







介绍
堆叠(也称为元组合)是用于组合来自多个预测模型的信息以生成新模型的模型组合技术。通常,堆叠模型(也称为二级模型)因为它的平滑性和突出每个基本模型在其中执行得最好的能力,并且抹黑其执行不佳的每个基本模型,所以将优于每个单个模型。因此,当基本模型显著不同时,堆叠是最有效的。关于在实践中怎样的堆叠是最常用的,这里我提供一个简单的例子和指导。
首先先边看边总结一下这篇博客的内容:
数据比赛大杀器—-模型融合(stacking&blending)
例子:
假设有四个人在板子上投了187个飞镖。对于其中的150个飞镖,我们可以看到每个是谁投掷的以及飞镖落在了哪。而其余的,我们只能看到飞镖落在了哪里。我们的任务就基于它们的着陆点来猜测谁投掷的每个未标记的飞镖。
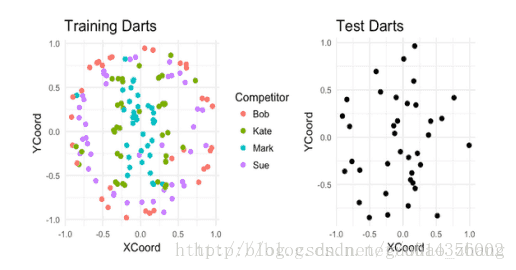
模型
针对这个问题,我们构建两个模型:
一、K最近邻(基本模型1)
一系列调节后,发现K = 1具有最佳的CV性能(67%的准确性)。使用K = 1,我们现在训练整个训练数据集的模型,并对测试数据集进行预测。 最终,这将给我们约70%的分类精度。
二、支持向量机(基本型2)
经过一系列操作之后,在测试数据集上给我们约61%的CV分类精度和78%的分类准确性。
堆叠(元组合)
SVM在分类Bob的投掷和Sue的投掷方面做得很好,
但是在分类Kate的投掷和Mark的投掷方面做得不好。
对于最近邻模型,情况正好相反。
提示:堆叠这些模型可能会卓有成效。
将训练数据分为五个 { fold1, fold2, fold3, fold4, fold5 }
交叉训练
kaggle比赛集成指南
对提交文件的处理:
一、投票集成:
例子:
假设我们的测试集有10个样本,正确的情况应该都是1:
1111111111我们有3个正确率为70%的二分类器记为 A,B,C。你可以将这些分类器视为伪随机数产生器,以70%的概率产生”1”,30%的概率产生”0”。
下面我们会展示这些伪分类器通过投票集成的方法得到78%的正确率。
All three are correct
0.7 * 0.7 * 0.7
= 0.3429
Two are correct
0.7 * 0.7 * 0.3
+ 0.7 * 0.3 * 0.7
+ 0.3 * 0.7 * 0.7
= 0.4409
Two are wrong
0.3 * 0.3 * 0.7
+ 0.3 * 0.7 * 0.3
+ 0.7 * 0.3 * 0.3
= 0.189
All three are wrong
0.3 * 0.3 * 0.3
= 0.027我们看到有44%的概率投票可以校正大部分错误。
大部分投票集成会使最终的准确率变成78%左右:
0.3429 + 0.4409 = 0.7838二、相关性
皮尔逊相关系数
这里作者说到如果模型提交文件是相关的,效果一般,而不相关甚至性能差的模型,集成投票效果会好一点。
三、加权
为什么要加权?通常我们希望模型越好,其权重就越高。
所以,在这里,我们将表现最好的模型的投票看作3票,其它的4个模型只看作1票。
原因是:当表现较差的模型需要否决表现最好的模型时,唯一的办法是它们集体同意另一种选择。我们期望这样的集成能够对表现最好的模型进行一些修正,带来一些小的提高。
Kaggle案例:森林植被类型预测
MODEL PUBLIC ACCURACY SCORE
GradientBoostingMachine 0.65057
RandomForest Gini 0.75107
RandomForest Entropy 0.75222
ExtraTrees Entropy 0.75524
ExtraTrees Gini (Best) 0.75571
Voting Ensemble (Democracy) 0.75337
Voting Ensemble (3*Best vs. Rest) 0.75667Kaggle案例:CIFAR-10 图像检测
Ensembling.训练10个神经网络并平均它们的预测结果,这是一个相当简单的技术,却有相当大的性能改进。
这里可能会有疑惑:为什么平均会有如此大的帮助?这有一个对于平均有效的简单的原因。假设我们有2个错误率70%的分类器,当2者结果一样时,那就是这个结果;当2者发生分歧时,那么如果其中一个分类器总是正确的,那么平均预测结果就会设置更多的权重在那个经常正确的答案上。
这个作用会特别强,whenever the network is confident when it’s right and unconfident when it’s wrong.——Ilya Sutskever在深度学习的简单概述中说道。四、平均
平均可以很好的解决一系列问题(二分类与回归问题)与指标(AUC,误差平方或对数损失)。
与其说平均,不如说采用了多个个体模型预测值的平均。一个在Kaggle中经常听到的词是“bagging submissions”。
平均预测常常会降低过拟合。在类与类间,你想要理想的平滑的将其分离,而单一模型的预测在边界间可能会有一些粗糙。
Stacked Generalization & Blending
这篇博客中博主简单提到了一些:
- Stacking with non-linear algorithms
目前流行用于Stacking的非线性算法有GBM,KNN,NN,RF和ET。
非线性的Stacking在多分类任务中,使用原始特征就能产生令人惊讶的提升。显然,在第一阶段中的预测提供了非常丰富的信息并得到了最高的特征重要性。非线性算法有效地找到了原始特征与元模型特征之间的关系。 - Feature weighted linear stackingt
线性加权stacking就是,先将提取后的特征用各个模型进行预测,然后使用一个线性的模型去学习出哪个个模型对于某些样本来说是最优的,通过将各个模型的预测结果加权求和完成。使用线性的算法可以非常简单快捷地去验证你的模型,因为你可以清楚地看到每个模型所分配的权重。
[突然得看些其他资料,过会再来总结这些]
【待续……】














 229
229











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









