









hugegraph安装的步骤
版本说明(都是最新版本 截止20200625)
| 组件名称 | 组件版本 |
|---|---|
| hugegraph-loader-0.10.1 | 0.10.1 |
| hugegraph-0.10.4 | 0.10.4 |
| hugegraph-studio | 0.10.0 |
| hugegraph-tools | 1.4.0 |
安装
#(可选)如果是单机测试,rocksDB需要gcc环境
# 如果使用的是RocksDB后端,请务必执行gcc --version命令查看gcc版本;若使用其他后端,则不需要
sudo yum install -y gcc
cd /home/hadoop/app/hugegraph
wget https://github.com/hugegraph/hugegraph-tools/releases/download/v1.4.0/hugegraph-tools-1.4.0.tar.gz # -O可指定下载名,解决文件名过长
wget https://github.com/hugegraph/hugegraph-loader/releases/download/v0.10.1/hugegraph-loader-0.10.1.tar.gz #loader包,后续有用
tar zxvf hugegraph-tools-1.4.0.tar.gz && tar zxvf hugegraph-loader-0.10.1.tar.gz
cd hugegraph-tools-1.4.0
bin/hugegraph deploy -v 0.10 -p /home/hadoop/app/hugegraph
rm -rf /home/hadoop/app/hugegraph/core/*.gz #清理一下包
#软链,方便区分和访问
