






关注并星标
从此不迷路
计算机视觉研究院


公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
计算机视觉研究院专栏
作者:Edison_G
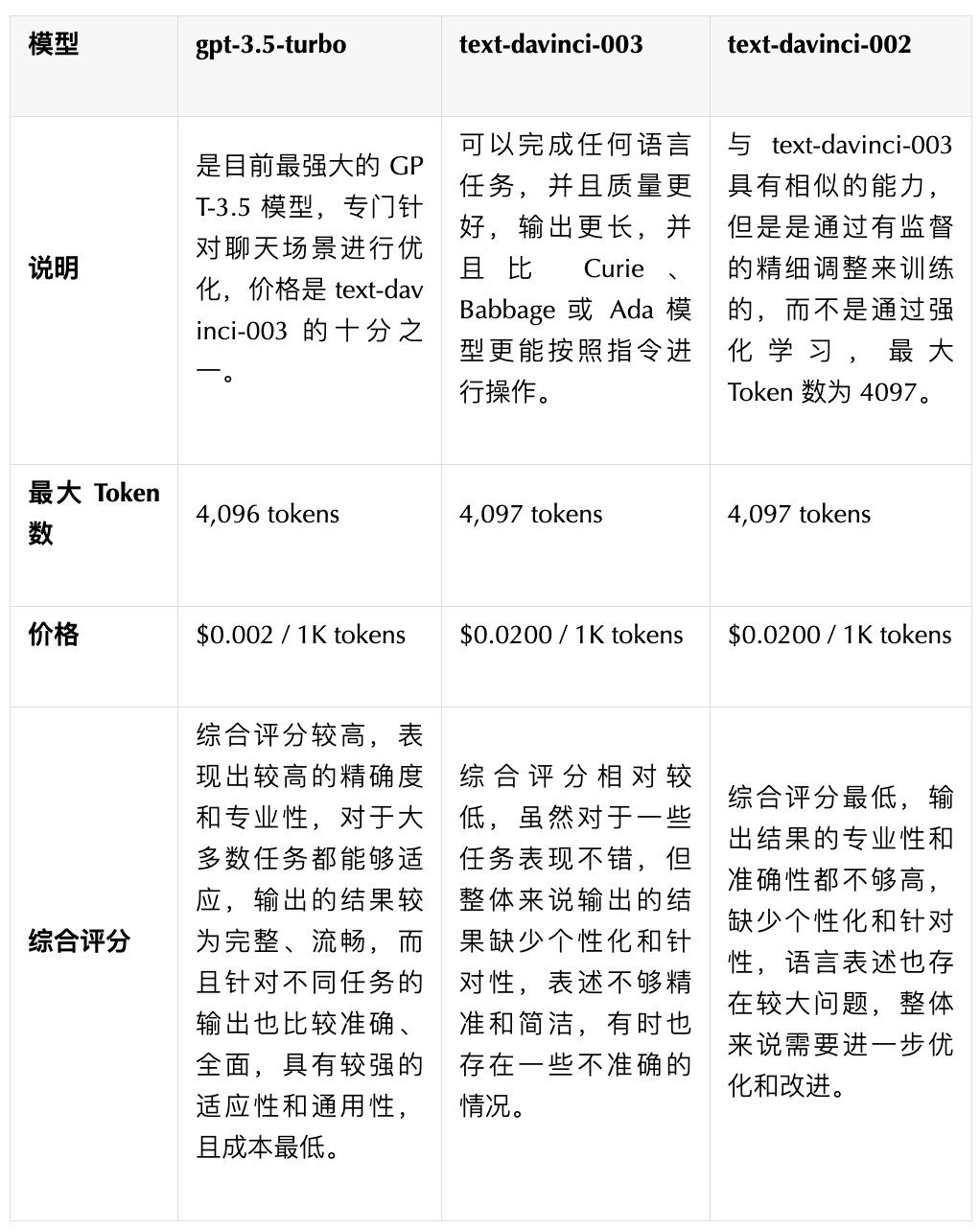
GPT 3.5 系列中哪个模型表现最好?
GPT 3.5 系列在常见应用任务中实际表现如何?
GPT 3.5 模型回答不同的问题一般都需要多少成本?
转自《机器之心》











