







在《聊聊大数据(一)》中,笔者大致介绍了一下大数据的概念、特点以及一般数据库软件的存储思路。那么,如何快速地完成大数据的读取哪?在写入数据的同时还能够快速实时地读取大数据信息进行后续操作哪?本篇就来进行简单的讨论,提出一种实现思路。
我们都知道,提起大数据,数据量一定不是几万条数据这么简单的,至少是以千万条级记录开始起算的。这么大的数据量,通过传统数据库索引的方式已经捉襟见肘了。传统大型关系型数据库(除过MySQL外,因为上篇提到了,它有专门针对大表存储的解决方案。而且,MySQL是否算是大型关系型数据库可能会引起争议)如果不做特殊自行处理的话,基本都是会将所有的数据存储到一张单表里的。这样当单表的数据量达到几千万数量级以后,读写性能都会出现明显的下降。如果不采用单表存储的模式,自行拆分表会带来很大的维护工作,同时当要查询的数据分布在多张表时查询的性能也会大打折扣。
特别是对于几千万级记录数的单表读取,最直接的办法就是创建索引。但是索引的适用范围也是有限的,当记录数在千万级以内的话,对整形主键字段创建索引,查询或排序的效率还是很明显的。但是当单表的记录数达到几千万级以后,通过给主键字段创建索引,效果已经没有那么明显了。更不要说对名称等字符型字段创建索引了。
对于MongoDB这种最像关系型数据库的非关系型数据库来说,情况要好很多。通过给常用的字段创建索引,可以百倍地提升检索和查询效率。但当单表的记录数(MongoDB里叫文档个数更为贴切)再往上涨到一亿条以后,MongoDB也会显得有些力不从心了。
传统关系型数据库还有一种解决办法,那就是通过“读写分离”及“Master-Slave”的模式,将数据的写入节点和读取节点分开,从而最大限度地保证数据的读取速度。具体来说如下图所示:
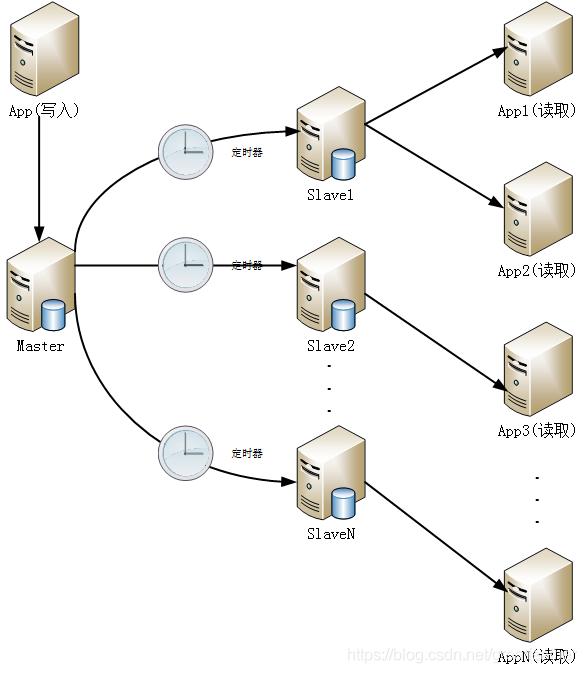
这也就是说,因为同时对一个数据库进行读写操作,磁盘上的磁头会来回在盘片上进行寻址及写入/读取操作,而磁头一般都是单向旋转的,所以一旦读写的并发量或数据量一大,效率就会急剧下降。那好了,我们就将数据库拆分成两个或多个数据库,一个专门用来写,其他的专门负责读。然后从库定期或不定期地从主库中同步最新的数据。这样既保证了写入速度,又保证了读取的速度,可谓一举两得。这种看似完美的解决方案其实隐含了一个问题——数据一致性问题。就是当数据被写入主数据库后,并不能在第一时间同步到从数据库中。所以对于一般的非实时型业务场景或者对读取操作性能要求高而对写入操作性能要求不高的场景来说,这种方案还是可以满足要求的,但对实时要求特别高,且数据一致性要求也较高的业务场景来说,这种方案就无法满足了。
还有一种情况,那就是对于读写速度要求都不高,但是对统计汇总数据读取性能要求较高。此时如果对单表或多表的数据进行一次统计汇总操作的话,会花费很长时间。这种操作用户在前端是无法忍受的。此时,就引入了另外一个技术思路——将费时的汇总结果(包括视图)持久化到物理表里,这样以后再查询时就非常快了。只不过这样做同样有个前提——那就是对统计汇总结果的更新频率要求不高。因为将统计汇总的结果写入物理表中的操作不会马上执行,而同样会是定期执行。这样当数据发生变化时,统计结果的使用者短期内无法感知到数据的变化。