ln -s hugegraph-0.10.4/ server && ln -s hugegraph-studio-0.10.0/ studio && ln -s hugegraph-loader-0.10.1/ load && ln -s hugegraph-tools-1.4.0/ tools
截图如下
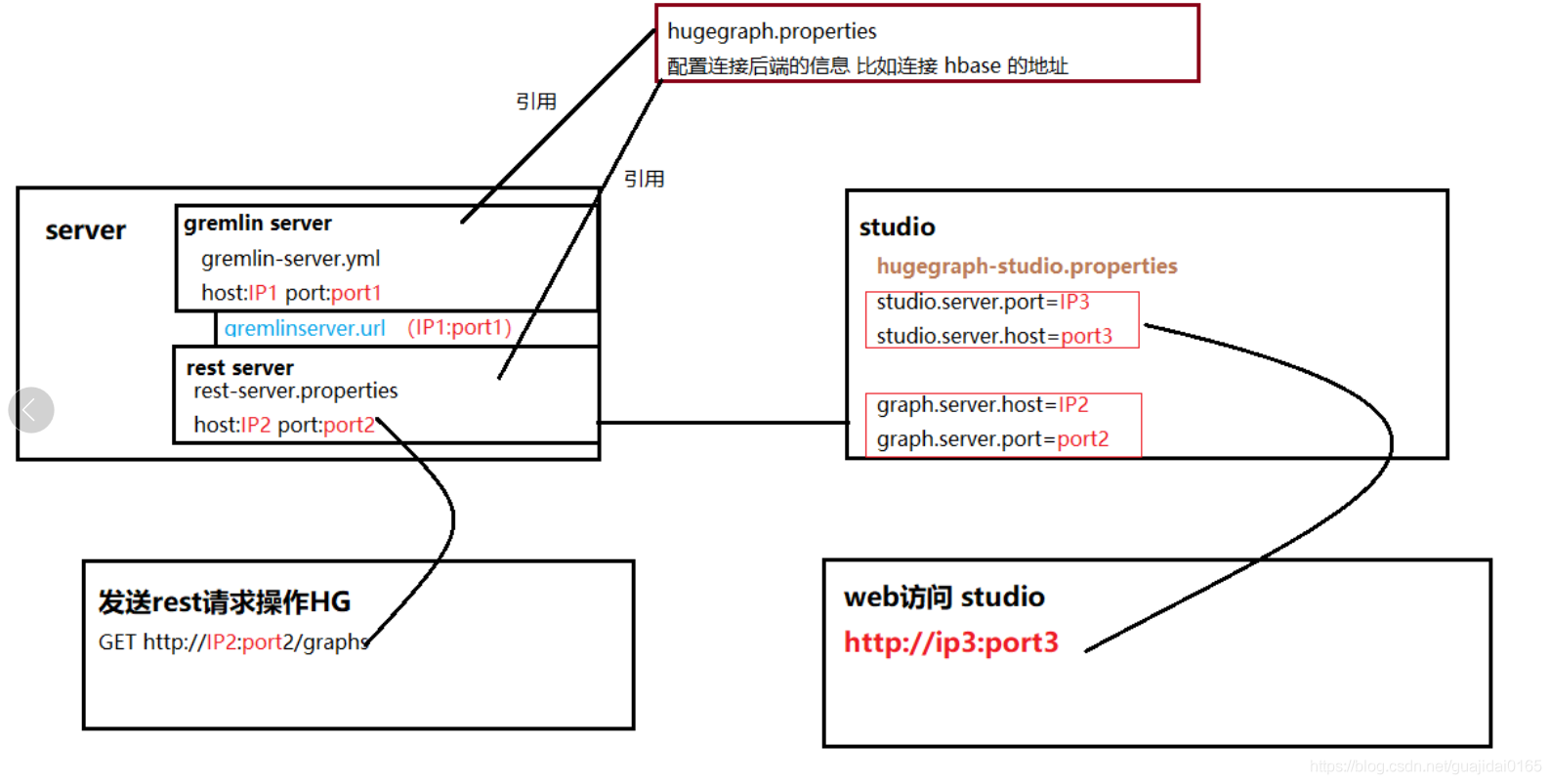
自己画的server和studio的架构图 有点丑
快速部署后, 默认启动的后端是调用的是配置文件内的rocksDB, 如果不是先终止修改一下, 并且修改一下默认的rest-server 地址, 详细配置可参考配置文档及配置项
启动server
#修改完成后, 手动启动一下server, 稳妥起见可以使用三部曲 :
/home/hadoop/app/hugegraph/server/bin/stop-hugegraph.sh
/home/hadoop/app/hugegraph/server/bin/init-store.sh
/home/hadoop/app/hugegraph/server/bin/start-hugegraph.sh
Graph 'hugegraph' has been initialized #必须出现这个提示,否则表结构可能不完整,请不要提前中断
#检验:jps可以看到HugeGraphServer
#再通过curl的方式检测一下http服务,注意就算本机访问自己, 注意: !!! yourIP不可以用localhost !!!
curl yourIP:8080/versions #提示下列说明正常.建议远端用postman也访问一下
#返回结果
{
"versions": {
"version": "v1",
"core": "0.10.4.0",
"gremlin": "3.4.3",
"api": "0.48.0.0"
}
}
#(可跳)这里我简单把几个脚本的核心放一下,方便之后对着源码去看入口点.