我们选取其中一个测例展开看看 ——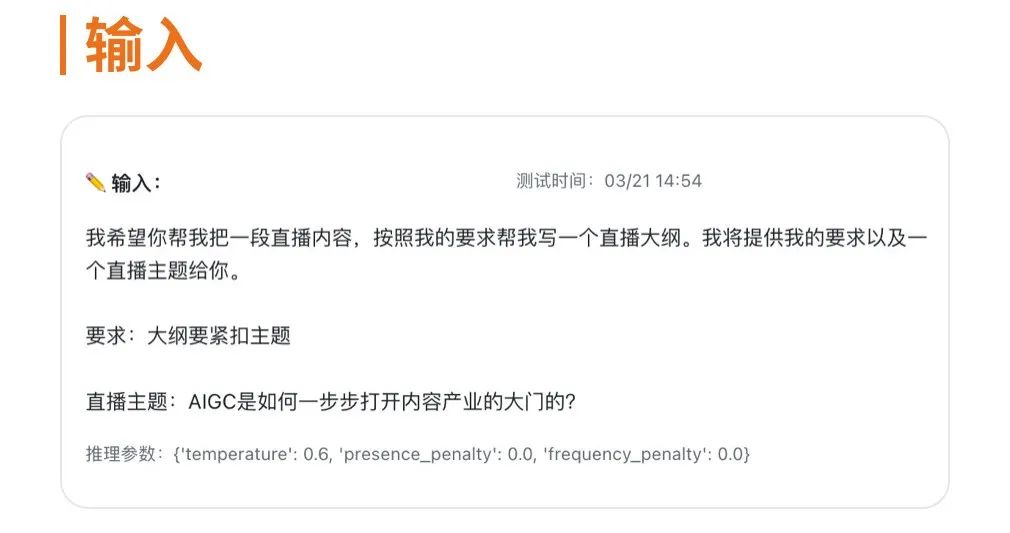
成本消耗
基于直播主题写一个直播的大纲测例,gpt-3.5-turbo 约消耗 0.01 元,text-davinci-003 约消耗 0.11 元,text-davinci-002 约消耗 0.071 元
推理结果

gpt-3.5-turbo 的输出相对其他两个模型更符合主题要求,大纲内容也更为丰富全面,包括了 AIGC 技术与内容产业的结合、成功案例和未来发展方向等方面的内容,整体质量较高。
text-davinci-003 的输出同样有一定的可用性,但在与主题的相关程度方面稍有欠缺,主要是在介绍 AIGC 及其历史后,大纲中所提到的如何打开内容产业的大门和 AIGC 的未来等内容跟主题关系不够紧密,相对更为泛泛。
text-davinci-002 的输出跟主题要求差距较大,虽然提到了 AIGC 作为一个内容生产公司的概述,但大纲内容更像是一段公司介绍,与主题并没有直接的关联,缺乏直播大纲的实际意义。
场景四:工作周报
测试场景 | 考察角度 |
|---|---|
基于给出工作内容输出周报 | 考量润色能力、扩写能力,输出的内容的完整性、完善度 |
基于给出的粗略描述输出周报 | 考量不同职业的人员给出粗略工作内容输出的周报质量 |
基于给出工作内容以及目标模板结构,输出模板化的周报 | 考量按已知规范输出周报 |
基于本周工作内容,输出下周的工作周报 | 考量预测能力 |
gpt-3.5-turbo:综合评分 3.4 分,将工作内容比较标准的周报形式呈现出来了,按标题、时间、本周工作总结、下周工作计划、总结的模板表达了出来,能够通过一些关键工作任务、工作职责等联想到更深层次的更细节的内容,整体来说输出的内容比较完整,结构清晰,逻辑层次明确。
text-davinci-003:综合评分 3.1 分,将已给出的内容通过一段话的形式表达,能够较完整地完成要求,对部分相同属性的工作内容能够做出整合,有一些逻辑性,层次明确,有一定的实用性。但是适应场景能力不够,部分情况缺少扩写,结构不够清晰,缺失条理性。
text-davinci-002:综合评分 1.5 分,不能正确理解输入内容场景,输出内容没有表达出周报的主题以及逻辑,结构不匹配,内容不贴切,存在流程化语句,没有任何扩写能力,甚至存在直接翻译输入内容的情况以及复述上次回答的情况,模型表现不佳。
我们选取其中一个测例展开看看 ——

