




 本文探讨了一种在区块链中减少数据存储的方法Jigsaw-likeDataReduction(Jidar),通过让用户各自存储与其相关的交易数据,同时利用Bloomfilter验证交易有效性,以降低存储需求。文章还涉及了多实例策略和时间窗口机制来处理数据查询和网络故障。存储优化以计算和通信成本为代价,Bloomfilter大小对系统性能有影响。
本文探讨了一种在区块链中减少数据存储的方法Jigsaw-likeDataReduction(Jidar),通过让用户各自存储与其相关的交易数据,同时利用Bloomfilter验证交易有效性,以降低存储需求。文章还涉及了多实例策略和时间窗口机制来处理数据查询和网络故障。存储优化以计算和通信成本为代价,Bloomfilter大小对系统性能有影响。
这篇文章中提出了一个减少区块链中数据存储的方法,Jigsaw-like Data Reduction Jidar
简单来说就是每个ueser 各自存储自己的数据和感兴趣的数据。需要的时候再像拼图一样给拼回去。每个节点维护自己需要的数据,不需要信任假设。
cub 只适合用在联盟链中,信任假设太强了。
还有一些减少数据存储的方式,是从数据库的角度出发的,但是区块链中交易的冗余信息比较少,压缩的效果并不好。
再一个,能不能不要每个设备都存储相同数量的数据,每个设备可以根据自己的需要存储数据。
With Jidar, only data of interest is stored in each node.
如果要扫描所有的数据,需要向所有的节点进行请求并拼成完整的block,但是如果有的node存储了block就是不响你的查询请求,应该如何是好?
- An approach aiming to reduce the data storage is elaborated, without making any trust assumptions nor sacrificing the original properties of blockchains. 在不做任何信任假设、不牺牲原有特性的前提下,减少数据的存储量
GOAL 1: Storage size for a user should be in proportion to the number of transactions related to him/her, so as to get reduced largely.
GOAL 2: Data should be stored by the stakeholders respectively, which is consistent with what in our real life and accords with the protection of data ownership.
GOAL 3: Few assumptions about the trust among users should be made, so as to reserve the original advantages of Bitcoin.
每个节点只保留和他相关的交易,以及交易的merkle branch。
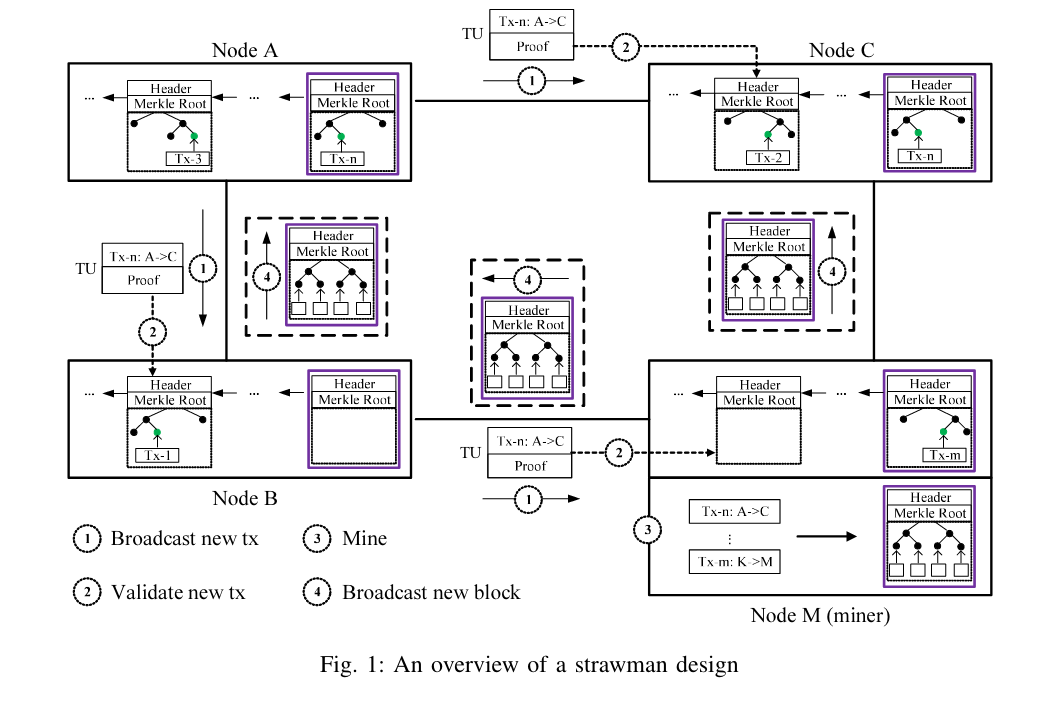
如图1中,A 向 C 进行转账,A提出交易Txn,当Txn被打包到区块中,节点B只保留这个区块的头
,因为没有他所涉及到的交易,但是A C 分别保留了区块头,交易txn 和txn的merkle branch。
如何验证双花?如何证明之前的交易没有被花费过?