#1. stop-hugegraph.sh通过调用util.sh和stop-monitor.sh去完成 "check + kill" ,这里不单独列了
#2. init-store.sh的核心就是去执行InitStore,java类,传入了com.baidu.hugegraph.HugeFactory
exec $JAVA -cp $LIB/hugegraph-dist-*.jar -Djava.ext.dirs=$LIB/ \
com.baidu.hugegraph.cmd.InitStore $CONF/gremlin-server.yaml | grep "com.baidu.hugegraph"
#3. start-hugegraph.sh其实是 gremlin-server + rest-server 的整合, 主要是调用hugegraph-server.sh
注意, 再强调一下, 不同于JanusGraph直接暴露gremlin-server的接口, Hugegraph访问的方式是先发请求到huge-restserver ,然后rest-server判断出这属于gremlin语句, 再转发到gremlin-server, 外部是不能直接访问gremlin-server的. 这样的好处是可以在自己的server做不少封装和改动, 且不需要改动gremlin的源码
启动studio
/home/hadoop/app/hugegraph/studio
nohup bin/hugegraph-studio.sh &
# 查看nohup日志 即可看到访问地址 并且jps 也会有一个进程(Java+React写的)
HugeGraphStudio is now running on: http://node01:8086
使用studio前端创建图
这里参考官方的写法, 创建一个简单的人物关系图 . 在前端面板里复制下面语句, 创建 属性 -->顶点 --> 边 ,
//等下顶点和边要使用的属性,先创建一下,本质是groovy语法
graph.schema().propertyKey("name").asText().ifNotExist().create()
graph.schema().propertyKey("age").asInt().ifNotExist().create()
graph.schema().propertyKey("city").asText().ifNotExist().create()
graph.schema().propertyKey("lang").asText().valueSet().ifNotExist().create()
graph.schema().propertyKey("date").asText().ifNotExist().create()
graph.schema().propertyKey("price").asInt().valueList().ifNotExist().create()
//创建两个点结构
person = graph.schema().vertexLabel("person").properties("name", "age", "city").primaryKeys("name").ifNotExist().create()
software = graph.schema().vertexLabel("software").properties("name", "lang", "price").primaryKeys("name").ifNotExist().create()
//创建两条边结构
knows = graph.schema().edgeLabel("knows").sourceLabel("person").targetLabel("person").properties("date").ifNotExist().create()
created = graph.schema().edgeLabel("created").sourceLabel("person").targetLabel("software").properties("date", "city").ifNotExist().create()
//最后生成一些实际数据,比如最简单的"两点一边",最后一行需要一起添加,不然变量会识别不到,注意这是一条单向边, 但是可以反查..
jin = graph.addVertex(T.label, "person", "name", "jin", "age", 23, "city", "ShenZheng")
tom = graph.addVertex(T.label, "person", "name", "tom", "age", 22, "city", "HK")
jin.addEdge("knows", tom, "date", "20190104")
//指向另一个顶点
jin = graph.addVertex(T.label, "person", "name", "jin", "age", 23, "city", "ShenZheng")
c = graph.addVertex(T.label, "software", "name", "test" ,"lang","c","price",22)
jin.addEdge("created",c , "date","20190122", "city", "HK")
// 查询数据 截图如下
g.V()
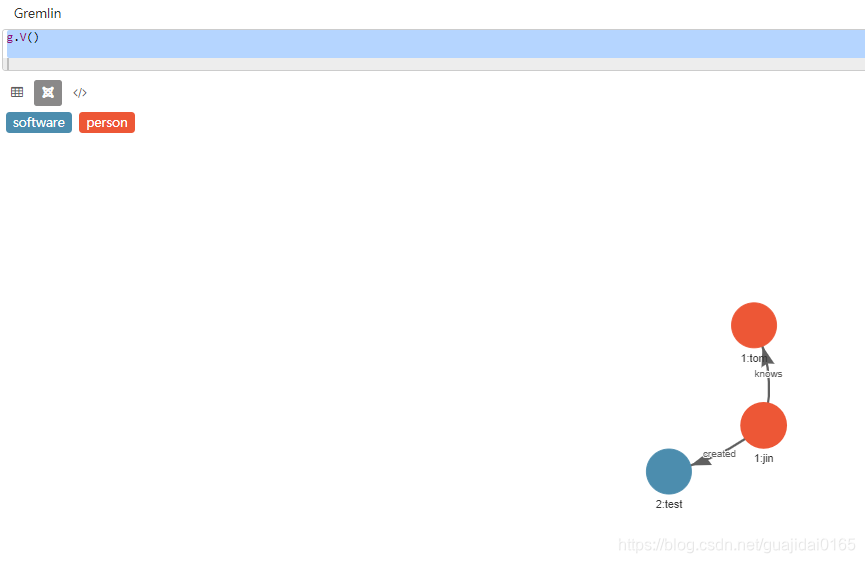
到此我们测试环境算是可以正常运行了 吃个饭继续写 端午节快乐哈!!!














 736
736











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