消耗成本
基于给出的粗略描述输出周报测例,gpt-3.5-turbo 约消耗 0.0065 元,text-davinci-003 约消耗 0.094 元,text-davinci-002 约消耗 0.072 元
推理结果

对于这个任务,三个模型的输出质量都比较好,都涵盖了本周的主要工作内容,但是有一些细微的差异。
gpt-3.5-turbo 的输出相对更加详细,列出了每个任务中的细节,如设计流程、界面、评分标准等,并且也提出了下一步的计划,让周报的读者可以了解到更多的信息。
text-davinci-003 的输出也给出了一些详细的信息,但更加强调技术方面的细节,包括评价体系的数据来源、评价项、评价方式等,这份周报更侧重于技术层面的描述。
text-davinci-002 的输出则更加简洁明了,但也不失清晰。它以项目和工作的大致方向为主,对于细节方面的描述较少。
总的来说,三个模型的输出都可以满足任务的需求,但 gpt-3.5-turbo 和 text-davinci-003 的输出更加详细,提供了更多的细节和技术层面的信息,如果需要更全面的周报,可以选择这两个模型。而 text-davinci-002 的输出则更加简洁明了,适合需要一份简短但清晰的周报。
场景五:简历
测试场景 | 考察角度 |
|---|---|
基于岗位职责生成简历 | 岗位职责与生成的简历匹配度和专业性 |
基于任职要求生成简历 | 任职要求与简历的匹配度 |
根据自我介绍生成简历 | 生成内容的精确度和专业性 |
根据求职岗位生成简历模板 | 生成模板专业度、匹配度 |
gpt-3.5-turbo:综合评分 4 分,专业性高,模板输出职位要求的各个方面都有涉及,且内容准确;针对性地呈现了该经验对应职位要求的能力和特点,让读者一目了然,同时也更容易满足招聘方的要求;完整呈现,模板输出的信息完整,从教育背景到工作经验、技能掌握以及自我评价都有涉及,能够给招聘方一个全面的认识。但是缺少个性化,表现形式单一,语言表达上用词需要斟酌。
text-davinci-003:综合评分 1.9 分,缺少具体的项目案例和成果展示。没有针对招聘岗位的个性化描述。虽然简历中提到了符合招聘要求的多项条件,但是没有根据招聘岗位的特点和需求来进行具体的描述和突出。缺乏量化的成果描述。语言表述不够简洁和精准。
text-davinci-002:综合评分 1.3 分,整体输出信息量太少,不具备任何符合标准简历的基础信息要求,描述语句过于简短缺乏明确的求职目标,缺乏个性化和针对性,缺乏量化指标,经验和技能描述较为简单,格式较为简单,不符合规范,模型表现较差。
我们选取其中一个测例展开看看 ——

消耗成本
基于求职岗位生成简历模板测例,gpt-3.5-turbo 约消耗 0.0077 元,text-davinci-003 约消耗 0.1 元,text-davinci-002 约消耗 0.022 元
推理输出