使用 Bloom filter,Bloom Filter 可以根据交易的hash值指明这笔交易是否已经在某个block中被花过。
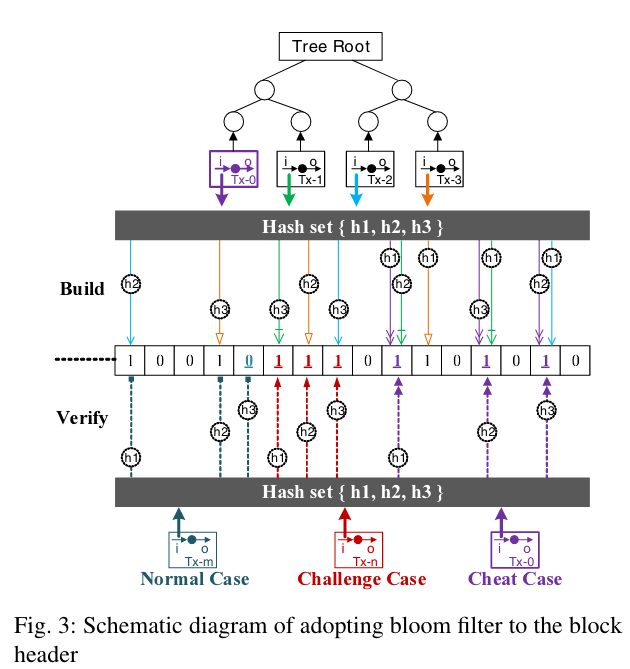
如果交易在这个区块中被花掉了,那么这这笔交易取hash,对相应的bloom filter的位赋值1,如build 步骤所示。
当验证的时候,只需要验证bloom filter中是否为positive,当然 bloom filter 最关键的就是会出现 false positive,就是这笔交易没有在这个区块中花过,但是确被误认为在这儿区块中花过了。
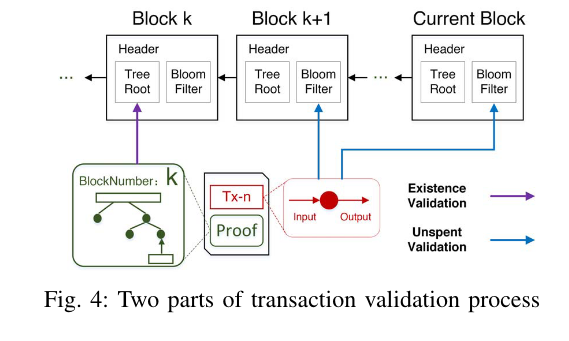
在对一笔交易的有效性进行验证时,需要进行两种验证方式,一是验证转账输入是存在的 Existenc
Validation 二是验证没有被花费过 Unspent validation
如果验证存在,只需要找到交易所在的k区块的块头就好了。
但是如果验证没有被花费过,需要从k+1区块,到最近的区块扫描所有的 bloom filter。这个方法的缺点是计算代价太大。
之前说了bloom filter 存在 false positive 的情况,如何解决
节点可以发布交易,节点对收到的block 进行检查,如果检查block 对于 他的UTXO中的交易存在 flase positive 的情况,则将这个block 的完整的merkle tree进行保留,并且在交易的时候作为proof 发送出去。
这样做计算的代价太大。
如何查询本地没有的数据?
