







YOLO v1
@(目标检测)
论文地址:https://arxiv.org/abs/1506.02640
网络结构
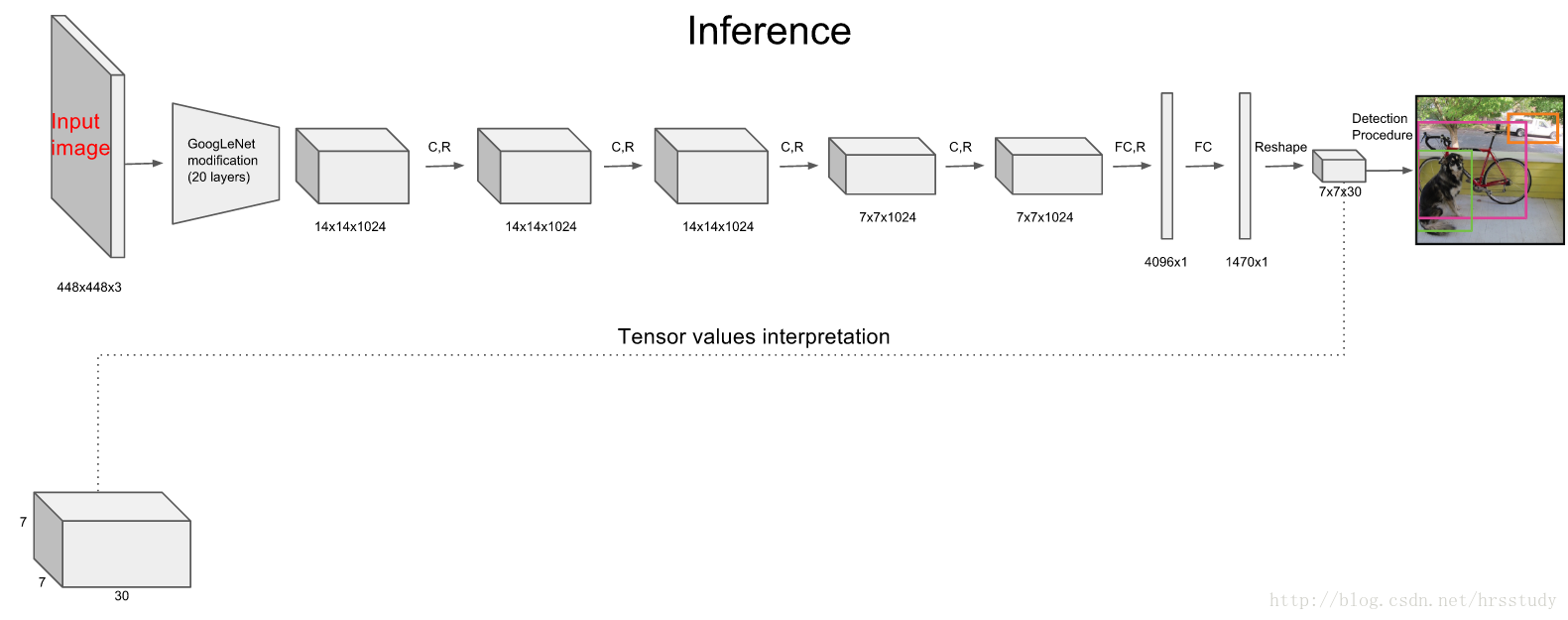

Yolo网络由24个卷积层和2层全连接层构成,其中,卷积层用来提取图像特征,全连接层用来预测图像位置和类别概率值。全连接层之后,会将原来的一维的tensor resize成SxSx(Bx5+C)的三维tensor。
YOLO网络借鉴了GoogLeNet分类网络结构。不同的是,YOLO未使用inception
[1]
[
1
]
,而是使用1x1卷积层(此处1x1卷积层的存在是为了跨通道信息整合)+3x3卷积层简单替代。
module
YOLO将输入图像分成SxS个grid,每个grid负责检测”落入”该grid的物体(“落入”,或者“包含”,其含义是指物体的中心坐标在这个grid里面)。若某个物体的中心位置的坐标落入到某个grid,那么这个grid就负责检测出这个物体。

图中物体狗的中心点(红色原点)落入第5行、第2列的grid内,所以这个grid负责预测图像中的物体狗。
每个grid输出B个bounding box(包含物体的矩形区域)信息,以及C个物体属于某种类别的概率信息。

bounding box包含:x, y, w, h, confidence
x,y: 当前所预测的bounding box中心位置的坐标(Train中则为预测的bounding box的中心与栅格边界的相对值)
w,h: 当前所预测的bounding box的宽度和高度(Train中则为预测的bounding box的w,h相对于整幅图像w,h的比例)
confidence: P(obj) * IoU [2] [ 2 ] ,P(obj)表示所预测的bounding box包含物体的概率,若包含,则P(obj)=1,反之P(obj)=0。
C个物体属于某种类别的概率信息:P(class)/P(obj), VOC数据集C=20。
在B个bounding box中,对于每一个bounding box,其具体类别的 confidence score=P(class)/P(obj)∗confidence=P(class)∗IoU c o n f i d e n c e s c o r e = P ( c l a s s ) / P ( o b j ) ∗ c o n f i d e n c e = P ( c l a s s ) ∗ I o U
Loss
YOLO的loss构成比较复杂,分为三个部分,并且对于每个部分,YOLO考虑了该部分的贡献程度,所以还加上了各种权重系数
λ
λ
。
第一部分是计算关于检测框坐标的loss














 314
314











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









