结果的,只能是内存可见性问题。gcc生成的线程A的汇编代码如下,可见对于Arun和Brun的访问都是原子的:
threadA:
.LFB2:
pushq %rbp
.LCFI0:
movq %rsp, %rbp
.LCFI1:
subq $16, %rsp
.LCFI2:
movq %rdi, -8(%rbp)
movl $barrier, %edi
call pthread_barrier_wait
movl $1, Arun(%rip)
movl Brun(%rip), %eax
cltq
leave
ret
六:POSIX内存可见性规则
IEEE1003.1-2008在XBD 4.11 Memory Synchronization(http://pubs.opengroup.org/onlinepubs/9699919799/basedefs/V1_chap04.html#tag_04_11)中,定义了内存可见性的规则。正确的POSIX实现能够保证:
a: pthread_create,调用pthread_create之前设置的变量,在新创建的线程中是可见的。但是在pthread_create调用之后设置的变量不保证新线程中的可见性,即使该操作在线程启动之前执行;
b:pthread_join:在线程终止之前设置的变量,在其他线程成功调用pthread_join之后就是可见的;
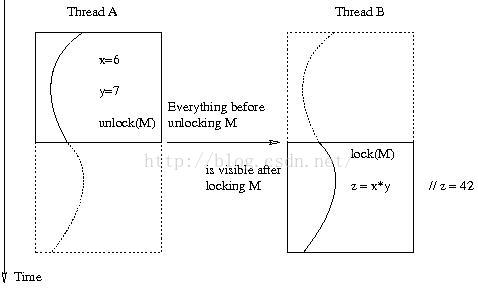
c:某个线程在解锁之前设置的变量,其他线程同一个锁加锁之后就是可见的。如果是不同的锁,或者根本不使用锁,或者在pthread_unlock之后设置的变量,则不保证可见性。如下图:
七:结论
读完本文后,你就可以理解在CertPOS03-C(https://www.securecoding.cert.org/confluence/display/c/CON02-C.+Do+not+use+volatile+as+a+synchronization+primitive)中指出的:不要用volatile作为同步原语的意思了。
因此,只要遵守POSIX内存可见性规则,就能保证程序的正确性。一个线程写,另一个线程读时,即使能保证原子访问的情况下,也需要一个互斥锁来正确的同步内存访问,。
原文:
http://www.domaigne.com/blog/computing/mutex-and-memory-visibility/
更多关于内存可见性的讨论,可以参考《Programming With Posix Threads》第3.4节。
有关内存屏障的概念,可以参考文章《内存屏障什么的》:
http://www.spongeliu.com/233.html
关于多线程中要慎用volatile,参考:
关于顺序一致性和cache一致性,参考:















 259
259

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









