








1.背景
一直想自己动手写个web app玩玩,前几天看了一个github的resume自动生成的web-app,所以就动手仿造了一个csdn的简历生成器。结构很简单,前端是html/css文件(这个模仿了github的那个网页,因为博主不太懂前端)。后台是一个爬虫软件,可以把csdn的个人信息爬下来,然后显示出来,最后部署到了百度云。百度的云数据库,真是坑爹.......,我调试了半天,目前还无法insert数据。好了,先上个图,项目地址http://resumecsdn.duapp.com/。
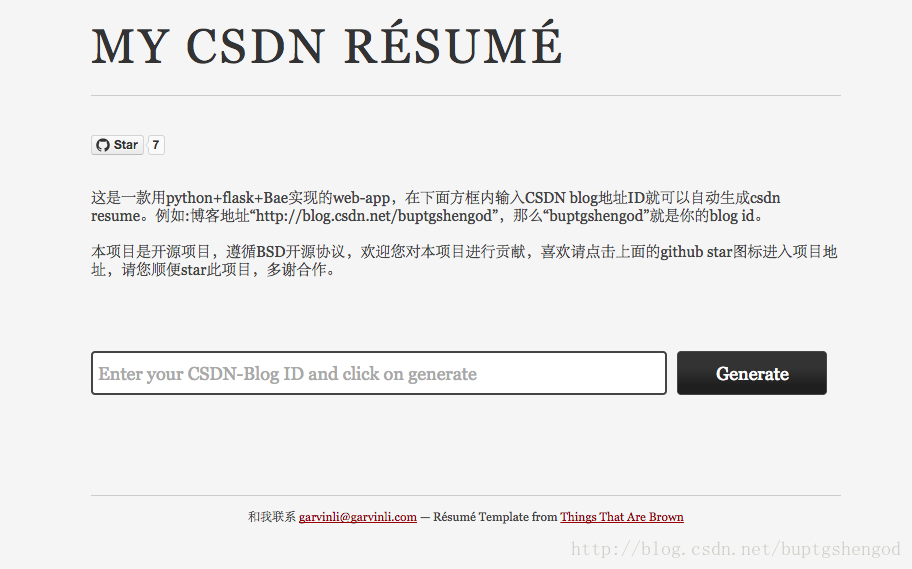
(1)起始页面
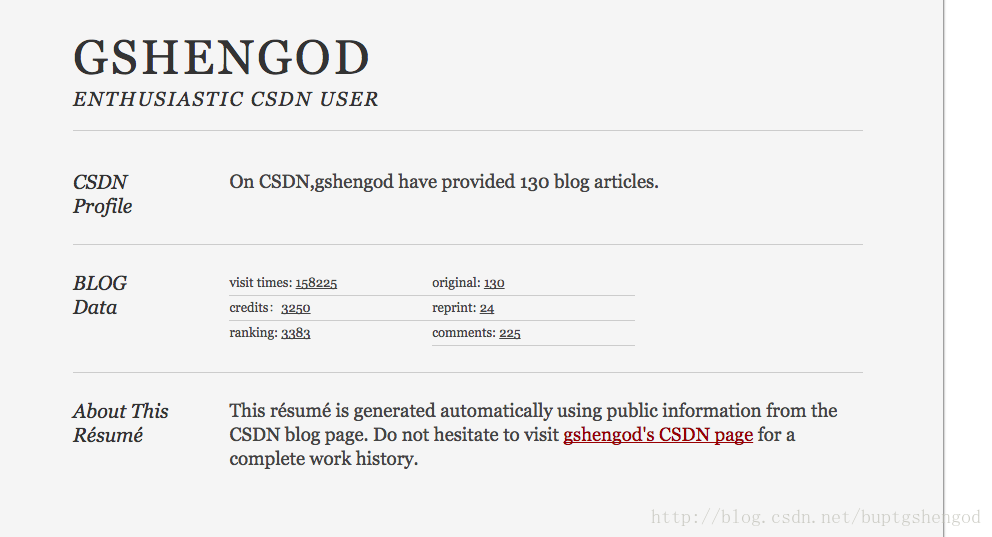
(2)生成的简历
2.项目介绍
(1)前端
前端主要就是html和css,这个我是参考别人的改的,有过代码经历的人应该都比较容易。前端和后台的交互,主要是通过先在html里设置method,然后就可以{{{data}}这样传输数据了,这个比较容易,大家在代码中一看就明白,不多说了。
(2)flask
flask是一个比较轻便的python web框架,博主本来打算用豆瓣那个的(豆瓣的后台是python写的),但是发现太难,所以转而用flask。flask的好处是很直接明了。
@app.route('/')
def home():
#mysql_manager.sql_connect()
return render_template('index.html')
@app.route('/signup', methods=['POST'])
def signup():
#session['username'] = request.form['username']
session['message'] = request.form['message']
return redirect(url_for('message'))
这个框架的好处是,基本看一眼例子就可以动手开搞了,推荐一个网站:http://maximebf.com/blog/2012/10/building-websites-in-python-with-flask/
(3)crawler
介绍一下crawler文件,也就是后台的爬虫文件吧。因为要伪装成是浏览器浏览,所以加了个head,这样可以避免一些反爬虫网站。剩下就是用urllib的函数加上正则匹配就比较容易搞定了。
headers = {
'User-Agent':'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'
}
req = urllib2.Request(
url='http://blog.csdn.net/'+name,
headers = headers
)
(4)部署到BAE
BAE怎么说呢,mysql功能文档很少,这点让我很不爽。但是其他功能还是可以的,特别是支持很多python的第三方库,可以在requirements.txt里面定义。
用法:注册一个账号,然后它会给你一个git地址,clone到本地。然后就可以修改了,当然,改好了还得push上去,每次修改都得点击“快捷发布”。

下面是一些要注意的地方:
1
.首先是app.conf,url要加星号。
handlers:
- url : /.*
script: __init__.py2.然后,把需要的第三方库加在requirements.txt里,这样bae会自动帮你安好。
flask
MySQL-python
3.注意本地调试,和放到BAE的区别
本地调试运行程序是以下语句__init__.py文件内,然后就可以在浏览器查看了
if __name__ == '__main__':
app.run()
放到BAE上要把本地调试的语句注释掉,在__init__.py里加上:
from bae.core.wsgi import WSGIApplication
application = WSGIApplication(app)
4.本地调试每次调完要注意kill线程,方法是在shell里:
lsof -i:5000然后在kill掉对应的ID号
--------------------------------------------------------------------------------------------------------------------------------------------------------
麻烦大家看的时候,给个star,拥有star100+项目一直是我的梦想
/********************************
* 本文来自博客 “李博Garvin“
* 转载请标明出处:http://blog.csdn.net/buptgshengod
******************************************/














 3154
3154











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