因为node可能因为断网等原因再试无法连接。
根据断开的时间长短,长于时间T 和短于时间T 分成 short-term crash long-term crash。
时间窗口
设置一个时间窗口,每个节点都完整保留T 时间内的block,如果有节点在T内恢复,可以从临近节点请求缺失的数据
多实例
每个用户维护多个node,以防止node crash
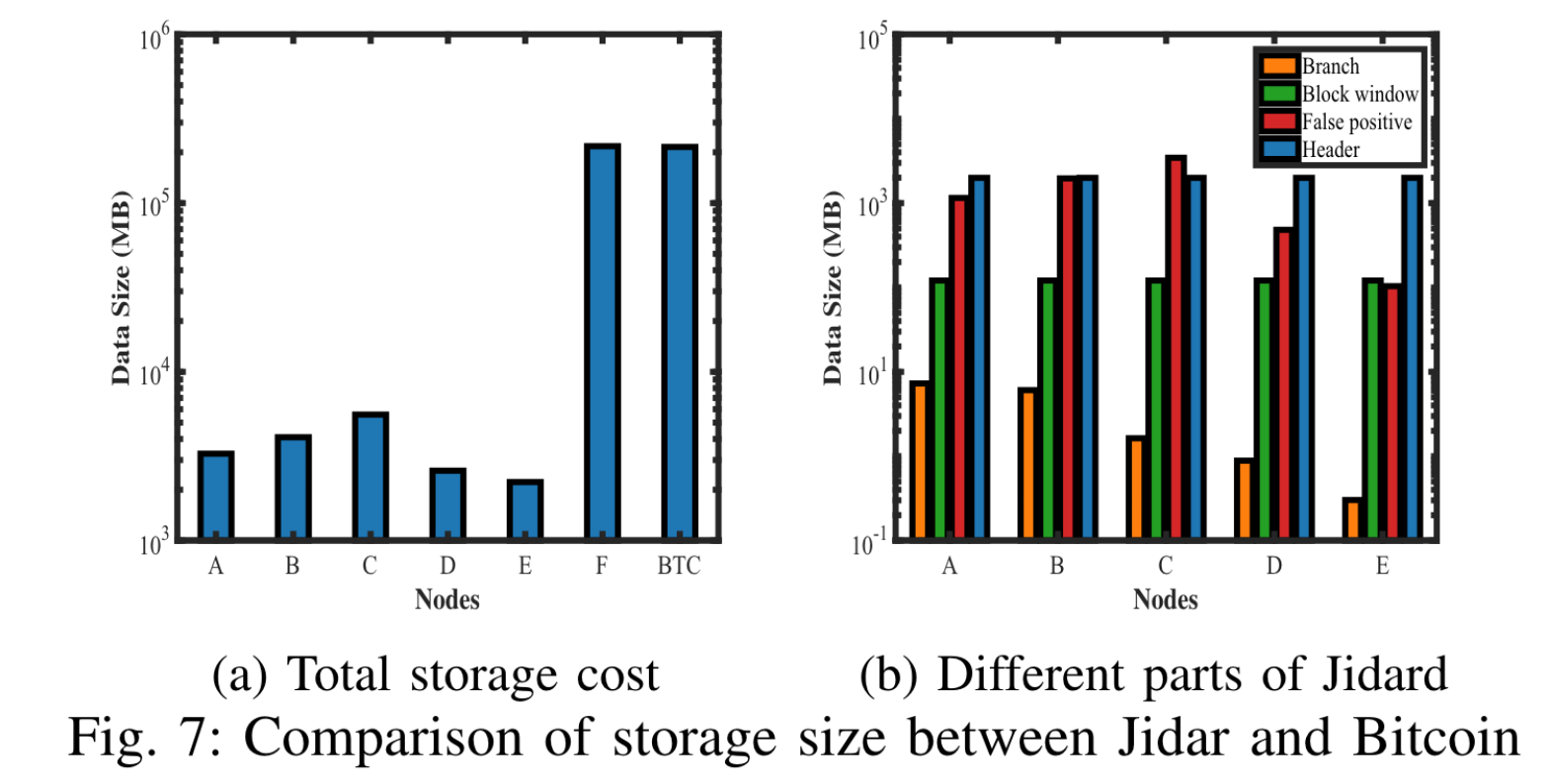
Jadard 减少存储是以计算量和通信量为代价的。
bloom filter选取的大小也会验证影响系统的性能,UTXO 集合越大,bloom filter 也应越大,否则fasle positive的概率也会越大。

















 1302
1302




 到【灌水乐园】发言
到【灌水乐园】发言







