







TF-IDF算法
什么是TF-IDF?
维基百科定义:TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与文本挖掘的常用加权技术。它是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
简单来说,TF-IDF由两个部分组成,即词频(TF)和逆文档频率(IDF)。词频即一个词语在文件中出现的次数。逆文档频率是指在词频的基础上,对每个词分配一个权重,该权重反映着词汇的重要程度。如停用词(‘的’、“了”,“是”等)对于找到结果毫无帮助,其权重值(即逆文档频率)就会非常小。
我们将TF和IDF相乘,就会得到一个词的TF-IDF值。某个词对文章的重要性越高,它的TF-IDF值就越大。所以,排在最前面的几个词,就是这篇文章的关键词。
算法步骤
Step1:计算词频

Step2:计算逆文档频率
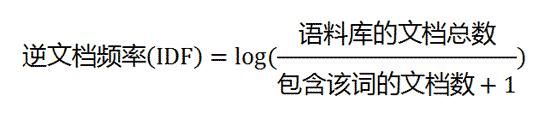
Step3:计算TF-IDF
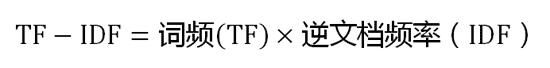
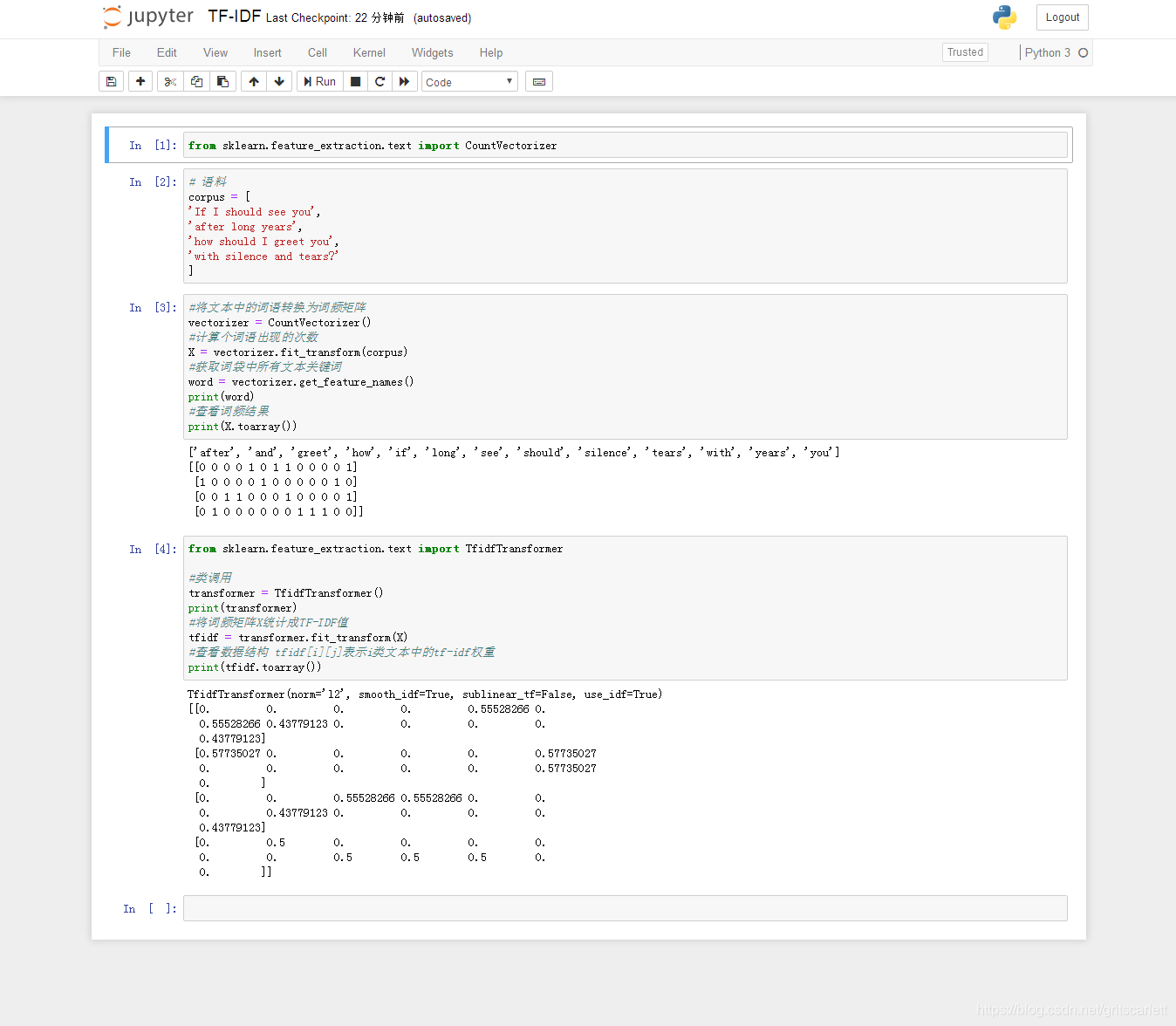
代码实现














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