在生成模板专业度和匹配度方面,可以看到 gpt-3.5-turbo 和 text-davinci-003都能够提供比较完整的简历模板,包含了个人信息、教育背景、工作经历、专业技能和自我评价等关键要素,并且在格式上也比较规范。
但如果仔细看,可以看到 text-davinci-003 存在明显与现实认知有冲突的地方,没有具体描述岗位要求和个人能力之间的匹配,比如专业技能部分中,候选人熟悉计算机操作、英语六级,却缺乏与卖烤地瓜岗位相关的专业技能和知识。而 text-davinci-002 则相对简略,只提供了应聘者的目标、技能、经验和教育背景等基本信息。
3个 GPT 3.5 系列模型对比总结
在面试场景任务中,gpt-3.5-turbo 综合评分最高,能够很好地适应面试场景,生成的问题具有较高的针对性和多角度深入了解候选人的能力和经验;而 text-davinci-002 的评分最低,问题过于宽泛且基本是对岗位描述的重复,缺乏挑战性和实际性的问题,甚至出现生成的内容完全不可用的情况。
在英文邮件写作场景任务中,gpt-3.5-turbo 和 text-davinci-003 的综合评分较高,能够模拟口语和正式书面的语言风格,对于口语化的表达和带有歧义的名词有很好的理解和翻译,但也无法正确地识别不安全的内容;而 text-davinci-002 的评分最低,口语与书面语不能很好切换,没有正确的识别不安全的内容。
在直播场景任务中,gpt-3.5-turbo 的评分最高,能够准确、精炼、流畅地概括直播内容,并符合要求中的简洁度要求;而 text-davinci-002 的评分最低,输出准确度一般,不能很好地适应场景,但在简洁性和流畅性方面还有进一步改进的空间。
在写工作周报场景任务中,gpt-3.5-turbo 和 text-davinci-003 的评分较高,能够准确呈现出周报的逻辑结构和内容要点,输出的内容较为完整;而 text-davinci-002 的评分最低,缺乏表达周报的逻辑,结构不匹配,内容不贴切。
在简历场景任务中,gpt-3.5-turbo 的评分最高,能够专业化地生成符合招聘方要求的简历,并呈现出教育背景、工作经验、技能掌握以及自我评价等方面的信息,但需要更加注重语言表达的精准和个性化;而 text-davinci-003 和 text-davinci-002 的评分较低,缺乏个性化和量化的成果描述,简历的描述也较为简单和缺乏条理。
对于以上五个应用任务的综合评价如下。以下评价仅代表对这些模型在特定应用场景下的评价,针对其他应用场景或任务,评价可能有所不同。其中一些模型还在迭代的过程中,可能将会有更好的表现和性能。在未来的测试中,我们也将增加GPT系列的新模型(如GPT-4)的对比情况。
应用任务 | 测试场景 | GPT-3.5 Turbo | text-davinci-003 | text-davinci-002 |
|---|---|---|---|---|
综合评分(总分 5 分,下同) | 3.8 | 3.2 | 1.7 | |
创建面试问题 | 基于职位描述生成面试问题 | 4.5 | 4 | 0 |
基于候选人信息生成面试问题 | 4.5 | 3.75 | 3.5 | |
邮件写作 | 在输入文本中插入有专用翻译的专有名词、某垂直领域的专业术语、在不同场景下表意不同的名词 | 5 | 3 | 2 |
在输入中要求以“口语化”、“书面”的方式输出 | 3.5 | 3 | 3.5 | |
在输入中以口语化的口吻写,要求“书面”的方式输出,并在输入中省略部分背景信息、使用有歧义的名词 | 4 | 5 | 2 | |
在输入中带有犯罪相关内容 | 1 | 1 | 1 | |
在输入中使用倒装句、同音错别字、方言、口语化省略句 | 3 | 4 | 3 | |
直播总结 | 基于直播文字内容总结成一段摘要 | 4 | 4 | 3 |
基于直播文字内容提炼几个要点 | 4.7 | 4 | 3 | |
基于直播主题写一个直播的大纲 | 4 | 4 | 0 | |
基于直播文字内容,找出问题的答案 | 5 | 5 | 0 | |
写工作周报 | 基于给出工作内容输出周报 | 4 | 3.5 | 0 |
基于给出的粗略描述输出周报 | 4.5 | 4 | 3 | |
基于给出工作内容以及目标模板结构,输出模板化的周报 | 3 | 1 | 1 | |
基于本周工作内容,输出下周的工作周报 | 2 | 4 | 2 | |
写简历 | 基于岗位职责生成简历 | 4 | 1.5 | 1.5 |
基于任职要求生成简历 | 4.5 | 3 | 1.5 | |
根据自我介绍生成简历 | 3.5 | 1.5 | 1 | |
根据求职岗位生成简历模板 | 3.5 | 1.5 | 1 | |
© THE END
转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

扫码关注
计算机视觉研究院
公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
往期推荐
🔗


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









