







一转换经纬度使用百度地图api来操作。它是用这个提取的地址信息来提取,然后就是返回一个含经纬度的html
二感觉存储csv格式比较方便,所以就是存储csv格式方便提取
三转换的时候爬下来的地址有很多就是不能用,不能转换,但是还有放假信息,所以我就是存储为1000一个特殊值,然后后期处理掉
代码
#coding:utf-8
import urllib2
import csv
import json
import pandas as pd
reader=csv.reader(open(r'D:\MobileFile\fangjia1.csv','r'))
for line in reader:
line1 = line[1].decode('gbk').encode('utf-8')#解码编码
print line1
with open('D:\MobileFile\房价.csv', 'ab+') as csvfile:#打开的时候必须用ab+,别的会有空行或者会出现key值重复的问题
try:
url = 'http://api.map.baidu.com/geocoder?address='+line1+'&output=json&key=f247cdb592eb43ebac6ccd27f796e2d2'
html = urllib2.urlopen(urllib2.Request(url))
json1 = html.read()
print json1
hjson = json.loads(json1) # json格式转换
lng = hjson['result']['location']['lng'] # 经度
lat = hjson['result']['location']['lat'] # 纬度
fieldnames = ["dizhi","jingdu","weidu"]
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
# writer.writeheader()
data = ({'dizhi': line1, 'jingdu': lng, 'weidu': lat})
writer.writerow(data)
except:
lng =10000
lat=10000
fieldnames = ["dizhi", "jingdu", "weidu", ]
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
data1 = ({'dizhi':line1,'jingdu':lng,'weidu':lat})
writer.writerow(data1)
csvfile.close()
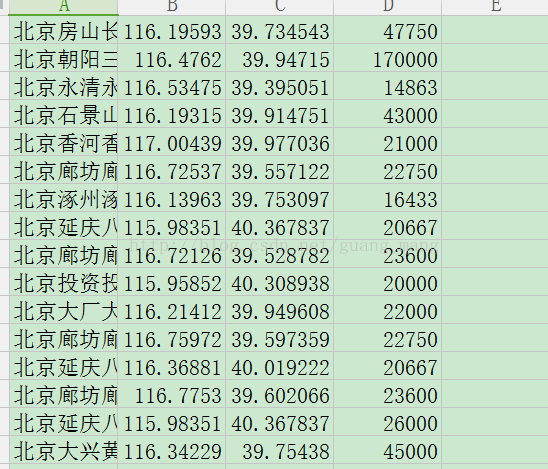
四转换出来的图片














 4217
4217











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