为了解决传统关系型数据库读写速度总是不能“两全”的问题,另一个软件——Redis隆重登场了!
Redis是一种内存型数据库,同时也是非关系型数据库。它将数据以“Key-Value”键值对的方式存储在内存中。因为内存的速度是非常快的,所以可以做到瞬间读写。这样我们就可以通过Redis将访问频率较高的原始数据或汇总数据存放到Redis中。这样在不考虑网络延时的情况下,前端就可以以秒级的速度拿到所需的数据。
而面对数据写入的问题,Redis同样比传统的读写分离方案更具优势。在传统读写分离方案写入数据库的基础上,将最新的数据同样往Redis里写入一份。这样无论是原始数据还是汇总数据,数据的使用者都可以在第一时间感知到数据的变化(学名叫“数据最终一致性原则”)。
其实,这套方案是借鉴了计算机硬件中IO缓冲区的思路,将Redis作为了一个缓冲区。从而解决了读写速度不一致的问题。那么使用Redis有没有问题哪?也有。虽然这套方案看似完美,但不要忘了Redis是内存型数据库(易失),虽然Redis有持久化机制,但对于一般的程序猿来说,如何平衡Redis的效率与持久化之间的关系就略显困难了。同时,一旦Redis出了问题,整个应用或站点就趴窝了。
不过,既然Redis已经成为了业界事实上的标准软件,这个问题自然有解决方案。那就是对Redis也采用集群机制,不要把鸡蛋都放在一个篮子里(相应的也不要把Redis使用的集群工作节点全部放在同一个机器上,这样就失去了Redis集群的意义了)。如此一来就保证了站点的高可用性:
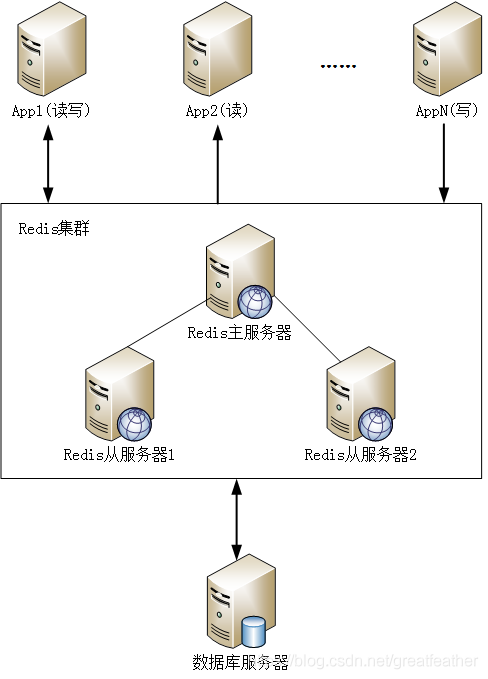
说明:上图中的Redis集群仅为示意,由于篇幅限制本文对Redis集群不做详细介绍,有兴趣的同学可以自行百度各种大神们的方案。
通过Redis来缓存数据还有一个好处,那就是对于习惯了MVC编程的人来说,后端无需再通过DAO层去数据库里读取原始数据,再封装成前端需要的JSON等信息组织格式,而是可以直接将最终的JSON格式的结果字符串直接保存到Redis的Value中。这样一来又可以进一步加快前后端的交互速度。
以上就是笔者近几年来对于大数据快速读写总结出的一套方案。
上述方案还有一个小Bug,就是系统初始化时,因为Redis里还没有数据,所以用户访问大数据时还会比较慢。对于这个问题,有两种思路:一种思路是在系统启动时,将用户所有需要读取的值一次性计算完毕后放到Redis里;另一种思路是在系统启动时不计算,而在用户请求时再予以计算。这两种思路各有优缺点,都不是完美的解决方案。
解决的办法就是将两者结合起来使用。即对于大多数人都会使用的变量,在系统启动时还是要计算完毕;而对于个别用户使用的变量,可以放到用户第一次请求时再去计算。这样就在系统启动时间和用户体验感之间找到了平衡。
以上就是笔者一点心得体会,欢迎各位吐槽交流,亦或是分享一下自己的宝贵经验。














 1701
1701











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









